bupt-ai-cz / hhcl-reid Goto Github PK
View Code? Open in Web Editor NEWHard-sample Guided Hybrid Contrast Learning for Unsupervised Person Re-Identification
Hard-sample Guided Hybrid Contrast Learning for Unsupervised Person Re-Identification
您好,感谢您进一步完善了相关代码。
在复现及阅读代码过程中遇到一些问题,经过一段时间还是有疑惑,在此提问,希望您能抽出宝贵时间来解惑。
在论文4.3节提到,新构建了一个P*C的instance features memory bank。在代码中,这一部分对应到train.py的206-212行代码,有CMhybrid和CMhybrid_v2两种类型bank。CMhybrid是直接加倍cluster_featuers;CMhybrid_v2则按照论文所说从每个类中随机抽取P个instace feature,相当于在cluster_features基础上新加了P*C个特征。
按照您提供的训练模型,性能较好的却是采用CMhybrid类型的bank,而CMhybrid没有构建论文4.3节中提出的P*C的instance feature memory bank.这个核心点。
请问我理解的对吗?
CMhybrid和CMhybrid_v2的区别您认为有何不同呢?
非常期待您的回复!
注:train.py和cm.py文件中,cmhybrid拼写出现了小错误。
我自己跑了一下,效果不太好,能解释一下吗?
我发现这里训练的时候没有使用到outlier,这样会损失一部分的数据在模型更新上?请问有实验过加outlier的情况吗?
您好,论文中公式(6)(7)采用余弦相似度来挑选难正样本和难负样本,但是为何难正样本是argmax,难负样本是argmin呢?不应该反过来吗?
非常期待您的回复~

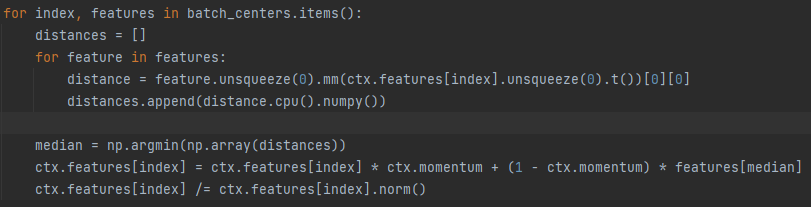
请问这段代码的意思是用hard positive去对当前质心做动量更新吗?这样可以对应论文中的使用hard positive做对比学习吗?那hard negtive如何在代码中体现呢?
(tf1.14) root@dl-220706210722719-pod-jupyter-58b598676f-pfb64:~/HHCL-ReID# CUDA_VISIBLE_DEVICES=0 python examples/train.py -b 256 -a resnet50 -d market1501 --iters 200 --eps 0.45 --momentum 0.1 --num-instances 16 --pooling-type avg --memorybank CMhybrid --epochs 60 --logs-dir examples/logs/market1501/resnet50_avg_cmhybrid
Traceback (most recent call last):
File "examples/train.py", line 20, in
from hhcl import datasets
File "/root/HHCL-ReID/hhcl/init.py", line 3, in
from . import datasets
File "/root/HHCL-ReID/hhcl/datasets/init.py", line 7, in
from .veri import VeRi
ModuleNotFoundError: No module named 'hhcl.datasets.veri'
完全无监督

有监督

您好,在使用所提供的训练模型进行测试时,发现性能并没有论文中所提到的精度,是不是上传有错误呢?
您好,感谢您非常出色的工作!
但是我在复现时遇到一些问题:
非常期待您的回复,谢谢!
请问有没有可视化的例子呢
首先感谢您做出的杰出贡献!
最近在我复现您的代码的过程中,我发现我复现的结果和您论文中的结果存在一定的性能差距。我在market1501上不做任何修改使用run.sh中的命令执行,使用CMhybrid memory最终获得的性能是82.4%mAP,和84.2有些差距。请问下您还有使用一些别的技巧或者改进了代码进一步提高了性能?
期待得到您的回复,谢谢!
运行过程中出现下面的问题 是什么原因呢 该怎么解决呢
==> Statistics for epoch 0: 1 clusters
Traceback (most recent call last):
File "/export/H/examples/hhcl/utils/data/init.py", line 24, in next
return next(self.iter)
File "/export/zhangshuorui/anacondagpu/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in next
data = self._next_data()
File "/export/anacondagpu/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1176, in _next_data
raise StopIteration
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "examples/train.py", line 397, in
main()
File "examples/train.py", line 122, in main
main_worker(args)
File "examples/train.py", line 314, in main_worker
trainer.train(epoch, train_loader, optimizer,
File "/export/H/examples/hhcl/trainers.py", line 25, in train
inputs = data_loader.next()
File "/export/H/examples/hhcl/utils/data/init.py", line 27, in next
return next(self.iter)
File "/export/anacondagpu/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in next
data = self._next_data()
File "/export/anacondagpu/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1176, in _next_data
raise StopIteration
StopIteration
运行命令
CUDA_VISIBLE_DEVICES=6,7 python examples/train.py -b 256 -a resnet50 -d market1501 --iters 200 --eps 0.45 --num-instances 16 --pooling-type avg --memorybank CMhybrid --epochs 60 --logs-dir examples/logs/market1501/resnet50_avg_cmhybrid
数据集存放路径
examples/data/market1501/Market-1501-v15.09.15
当我用两个GPU,选择batch_size为128时,在market1501数据集上的map只有75.0,与论文中数据对比降低了10个百分点。请问这个数据合理吗?
loss = self.hard_weight * (self.cross_entropy(output_hard, targets) + (1 - self.hard_weight) * self.cross_entropy(output_mean, targets))
您好,我想求教一下,这个loss公式和论文中的公式2吻合吗?
想问一下您的GPU显存是多少呢
Is the number of GPUs or type of GPU effective in accuracy that achieved in the paper? and if yes, why?
If I don't have 4 GPUs and I have 1 GPU, what would happen when running the code?
and what should I have do to get the paper results with 1 GPU?
你好,我用一块RTX 24g的卡在market1501数据集上使用命令训练:
PYTHONIOENCODING=utf-8 CUDA_VISIBLE_DEVICES=0 python train.py -b 256 -a resnet50 -d market1501 \
--iters 200 --eps 0.45 --num-instances 16 --pooling-type avg --memorybank CMhybrid --epochs 60 \
--logs-dir work_dirs/logs/market1501/resnet50_avg_cmhybrid�
但得到的结果mAP=71.4,Top-1=85.7,相差10个点以上,请问,单卡训练时有影响性能的情况么?其他的参数有什么需要另外设置的嘛?
谢谢!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.