cripac-dig / sr-gnn Goto Github PK
View Code? Open in Web Editor NEW[AAAI 2019] Source code and datasets for "Session-based Recommendation with Graph Neural Networks"
[AAAI 2019] Source code and datasets for "Session-based Recommendation with Graph Neural Networks"
The paper states that a small number of training steps is suggested because most sessions are of relatively short lengths. It seems that the length of recrueent layer equals to the number of sessions. Is my understanding wrong, or is this a typo in the paper?

I tried to do experiments on the Diginetica dataset with the Tensorflow code, but I don't know why the P@20 can only reach 49.8. However, P@20 in PyTorch code can achieve the same performance as the paper, 50.7, and the hyperparameters and model look the same as Tensorflow. I am confused and hope to find a solution. Thank you very much.
When i run the yoochoose1_4 experiment, it run out of 32GB RAM, how much RAM is needed to run it?
作者您好,非常感谢您的开源,有个问题想请教一下:
对于tensorflow 的代码,我在diginetica数据集上做了两个实验:
Thanks for make your code public.
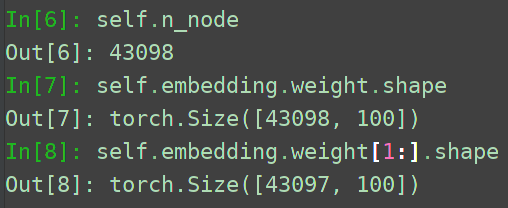
I have been wondering why b = self.embedding.weight[1:] in model.py rather than b = self.embedding.weight[:] ?
根据我的理解,如果每批的大小是batch_size最终定的节点数是max_n_node的话,则送到GNN中的A应该是(batch_size,max_n_node,max_n_node*2)的size,而那个GNNCell代码中第一行的地方matmul的是(batch_size,max_n_node,max_n_node)和(hidden_size,hidden_size)的LinearLayer,这就很困惑了,max_n_node和hidden_size不一样的时候咋办。请问我的理解是否有误。。。
In the paper it is mentioned that the softmax function is being applied to the outputs after computing scores for each candidate item (equation 9), however, the PyTroch Implemention (compute_scores method) doesn't seem to be doing that. Is there a reason why it isn't used?
I have tested the model with the softmax function (default hyperparameters), and the evaulation metrics peformance has drastically decreased. I suspect if it has anything to do with the low output values after softmax. Any thoughts on this?
作者您好:
感谢您的工作,我对数据集的预处理有一些疑问:
在Yoochoose数据集中,模型需要截取最近1/64和1/47以方便实验。在对session排序的时候,是依据一个session中最后一次点击的时间还是最开始点击的时间进行排序?我从代码中理解,是否只是取了读入数据的最后一个时间,而没有对session内部先进行排序?
谢谢!
If it is not convenient to use Chinese, I can restate my question in English. Thank you very much
The naming of variables in the GNNCell is a little bit frustrating such as there no inputgate in the origin paper. And the computation of the final hidden vectors is different from the origin paper.
In the paper, Eq(5) is like

While in the code,
hy = newgate + inputgate * (hidden - newgate)
newgate stands for Eq(4) according to this line of code. hidden stands for the hidden vector representation of the former layers. And the inputgate stands for the z in Eq(5). It seems that code and paper are not matched.
In the computation code of softmax along all items, why is the 0th embedding left out? After leaving out this embedding, the shape is no longer [n_nodes, latent_size] but [n_nodes - 1, latent_size].
Running python preprocess.py --dataset=yoochoose assumes a CSV header, which is not available in the standard yoochoose-clicks.dat downloaded from the source in the README. The assumed formatting of the timestamp data is also not correct.
We processed data as you mentioned and the number of train and test sessions are matched.
with open('../yoochoose1_64/train.txt','rb')as f:
train=cPickle.load(f)
print("len of train",len(train[0]))
with open('../yoochoose1_64/test.txt','rb')as f:
test=cPickle.load(f)
print("len of test",len(test[0]))
len of train 369859
len of test 55898
But, you reported that count of all items in yoochoose1/64 data as 16766. We are getting a different number. Same problem with Yoocooose1/4 data also. Please find our code.
#train sequences and labels
train_seq=train[0]
train_y=train[1]
#test sequences and labels
test_seq=test[0]
test_y=test[1]
# find unique items in the train sequences
full_train = [j for sub in train_seq for j in sub]
print("count of items ",len(set(full_train)))
`count of items16373`
Can you please mention the code to find count of items?
GPU使用率均值只有10%不到,感觉是构建图的过程占用cpu时间过长,如何改呢
Hi,
In your paper, the experiment result of Diginetica is

but in Stamp paper, their result is

We can see the values in Diginetica are different.So please tell me why.Thanks.

Does anyone have such problem? And how to solve it?
Line 41 in 201f5d8
sessid = data['session_id']
if curdate and not curid == sessid: could be replaced by
sessid = data['session_id']
curdate = ''
curdate = data['eventdate']
if curid>0 and not curid == sessid:
Tensorflow code/model.py line no. 46
ma = tf.concat([tf.reduce_sum(tf.reshape(coef, [self.batch_size, -1, 1]) * seq_h, 1), tf.reshape(last, [-1, self.out_size])], -1)
I think 'last' should be 'last_h' in above line, as in code:
last_h = tf.gather_nd(re_embedding, tf.stack([tf.range(self.batch_size), last_id], axis=1))
last = tf.matmul(last_h, self.nasr_w1)
According to paper Sg should be concatenate with last item embedding.
Please clarify.
I have used PyTorch_Geometric package to reimplement SR-GNN in this repo and achieve some similar results to your origin paper.
Would you mind if you can help add a link to my reimplementation?
In the paper, it reported that the performance of POP in yoochoose1_64 is 6.71 (P@20). However, when I reimplement POP, I got different result 7.36. Could you open the source code and the parameter setting of baselines?
In the paper, it's reported that yoochoose 1/64 and 1/4 have 16,766 and 29,618 items respectively. However, using preprocess.py to process data results in 17,377 and 30,444 items respectively. Where are the missing items?
Could you please explain the format of data written to the files.
train.txt, test.txt and all_train_seq.txt.
And what are yoochoose1_4 and yoochoose1_64 files (importance of 4 and 64)?
In your paper, it's mentioned that the graph is constructed by all the session.
In https://arxiv.org/pdf/1811.00855.pdf, page 6 the first paragraph under subtitle Comparison with Variants of Connection Schemes
Firstly, we aggregate all session sequences together and model them as a directed whole item graph, which is termed as the global graph hereafter.
But in your code, both your tensorflow and pytorch version, your code comment the build_graph function and model each session sequence as one small directed graph.
Hi,
Thank you for sharing your code.
I have a question about the data preprocessing for Yoochoose dataset. In the code, you first split the train-test sets based on time, and make sure there is no item in test set that does not appear in training set, then you use the current training data to get most recent 1/4 and 1/64 sessions to be the final training set. By this, the final test set still has items that do not appear in the training set. Is that a problem?
请问能够给我发一下DIGINETICA数据集的数据集吗,我实在是没找到。最近才开始着方面的研究,十分感谢。邮箱:[email protected]
代码里面n_node是怎么得到的,是人为设定的还是算出来的?
In ggnn function, the input shape of dynamic_rnn will be (self.batch_size * max_n_node, 1, 2 * hidden_size) = (# of all items in a batch, 1, 2 * hidden_size) and initial states' shape will be (self.batch_size * max_n_node, hidden_size) = (# of all items in a batch, hidden_size).
So there's only one time step for each sequence (the second element max_time in inputs = 1), which mean the first item vector in inputs (shape = (2 * hidden_size,)) will get the embedding after interacting with the first initial hidden state (shape = ( hidden_size,)) in only one time step. And for the second item vector in inputs will also get it's embedding with the second initial hidden state in one time step. Is that right ? If so, then there is no recurrent meaning in this RNN ?
Cause in my understanding, item should be fed into RNN time step by time step for a session, which means the hidden state (embedding) will be affected by the previous click item. I wonder why the inputs shape is (# of all items in a batch, 1, 2 * hidden_size) instead of (self.batch_size, max_n_node, 2 * hidden_size). What is the meaning of this setting in dynamic_rnn function ?
hi,dear
paper中的连接矩阵是指左边的吗?还是说全部啊,右边的部分没看懂啊?咋理解啊?
多谢


For diginetica, I run it sucessfully, but for yoochoose, I can't.In yoochoose-clicks.dat, there are no titles like "item_id", "Session_id", so I want to know how to revise it.Thank you.
u_sum_in = np.sum(u_A, 0)
u_sum_in[np.where(u_sum_in == 0)] = 1
u_A_in = np.divide(u_A, u_sum_in)
u_sum_out = np.sum(u_A, 1)
u_sum_out[np.where(u_sum_out == 0)] = 1
u_A_out = np.divide(u_A.transpose(), u_sum_out)
It seems we should add a transpose for u_A_in and u_A_out for normalization. Does it matter?
great code thanks
I try to learn it
but this link for data is broken
can you share data please ?
In original paper the last rule of update node vector is:
https://github.com/CRIPAC-DIG/SR-GNN/blob/90123c88850eec8c574518fee6e46aefb42acb94/pytorch_code/model.py#L45-L47
Code's rule is:
Is it mistake in paper or in code?
作者您好,非常感谢您的开源,请教两个问题:
What's the purpose of 'GAT' in utils.py in tensorflow code?
Did you provide the version that contains GAT before?
Please check Figure 4 in the STAMP paper.
The data reported in Table 3 in your paper is quite different with the data reported in Figure 4 even with the same experimental settings. To be specific, in Table 3, the P@20 of STAMP on Diginetica is 47.26 and 40.39 for short sessions and long sessions respectively. However, the data reported in Figure 4 is around 61 and 65 respectively. STAMP actually performs better with long seesions on Diginetica. Why the big difference between your experiments and Qiao Liu's?
Hi,
In your model's loss calculation, you feed the labels in but take 1 away from them:
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.tar - 1, logits=logits))
Why is that?
你好,想请教一下,你们的论文中数据集统计的那张表of clicks是怎么统计的呢,我这边按照你们的数据处理方法,统计列表中除了of clicks外基本都对的上,只有of clicks,差距较大,特别是Yoochoose 1/4的of clicks,训练集+测试及合在一起的clicks也只有7911599条
Line 95 in 90123c8
你好,我想问问为什么这一行的代码不是 u_A[u][v] += 1 ?
Hi, I found that in your 'preprocess.py' file, you just sorted the diginetica dataset by eventdate (%Y-%m-%d), I got a little confused because if you don't sort it by timeframe, in each session those item click stream is still out of order?
在Diginetica数据集上的实验结果,在论文里和论文解析的blog里不一样,请问这是怎么回事呢?我跑代码的结果也没有达到论文里的结果。
hi,dear
能不能用1.14版本的tf啊?结果一致吗?
多谢
I have visited the original paper.But I find confusion in this code where GNN Class is implemented.Are you make it along with the original paper?In original paper,it users Gated Graph Neural Network.Do you do it in a common GNN style?
感谢提供基于session的图网络的推荐想法!我在复现代码的过程中,对于tensorflow_code文件下的model.py中ggn定义有点疑问,如果self.step>1,当i=0时,经过tf.nn.dynamic_rnn输出的fin_state的shape:(batch_size, out_size), 而当i = 1时, self.adj_in的shape: (batch_size, max_uniq_len, max_uniq_len).对于tf.matmul(self.adj_in, fin_state_in), 按照shape来看,(batch_size, max_uniq_len, max_uniq_len) * (batch_size, 1, out_size)根本无法矩阵运算,麻烦解答~多谢!
看论文的model overview,用于训练和预测的应该是经过了GNN之后得到的item embedding,但是代码里是用的第0层的item embedding?作者求解释一下?
I see that you have revised the results of the experiment in the latest version. The reason is that the user clicks within every user session in the DIGENTICA dataset are still out of order. But actually user clicks within every user session in the DIGENTICA dataset is ordered, the timeframe is the time spent on browsing.
Please see the train-item-views.csv file. The data in timeframe column is in range(1,000, 2,000,000). It's not possible to say click time because if the dataset use the Unix timestamp, the range for a day should be (0,86,400), otherwise it should be (0,86,400,000).
And if the order after changing is correct, why do the results of all the experiments go down?
Thanks for sharing this awesome project! I want to know where this small dataset 'sample' with 310 nodes comes from? Is it a subset from yoochoose or diginetica, or is just generated manually?

作者您好,关于这段代码每次输入的hidden,它的shape是batch_sizeseq_lengthlatent_size。这里的seq_length应该是会话序列中的最大长度吧?我不知道理解的对不对。也就是说,您把长度不一的序列都进行了处理对吗?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
