
CDEvents is a common specification for Continuous Delivery events, enabling interoperability in the complete software production ecosystem.
It's an incubated project at the Continuous Delivery Foundation (CDF).
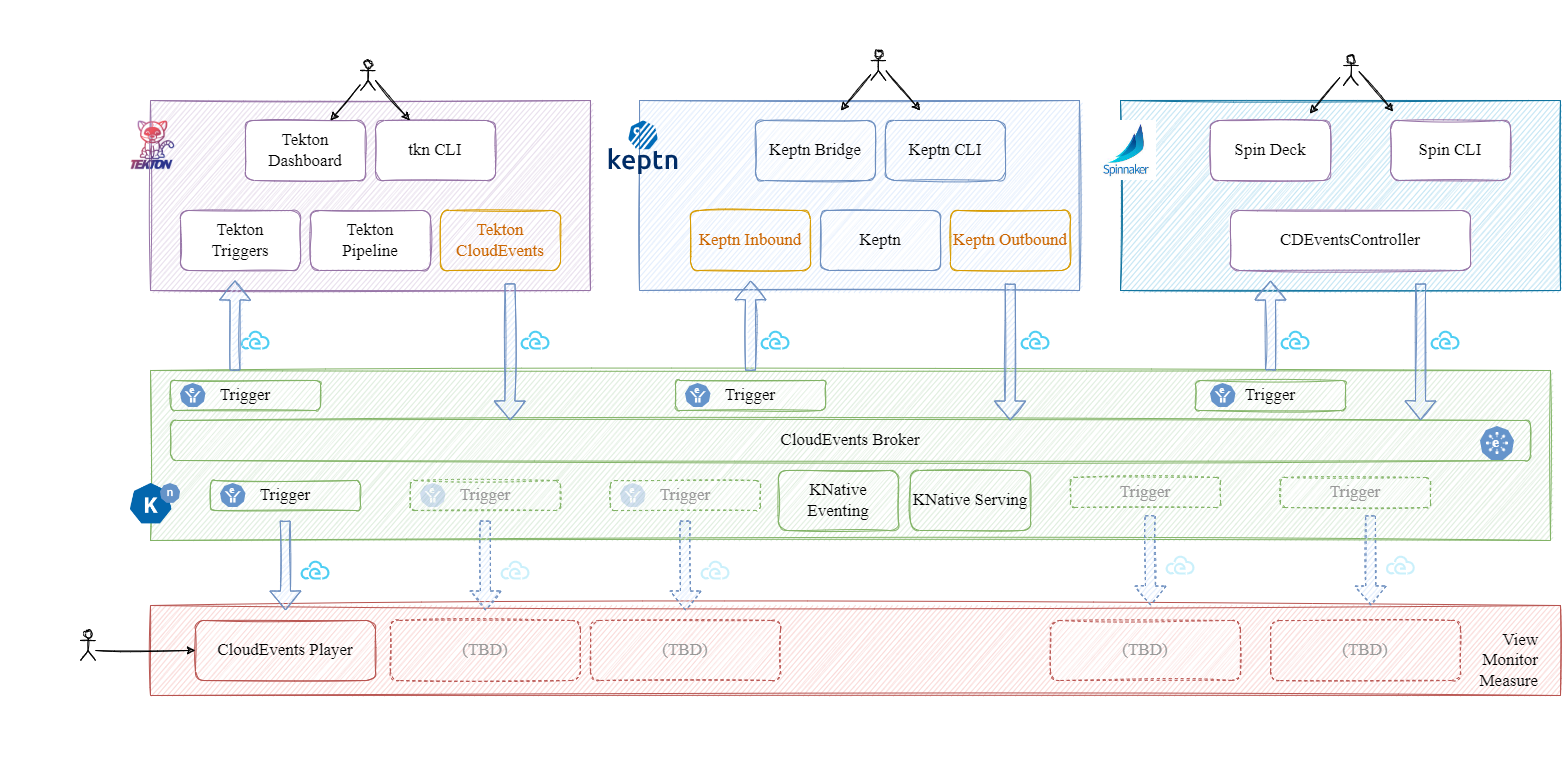
In a complex and fast moving CI/CD world with a lot of different tools and platforms that need to communicate with each other interoperability stands as a crucial thing. The maintainer of a CI/CD system needs to swap out tools in short time with little to no stops.
The larger and more complex a CI/CD system becomes, challenges increase in knowing how the tools communicate and what they do.
The CDEvents protocol defines a vocabulary of events enabling tools to communicate in an interoperable way.
We extend other efforts such as CloudEvents by introducing purpose and semantics to the event.

By providing an interoperable way of tools to communicate we also provide means to give an overview picture increasing observability, but also to give measuring points for metrics.
The latest release of the specification on is
v0.4.0, and you can
continuously follow the latest updates of the specification on the main
branch.
To understand more about the concepts and ideas that have formed the current published specification, visit the CDEvents Documentation site.
The reference specification is maintained in this repository.
Key assets are as follows:
The Continuous Delivery Foundation White Paper on CDEvents
An introduction to CDEvents and associated concepts
An overview of Metadata common across the CDEvents Specification
Definition of specific events that are fundamental to pipeline execution and orchestration
Handling Events relating to changes in version management of Source Code and related assets
Handling Events associated with Continuous Integration activities, typically involving build and test
Handling Events associated with Continuous Deployment activities
Handling Events associated with the health of the services deployed and running in a specific environment
Handling Events associated with Test execution performed independently or as part of CI/CD pipelines.
Defining how CDEvents are mapped to CloudEvents for transportation and delivery
Schemas and Conformance
The schemas folder contains jsonschemas for all events in the spec. The conformance folder contains simple JSON examples for all events. The content of the conformance folder is used for testing purposes: the structure of the files in there is sound, the values have correct types but are not particularly meaningful.
CDEvents includes SDKs for several languages:
Reach out to see what we're up via:
If you would like to contribute, see our contributing guidelines.
The project has been started by the CDF SIG Events. Its governance is documented in the community repository.


















































































































{kind=link}