brucechou1983 / chexnet-keras Goto Github PK
View Code? Open in Web Editor NEWThis project is a tool to build CheXNet-like models, written in Keras.
License: MIT License
This project is a tool to build CheXNet-like models, written in Keras.
License: MIT License



























































































































@brucechou1983 :
After training, using cam.py, I am getting the predicted cam output and bounding box mismatch. Please help.

450/3258 [===>..........................] - ETA: 38:28 - loss: 0.1777Traceback (most recent call last):
File "/home/lib/python3.6/site-packages/PIL/ImageFile.py", line 233, in load
s = read(self.decodermaxblock)
File "/home/lib/python3.6/site-packages/PIL/PngImagePlugin.py", line 650, in load_read
cid, pos, length = self.png.read()
File "/home/lib/python3.6/site-packages/PIL/PngImagePlugin.py", line 117, in read
length = i32(s)
File "/home/lib/python3.6/site-packages/PIL/_binary.py", line 71, in i32be
return unpack_from(">I", c, o)[0]
struct.error: unpack_from requires a buffer of at least 4 bytes
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 228, in
main()
File "train.py", line 211, in main
shuffle=False,
File "/home/site-packages/keras/legacy/interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "/home/site-packages/keras/engine/training.py", line 1732, in fit_generator
initial_epoch=initial_epoch)
File "/home/.local/lib/python3.6/site-packages/keras/engine/training_generator.py", line 185, in fit_generator
generator_output = next(output_generator)
File "/home/.local/lib/python3.6/site-packages/keras/utils/data_utils.py", line 625, in get
six.reraise(*sys.exc_info())
File "/home/.local/lib/python3.6/site-packages/six.py", line 696, in reraise
raise value
File "/home/.local/lib/python3.6/site-packages/keras/utils/data_utils.py", line 610, in get
inputs = future.get(timeout=30)
File "/home/anaconda3/envs/dsr_ccr_py36/lib/python3.6/multiprocessing/pool.py", line 644, in get
raise self._value
File "/home/anaconda3/envs/dsr_ccr_py36/lib/python3.6/multiprocessing/pool.py", line 119, in worker
result = (True, func(*args, **kwds))
File "/home/.local/lib/python3.6/site-packages/keras/utils/data_utils.py", line 406, in get_index
return _SHARED_SEQUENCES[uid][i]
File "/home/Project/CheXNet-Keras-master/generator.py", line 51, in getitem
batch_x = np.asarray([self.load_image(x_path) for x_path in batch_x_path])
File "/home/Project/CheXNet-Keras-master/generator.py", line 51, in
batch_x = np.asarray([self.load_image(x_path) for x_path in batch_x_path])
File "/home/Project/CheXNet-Keras-master/generator.py", line 59, in load_image
image_array = np.asarray(image.convert("RGB"))
File "/home/anaconda3/lib/python3.6/site-packages/PIL/Image.py", line 873, in convert
self.load()
File "/home/anaconda3/envs/lib/python3.6/site-packages/PIL/ImageFile.py", line 239, in load
raise OSError("image file is truncated")
hi,
bruce.
version 0.3.0 is very good.Congratulations!
I want to share one of the problems I encountered.
I setted the config as:
use_default_split=false,
train_patient_count=29405,
dev_patient_count=1400,
split_dataset_random_state=2
I increase the training dataset count.I think it can improve the mean AUC in result,but it's not.
The result is:mean auroc: 0.7680469487585274.Less than default setting result.
I do not understand why.Would you tell me why default split worked better?
And how to set the number of train_patient_count for improving the AUC.
Thank you for your nice work.
When you scale by 255, some of the pixels which already have a value close to zero (such as black part of the image) will have a very small number as the value. However, when you go on to substract the imagenet mean, some pixels will have negative values. Is this as intended?
I've used a Google Cloud with 2 x NVIDIA Tesla K80 (12GB for each), 16 vCPUs, 16 GB memory.
I've trained with batch_size=32 and 16 but always got MemoryError. Can I know what is the best computer requirements for training?
While trying to stop the generator from shuffling test set images, I found that replacing
df = self.dataset_df.sample(frac=1., random_state=self.random_state)
with
df = self.dataset_df in AugmentedImageSequence.prepare_dataset() changes the performance.
That does not seem normal.
I constructed a chexnet model using DenseNet121 and loaded our pre-trained weights. On generating CAMs of the final conv layer, an unwanted region of high activations are found on all output CAMs. This is regardless of input samples.




First two are outputs from abnormal class and last two from normal class
I find the test_cam.py in develop branch, but not in master branch.And test_cam.py in develop have error in code.The test_cam.py is not completed,right?
Line 41 in f01a206
suggestion: use len(class_names) to initialize vec instead
Thanks for you providing your implementation! Could you please upload your best test results? So I can compare it with my running result.
Hello I am getting this issue what will be the solution if anyone knows>?
raise RuntimeError('''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
Hi, I am having some trouble unpickling the history.pkl file. I am getting ValueError: unsupported pickle protocol: 3
I setted about use_class_balancing=true.But the result is bad.Is not in the multi-task case,class_balancing should not be used?Thanks.
Hello,
After running python test.py I found reasonable result (~0.80) but all the predictions are very low (<< 0.5). Why is this happening?. I would have expected predictions to be below or above p ~ 0.5, since each task is binary classification... The ROC curves look fine but after choosing very low thresholds...
Here are some outputs examples:
predictions: [[2.1949896e-04 2.5974975e-10 3.2518754e-05 2.2396650e-03 1.0748411e-06
5.3286135e-06 2.3767587e-08 1.8565892e-07 2.9599332e-06 6.0097425e-09
2.2628668e-09 5.6686780e-09 1.7793096e-07 2.8444550e-16]]
process image: 00014716_007.png
predictions: [[1.7701820e-04 9.9891839e-10 1.2038935e-04 2.1879091e-03 2.9724788e-06
4.3491709e-06 1.5626190e-08 8.1510120e-07 4.9612390e-06 5.9254237e-09
3.1557206e-09 7.8512441e-09 3.9710633e-07 5.7806499e-16]]
process image: 00029817_009.png
predictions: [[1.3384523e-04 1.7685409e-10 2.9474650e-05 5.9209261e-03 9.6525923e-07
3.6600391e-06 4.1517431e-08 2.1312287e-07 8.2614024e-06 5.4943364e-08
1.8906021e-09 2.7751146e-09 1.3156065e-07 8.6311956e-17]]
process image: 00014687_001.png
predictions: [[5.5539206e-04 5.5167826e-10 1.7801076e-04 2.8877158e-03 1.1419656e-06
2.0136347e-06 1.9730347e-08 6.7405063e-07 1.5730091e-05 4.5662714e-09
1.4418623e-09 2.6214038e-09 4.0143416e-07 2.9864267e-16]]
process image: 00017877_001.png
Thank you so much for sharing your training code!! but I encountered an weired error, after running for 1 or 2 epoch, it occurs
current learning rate: 0.0010000000474974513
Traceback (most recent call last):
File "train.py", line 232, in
main()
File "train.py", line 215, in main
class_weight=class_weights,
File "/workspace/huwang/tools/anaconda3/lib/python3.6/site-packages/keras/legacy/interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "/workspace/huwang/tools/anaconda3/lib/python3.6/site-packages/keras/engine/training.py", line 2213, in fit_generator
callbacks.on_epoch_end(epoch, epoch_logs)
File "/workspace/huwang/tools/anaconda3/lib/python3.6/site-packages/keras/callbacks.py", line 76, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "/home/mnt/StorageArray2_DGX1/huwang/dataset/CXR14/CheXNet-Keras-master-20170124/callback.py", line 76, in on_epoch_end
x, y = load_generator_data(self.generator, self.steps, len(self.class_names))
File "/home/mnt/StorageArray2_DGX1/huwang/dataset/CXR14/CheXNet-Keras-master-20170124/callback.py", line 22, in load_generator_data
batch_x, batch_y = next(generator)
ValueError: generator already executing
I am not that familiared with Keras. May I know how to solve it? Thx again
in some cases validation loss can be high yet with better mean auc.current code copies weights.h5 (which are monitored according to val_loss.) to best_weights which is a bug.best weights should be saved from model and not copied
Befor the sigmoid of prediction layer,it's a linear dense of 1024.What is it role?I delete the linear dense and the result is also good.
Anyone have the weights as downloadable file?
Can some please tell order of the class name for the predicted class index , from pre trained weights -https://drive.google.com/file/d/19BllaOvs2x5PLV_vlWMy4i8LapLb2j6b/view or how to know it.
I could get a prediction using the weights but not able to find which class it gets predicted
predicted = model.predict(img)
predicted = np.argmax(predicted, axis= 1)
=>array([3])
this 3 represents which class name and also can i get all the class name to their index number - like edema, effusion, Need for all 14 for this given weights
I am trying to predict labels (using pertained weights) for some random chest xray images. But it always predicts third class. I don't know if the implementation is working or no. Any idea what could be the problem?
The implementation of learning rate decay every time validation loss stop decrease is vary elegant in the code, but unfortunately I use native tensorflow to implemente CheXNet instead of Keras, which means I must write more code for that function.
Now I just want to recurrent the result of CheXNet as a baseline so I would be appreciate if anyone can provide a gourp of hyperparameters include learning rate decay step and correspond learning rate which lead to a well trained model.
My code can receive decay step and learning rate in the following format so I'm sure I can train my model preparly if good learning rate is provide:
epochs_lr = [[5, 0.001], [20, 0.0001], [10, 0.00001], [5, 0.000001]]
Benchmarking different NNs
When you do cam preprocessing,the function transform_batch_images is not called.But the result of cam images is right.Why?Did you trained model without the function transform_batch_images?
should first transform to mean 0 and std 1 and then normalize by batch_x*std_imagenet+mean_imagenet
Hi, thanks a lot for providing the Keras implementation of CheXNet.
I trained your model (without any change) on the NIH-14 dataset. But average of class specific AUC values is around 0.68 only. The maximum AUC value achieved for this implementation is about 0.77 (for MASS pathology). These numbers seem significantly lower than those published in the paper, or PyTorch implementation on Github. Could you please let me know if I am missing anything important here? Thanks!
The mean and std which you are using in the image preprocessing is the mean and std in imagenet. Imagenet is training with RGB images.But x-ray image is gray image.So how to set the mean and std in chexnet?Thank you.
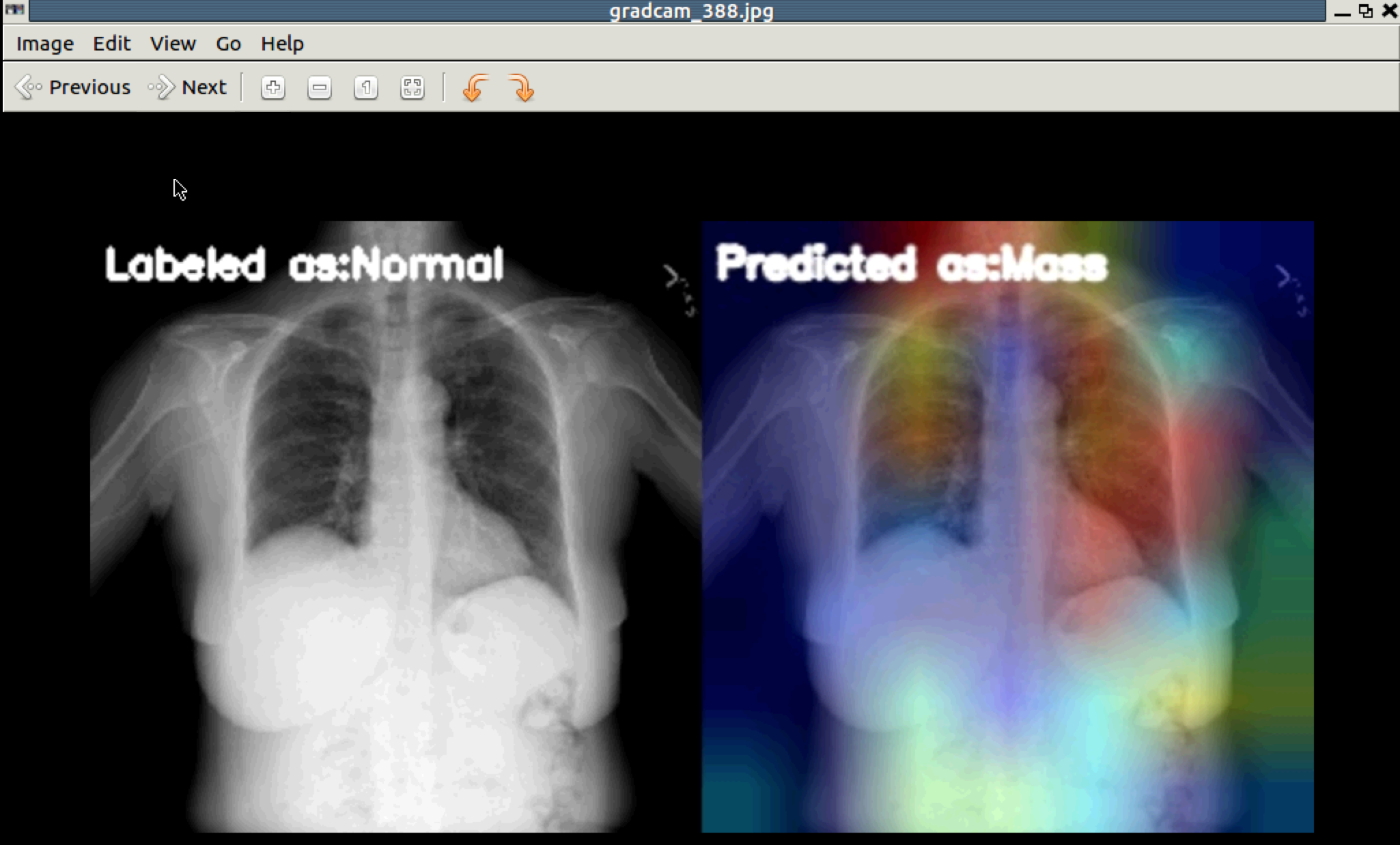
Looking at the GradCam output, most of the test samples seem to wrongly predicted.
** y_hat[1502] = [0.14673501 0.01134805 0.12639914 0.24252617 0.5742752 0.58539766
0.19411625 0.8418181 0.28799048 0.11468869 0.86016876 0.35104084 0.4047146 0.07352768]
** y[1502] = [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
** Label/Prediction: Normal/Emphysema
Hey, I am working on an Xray classification problem and wanted to use your trained model for transfer learning rather than the standard imagenet model. Is there any way I can get your model or the trained weights you obtained?
ValueError: You are trying to load a weight file containing 242 layers into a model with 241 layers.
i'm trying to predict unknown chest x-ray photo and i am getting a very low prediction numbers..
can i predict new image using your trained model?
I have received the following error message when it finished the second epoch of command python train.py
6515/6516 [============================>.] - ETA: 0s - loss: 0.7473 - Atelectasis_loss: 0.1070 - Cardiomegaly_loss: 0.0215 - Effusion_loss: 0.0999 - Infiltration_loss: 0.1867 - Mass_loss: 0.0552 - Nodule_loss: 0.0686 - Pneumonia_loss: 0.0160 - Pneumothorax_loss: 0.0484 - Consolidation_loss: 0.0452 - Edema_loss: 0.0185 - Emphysema_loss: 0.0246 - Fibrosis_loss: 0.0183 - Pleural_Thickening_loss: 0.0354 - Hernia_loss: 0.0021
*********************************
current learning rate: 0.0010000000474974513
Traceback (most recent call last):
File "train.py", line 232, in <module>
main()
File "train.py", line 215, in main
class_weight=class_weights,
File "/home/paperspace/anaconda3/lib/python3.6/site-packages/keras/legacy/interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "/home/paperspace/anaconda3/lib/python3.6/site-packages/keras/engine/training.py", line 2213, in fit_generator
callbacks.on_epoch_end(epoch, epoch_logs)
File "/home/paperspace/anaconda3/lib/python3.6/site-packages/keras/callbacks.py", line 76, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "/home/paperspace/CheXNet-Keras/callback.py", line 76, in on_epoch_end
x, y = load_generator_data(self.generator, self.steps, len(self.class_names))
File "/home/paperspace/CheXNet-Keras/callback.py", line 22, in load_generator_data
batch_x, batch_y = next(generator)
ValueError: generator already executing
My workaround solution is saving weights.h5 and best_weights.h5 after each completed epoch during training. So, I can observe the increasing number of the mean auroc after epochs.
Let me guess, Is it something wrong with the callback.py file about thread safe?
Note: my machine is Quadro P6000 Cloud 24GB GPU on Paperspace
Have you tried with all models (VGG16, VGG19, DenseNet121, ResNet50, InceptionV3, InceptionResNetV2, NASNetMobile, NASNetLarge) and can you give me the results of those?
I downloaded the trained model weights, and tried to load them to predict. I picked a image from the dataset (00000322_010.png), labelled pneumothorax, and the predicted probability seemed to be extremely low for all classes. Here is how I ran the prediction:
import cv2
import numpy as np
from keras.models import load_model
model = load_model('./CheXNet-Keras/model.h5') # I saved the model from train.py
model.load_weights('./CheXNet-Keras/brucechou1983_CheXNet_Keras_0.3.0_weights.h5')
im = cv2.imread("./CheXNet-Keras/data/images/00000322_010.png")
im_r = cv2.resize(im, (224, 224))
im_t = im_r.reshape(1, 224, 224, 3).astype('float32') / 255
prediction = model.predict(im_t)The output of prediction was:
array([[2.0528843e-01, 9.4045536e-04, 3.9193404e-01, 9.2863671e-02,
1.0580428e-02, 1.1802137e-02, 3.6063469e-03, 1.4762501e-01,
2.5597181e-02, 1.1413006e-02, 4.9169478e-03, 1.2800613e-02,
4.7103822e-02, 3.9492457e-05]], dtype=float32)
Any suggestion?
Hi, Bruce.
I am an junior student from university, I find your code is well commented and really helpful to noob like me. However, when I try to run the train.py in the environment tensorflow==1.2 (beacuse when I have installed version 1.4, it said that cudnn6 was not installed, so I choose version 1.4), I met following error code. Could you help me out?
`** create image generators **
** set output weights path to: ./experiments/1/weights.h5 **
** check multiple gpu availability **
** multi_gpu_model is used! gpus=2 **
2018-03-08 00:39:02.432635: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -> (device: 0, name: Tesla M40 24GB, pci bus id: 0000:02:00.0)
2018-03-08 00:39:02.432689: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Creating TensorFlow device (/gpu:1) -> (device: 1, name: Tesla M40 24GB, pci bus id: 0000:03:00.0)
Traceback (most recent call last):
File "train.py", line 229, in
main()
File "train.py", line 169, in main
model_train = multi_gpu_model(model, gpus)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/utils/training_utils.py", line 175, in multi_gpu_model
outputs = model(inputs)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/engine/topology.py", line 617, in call
output = self.call(inputs, **kwargs)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/engine/topology.py", line 2081, in call
output_tensors, _, _ = self.run_internal_graph(inputs, masks)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/engine/topology.py", line 2232, in run_internal_graph
output_tensors = _to_list(layer.call(computed_tensor, **kwargs))
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/layers/normalization.py", line 193, in call
self.momentum),
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py", line 1001, in moving_average_update
x, value, momentum, zero_debias=True)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/training/moving_averages.py", line 70, in assign_moving_average
update_delta = _zero_debias(variable, value, decay)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/training/moving_averages.py", line 180, in _zero_debias
"biased", initializer=biased_initializer, trainable=False)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 1065, in get_variable
use_resource=use_resource, custom_getter=custom_getter)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 962, in get_variable
use_resource=use_resource, custom_getter=custom_getter)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 367, in get_variable
validate_shape=validate_shape, use_resource=use_resource)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 352, in _true_getter
use_resource=use_resource)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 664, in _get_single_variable
name, "".join(traceback.format_list(tb))))
ValueError: Variable conv1/bn/moving_mean/biased already exists, disallowed. Did you mean to set reuse=True in VarScope? Originally defined at:
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py", line 1001, in moving_average_update
x, value, momentum, zero_debias=True)
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/layers/normalization.py", line 193, in call
self.momentum),
File "/home/amax/anaconda2/envs/pancj/lib/python3.6/site-packages/keras/engine/topology.py", line 617, in call
output = self.call(inputs, **kwargs)
`
@brucechou1983
Here I have asked the question
https://stackoverflow.com/questions/64390544/unable-to-load-chexnet-pre-trained-weight-file-to-densenet121
densenet = tf.keras.applications.DenseNet121( include_top=False, weights="CheXNet_Keras_0.3.0_weights.h5", input_shape=(224,224,3) )
ValueError: You are trying to load a weight file containing 242 layers into a model with 241 layers. if I Call densenet121
Please help...
I check the train.py, finding the linemodel_train.compile(optimizer=optimizer, loss="binary_crossentropy")
So i think it's used for detecting.
But the paper also classify 14 diseases?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.