![]()


Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.
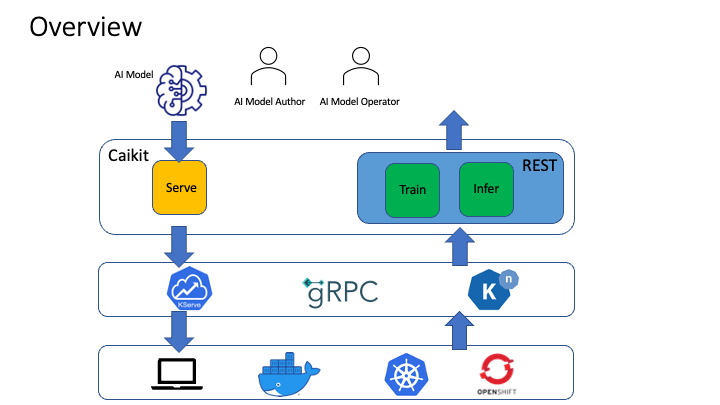
Caikit streamlines the management of AI models for application usage by letting AI model authors focus on solving well known problems with novel technology. With a set of model implementations based on Caikit, you can:
- Run training jobs to create models from your data
- Run model inference using data APIs that represent data as structures rather than tensors
- Implement the right training techniques to fit the model, from static regexes to multi-GPU distribution
- Merge models from diverse AI communities into a common API (e.g.
transformers,tensorflow,sklearn, etc...) - Update applications to newer models for a given task without client-side changes
Developers who write applications that consume AI models are not necessarily AI experts who understand the intricate details of the AI models that they use. Some would like to treat AI as a "black box function" where they give it input and it returns the output. This is similar in cloud computing whereby some users would like to deploy their applications to the cloud without detailed knowledge of the cloud infrastructure. The value for them is in their application and that is what is of most interest to them.
Caikit provides an abstraction layer for application developers where they can consume AI models through APIs independent of understanding the data form of the model. In other words, the input and output to the model is in a format which is easily programmable and does not require data transformations. This facilitates the model and the application to evolve independently of each other.
When deploying a small handful of models, this benefit is minimal. The benefits are generally realized when consuming 10s or hundreds of AI models, or maintaining an application over time as AI technology evolves. Caikit simplifies the scaling and maintenance of such integrations compared to other runtimes. This is because other runtimes require an AI centric view of the model (for example, the common interface of “tensor in, tensor out”) which means having to code different data transformations into the application for each model. Additionally, the data form of the model may change from version to version.
There are 2 key things to define upfront when using Caikit to manage your AI model. They are as follows:
The module defines the entry points for Caikit to manage your model. In other words, it tells Caikit how to load, infer and train your model. An example is the text sentiment module. The data model defines the input and outputs of the model task. An example is the text sentiment data model.
The model is served by a gRPC server which can run as is or in any container runtime, including Knative and KServe. Here is an example of the text sentiment server code for gRPC. This references the module configuration here. This configuration specifies the module(s), which wrap the model(s), to serve.
There is an example of a client here which is a simple Python CLI which calls the model and queries it for sentiment analysis on 2 different pieces of text. The client also references the module configuration.
Check out the full Text Sentiment example to understand how to load and infer a model using Caikit. If you want to get started with developing and integrating your AI model algorithm using Caikit, checkout the GitHub template. In the template repository when you click on the green Use this template button, it generates a repository in your GitHub account with a simple customized module which is wrapped to be served by the Caikit runtime. This template is designed to be extended for module implementations.
There are 2 user profiles who leverage Caikit:
- AI Model Author:
- Model Authors build and train AI models for data analysis
- They bring data and tuning params to a pre-existing model architecture and create a new concrete model using APIs provided by Caikit
- Examples of model authors are machine learning engineers, data scientists, and AI developers
- AI Model Operator:
- Model operators use an existing AI model to perform a specific function within the context of an application
- They take trained models, deploy them, and then infer the models in applications through APIs provided by Caikit
- Examples of operators are cloud and embedded application developers whose applications need analysis of unstructured data
Get going with Getting Started or jump into more details with the Python API docs.
Check out our contributing guide to learn how to contribute to Caikit.
Participation in the Caikit community is governed by the Code of Conduct.






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




















































































































