可以直接在Colab尝试后面所有示例
pip install accelerate diffusers controlnet_aux omegaconfmkdir -p /content/models
# stable diffusion 模型
git clone --depth=1 https://huggingface.co/runwayml/stable-diffusion-v1-5 /content/models/stable-diffusion-v1-5
# LCM lora 模型
git clone --depth=1 https://huggingface.co/latent-consistency/lcm-lora-sdv1-5 /content/models/lcm-lora-sdv1-5
# ControlNet 模型
git clone --depth=1 https://huggingface.co/lllyasviel/ControlNet-v1-1 /content/models/ControlNet-v1-1import torch
from IPython.display import display
from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
model_id = "/content/models/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
#prompt = "a photo of an astronaut riding a horse on mars"
prompt = ["(taylor swift), 1girl, best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
images = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20).images
for image in images:
display(image)from io import BytesIO
import torch
import requests
from PIL import Image
from IPython.display import display
from diffusers import StableDiffusionImg2ImgPipeline, UniPCMultistepScheduler
model_id = "/content/models/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
url = "https://raw.githubusercontent.com/comfyanonymous/ComfyUI/master/input/example.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((512, 512))
prompt = ["(taylor swift), 1girl, best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
images = pipe(
prompt, negative_prompt=negative_prompt, image=init_image,
strength=0.75, guidance_scale=7.5, num_inference_steps=20
).images
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
display(image_grid([init_image, images[0]], 1, 2))使用LCM lora加快生成,从20步缩短到4步
import torch
from IPython.display import display
from diffusers import StableDiffusionPipeline, LCMScheduler
model_id = "/content/models/stable-diffusion-v1-5"
adapter_id = "/content/models/lcm-lora-sdv1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
# 加载lcm lora
pipe.load_lora_weights(adapter_id)
pipe.fuse_lora()
prompt = ["(taylor swift), 1girl, best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
images = pipe(
prompt, negative_prompt=negative_prompt,
num_inference_steps=4, guidance_scale=0
).images
display(images[0])使用图像细节精准图像生成

from io import BytesIO
import cv2
import torch
import requests
import numpy as np
from PIL import Image
from IPython.display import display
from diffusers import StableDiffusionControlNetPipeline, UniPCMultistepScheduler, ControlNetModel
model_id = "/content/models/stable-diffusion-v1-5"
control_net_path = "/content/models/ControlNet-v1-1/control_v11p_sd15_canny.pth"
controlnet = ControlNetModel.from_single_file(control_net_path, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
url = "https://raw.githubusercontent.com/lllyasviel/ControlNet/main/test_imgs/man.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
# init_image = init_image.resize((512, 512))
image = np.array(init_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
prompt = ["(taylor swift), 1girl, best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
images = pipe(
prompt, canny_image, negative_prompt=negative_prompt,
num_inference_steps=20, controlnet_conditioning_scale=0.5
).images
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
display(image_grid([init_image, canny_image, images[0]], 1, 3))使用人物骨骼控制图像生成
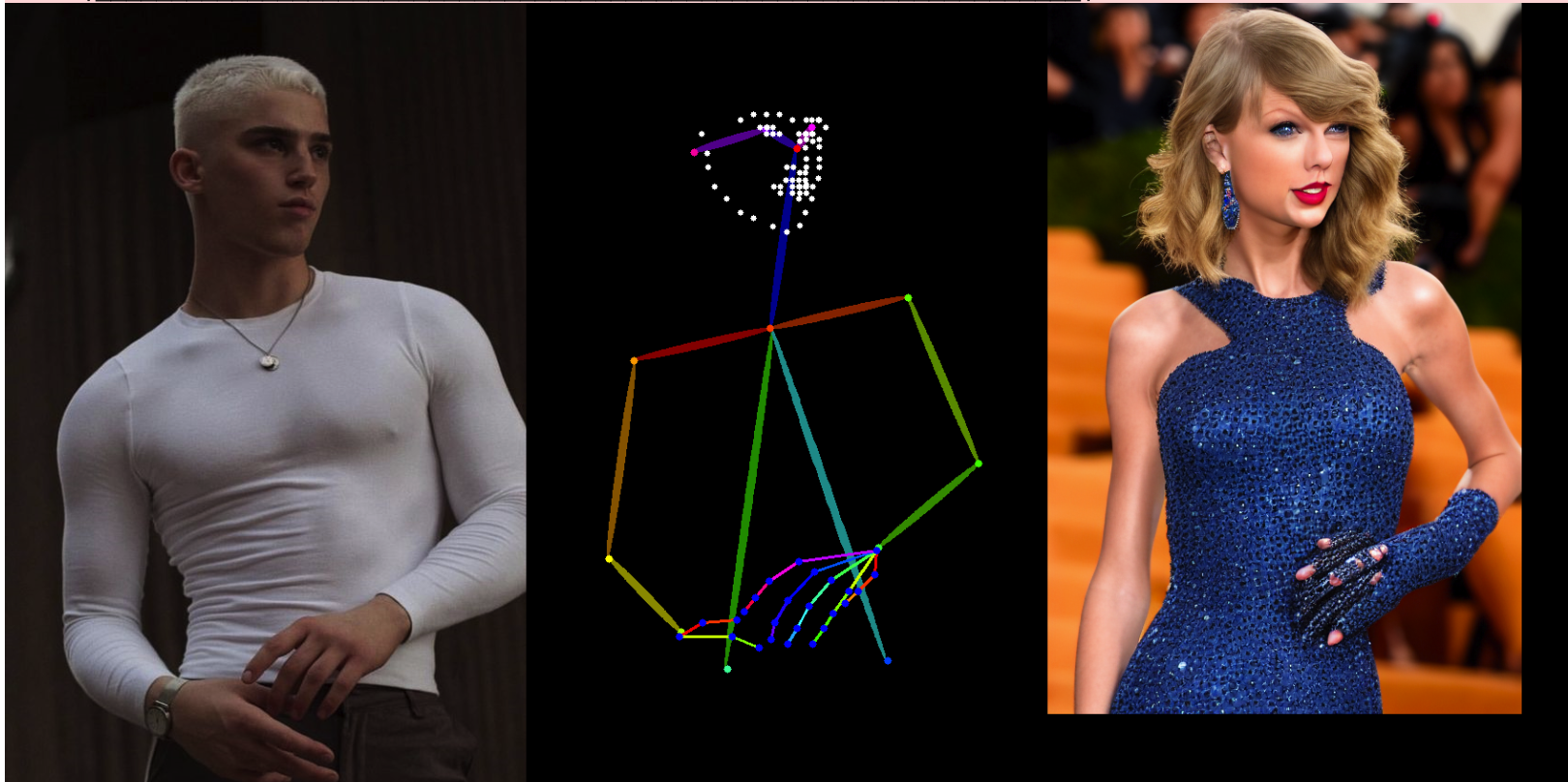
from io import BytesIO
import cv2
import torch
import requests
from PIL import Image
from IPython.display import display
from controlnet_aux import OpenposeDetector
from diffusers import StableDiffusionControlNetPipeline, UniPCMultistepScheduler, ControlNetModel
model_id = "/content/models/stable-diffusion-v1-5"
control_net_path = "/content/models/ControlNet-v1-1/control_v11p_sd15_openpose.pth"
controlnet = ControlNetModel.from_single_file(control_net_path, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
url = "https://raw.githubusercontent.com/lllyasviel/ControlNet/main/test_imgs/pose1.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
# init_image = init_image.resize((512, 512))
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = openpose(init_image, hand_and_face=True)
prompt = ["(taylor swift), 1girl, best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
images = pipe(
prompt, openpose_image, negative_prompt=negative_prompt,
num_inference_steps=20, controlnet_conditioning_scale=0.5
).images
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
display(image_grid([init_image, openpose_image, images[0]], 1, 3))生成动画
import torch
from diffusers import AnimateDiffPipeline, DDIMScheduler, MotionAdapter
from diffusers.utils import export_to_gif
model_id = "/content/models/stable-diffusion-v1-5"
adapter_id = "/content/models/animatediff-motion-adapter-v1-5-2"
adapter = MotionAdapter.from_pretrained(adapter_id, torch_dtype=torch.float16)
pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter, torch_dtype=torch.float16)
pipe.load_lora_weights(
"/content/models/animatediff-motion-lora-zoom-out", adapter_name="zoom-out",
)
pipe.load_lora_weights(
"/content/models/animatediff-motion-lora-pan-left", adapter_name="pan-left",
)
pipe.set_adapters(["zoom-out", "pan-left"], adapter_weights=[1.0, 1.0])
pipe.scheduler = DDIMScheduler.from_pretrained(
model_id,
subfolder="scheduler",
clip_sample=False,
timestep_spacing="linspace",
beta_schedule="linear",
steps_offset=1,
)
# pipe.enable_vae_slicing()
# pipe.enable_model_cpu_offload(device="cuda")
pipe.to("cuda")
prompt = ["(taylor swift), best quality, extremely detailed"]
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"]
frames = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_frames=16,
guidance_scale=7.5,
num_inference_steps=25,
generator=torch.Generator("cuda").manual_seed(42)
).frames[0]
export_to_gif(frames, "animation.gif")
