This is no longer the main repository for the QualtricsTools project. Check out the continued work on this project in the emmamorgan-tufts/QualtricsTools repository.
QualtricsTools is an R package that automatically processes Qualtrics survey data into reports breaking down the responses to each question. The package creates reports that summarize the results of closed-ended questions, compiles appendices of open-ended text responses, and generates question dictionaries that describe the details of each survey question. It also can generate reports for subsets of respondents based on their response data. This package uses the R web-application framework Shiny, the universal document converter Pandoc, Roxygen2 documentation, and much more.
This package was developed for Tufts University's Office of Institutional Research and Evaluation. Anyone is welcome to use it.
Before installing, you must install R or Rstudio,
devtools,
Rtools (if you're on Windows),
and Pandoc. For Rtools with Windows,
please make sure Rtools is added to the Path environment variable. You need to install.packages('devtools') or have already installed the devtools package in R. After installing each of the prerequisites, to install QualtricsTools run the following in R:
devtools::install_github("ctesta01/QualtricsTools")
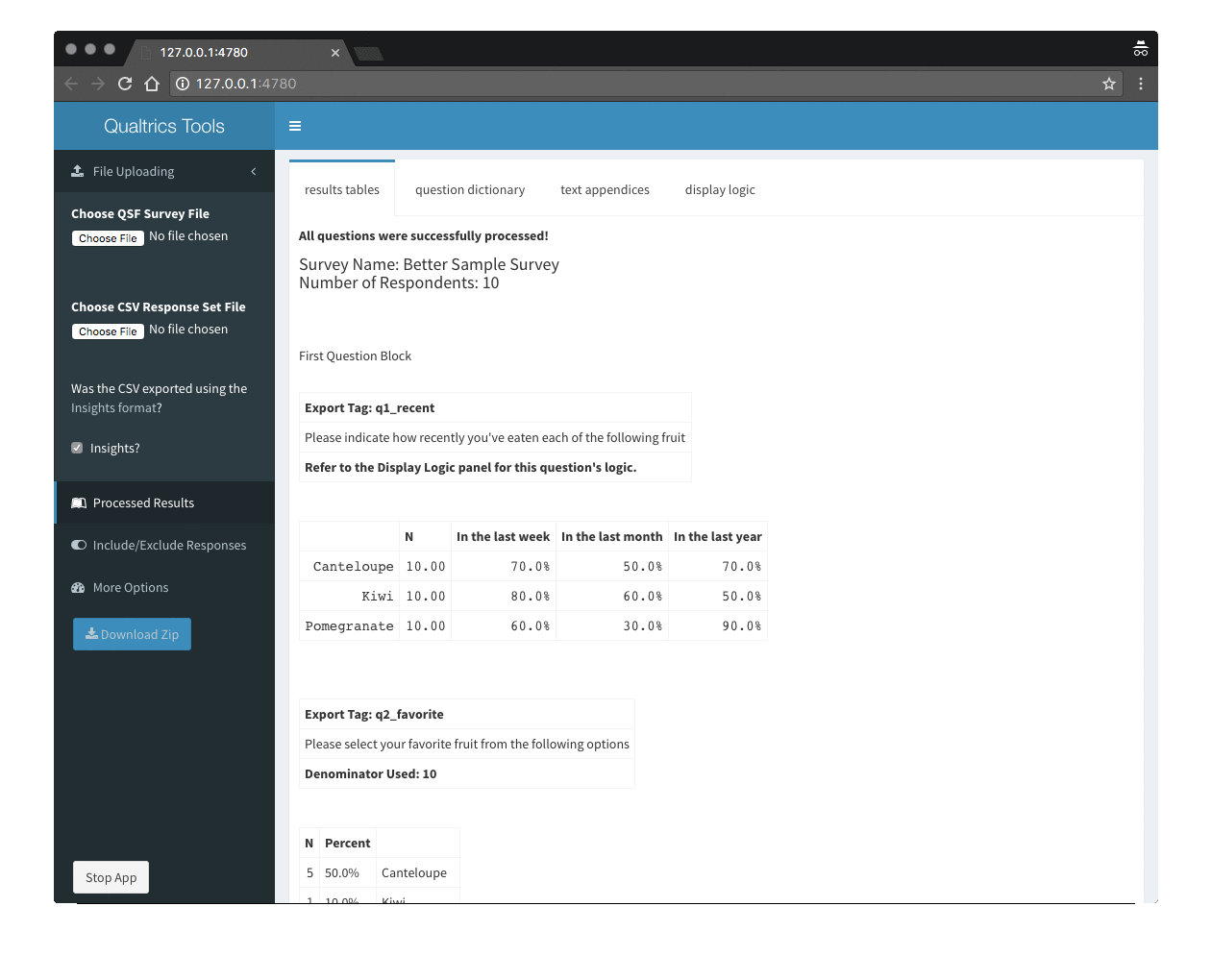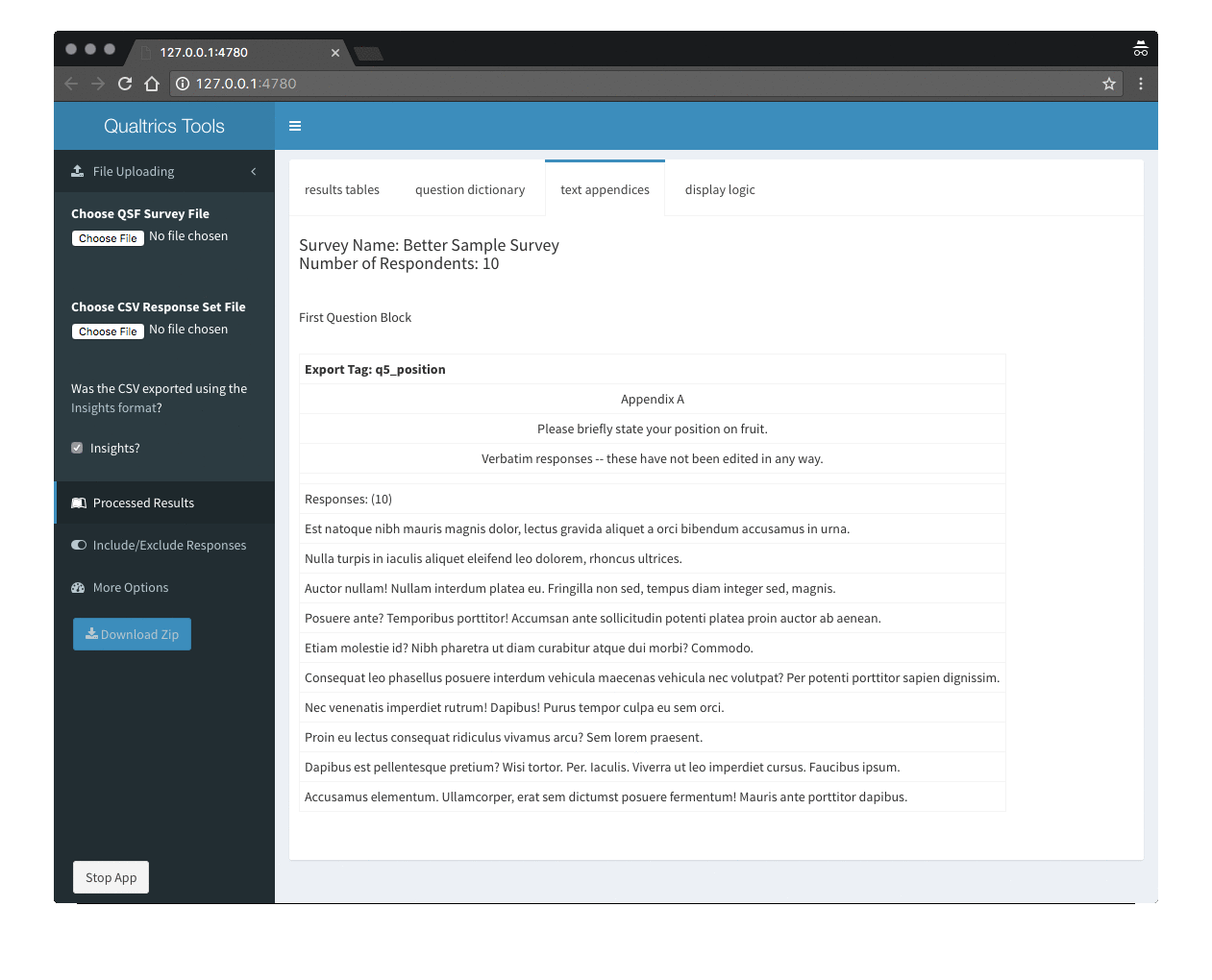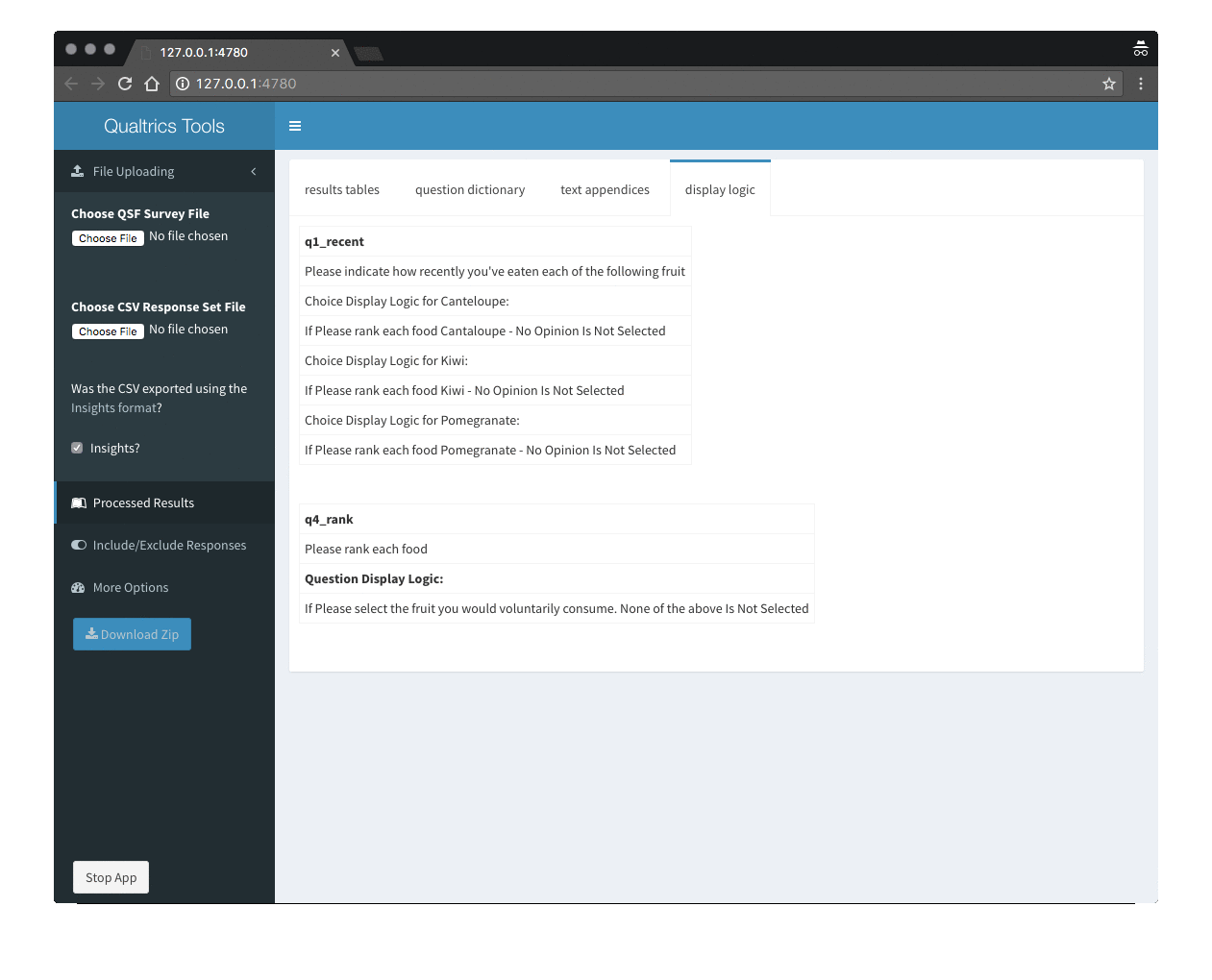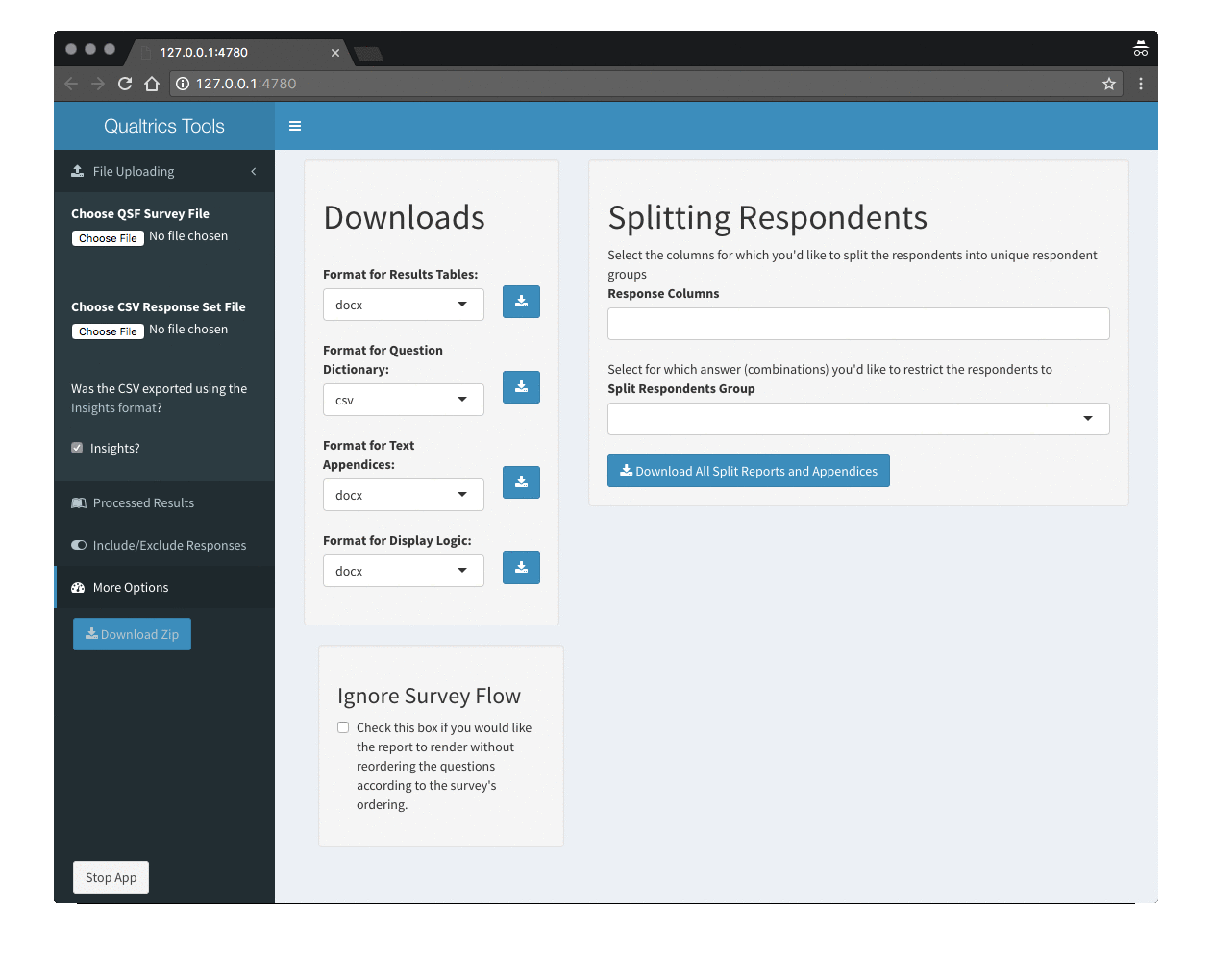
The QualtricsTools package includes a suite of functions to help you analyze Qualtrics data in R. Most of the package can be used on the command line in R. However, the simplest way to create basic reports of your Qualtrics data is to use the QualtricsTools Shiny app. The app includes an interactive user-friendly interface that lets you select your survey and data file, and generate reports (frequencies for closed-ended questions and compiled text responses for open-ended questions) for the entire respondent group and/or subgroups.
To run the Shiny app, load the package and then call the app() function.
library(QualtricsTools)
app()
The QualtricsTools Shiny app should now be running! Enjoy. To update your version of QualtricsTools
to the most recent version, run devtools::install_github("ctesta01/QualtricsTools") again.
Here are some of the most high level functions in the application. Be sure to library(QualtricsTools) before
trying to run any of these. Each function takes a series of parameters (e.g. survey .qsf file, response .csv file, output directory). Running these
commands without parameters as shown in the code below results in interactive prompts for the survey data and other settings
in order to cut down on the need to repeatedly type or copy long file paths.
For more details about each of these functions and their arguments, check out their documentation: get_setup, make_results_tables, and make_text_appendices.
# Load and Process Survey Data into R
get_setup()
# Start and run the Shiny app
app()
# Create a Report of Question Results Tables
make_results_tables()
# Create a Report of Text Appendices, for each free response part of the survey
make_text_appendices()
The functionality of the web application and R package are documented in the following guides. Beyond this,
almost all functions have Roxygen generated documentation which means that after running library(QualtricsTools)
you can run help(function) or ?function on any function in QualtricsTools to check out the Roxygen2 generated
documentation.
- How do I use the app?
- How do I use the R package?
- Generating Results Tables
- Generating Question Dictionaries
- Generating the Unprocessed Questions Dictionary
- Generating Text Appendices
- Generating Survey Logic
- Generating Split Reports by Responses
- Reshaping for Tableau
- Inserting Coded Comments into Text Appendices
- Including/Excluding Questions from Reports
- Processing a Specific Question
- Using Pandoc to Export to Different Filetypes
- How does it work? (Reference)
Check out our FAQ for more help.


























