InfoExtractor is an information extraction baseline system based on the Schema constrained Knowledge Extraction dataset(SKED). InfoExtractor adopt a pipeline architecture with a p-classification model and a so-labeling model which are both implemented with PaddlePaddle. The p-classification model is a multi-label classification which employs a stacked Bi-LSTM with max-pooling network, to identify the predicate involved in the given sentence. Then a deep Bi-LSTM-CRF network is adopted with BIEO tagging scheme in the so-labeling model to label the element of subject and object mention, given the predicate which is distinguished in the p-classification model. The F1 value of InfoExtractor on the development set is 0.668.
Paddlepaddle v1.2.0
Numpy
Memory requirement 10G for training and 6G for infering
For now we’ve only tested on PaddlePaddle Fluid v1.2.0, please install PaddlePaddle firstly and see more details about PaddlePaddle in PaddlePaddle Homepage.
Please download the training data, development data and schema files from the competition website, then unzip files and put them in ./data/ folder.
cd data
unzip train_data.json.zip
unzip dev_data.json.zip
cd -
Obtain high frequency words from the field ‘postag’ of training and dev data, then compose these high frequency words into a vocabulary list.
python lib/get_vocab.py ./data/train_data.json ./data/dev_data.json > ./dict/word_idx
First, the classification model is trained to identify predicates in sentences. Note that if you need to change the default hyper-parameters, e.g. hidden layer size or whether to use GPU for training (By default, CPU training is used), etc. Please modify the specific argument in ./conf/IE_extraction.conf, then run the following command:
python bin/p_classification/p_train.py --conf_path=./conf/IE_extraction.conf
The trained p-classification model will be saved in the folder ./model/p_model.
After getting the predicates that exist in the sentence, a sequence labeling model is trained to identify the s-o pairs corresponding to the relation that appear in the sentence.
Before training the so-labeling model, you need to prepare the training data that meets the training model format to train a so-labeling model.
python lib/get_spo_train.py ./data/train_data.json > ./data/train_data.p
python lib/get_spo_train.py ./data/dev_data.json > ./data/dev_data.p
To train a so labeling model, you can run:
python bin/so_labeling/spo_train.py --conf_path=./conf/IE_extraction.conf
The trained so-labeling model will be saved in the folder ./model/spo_model.
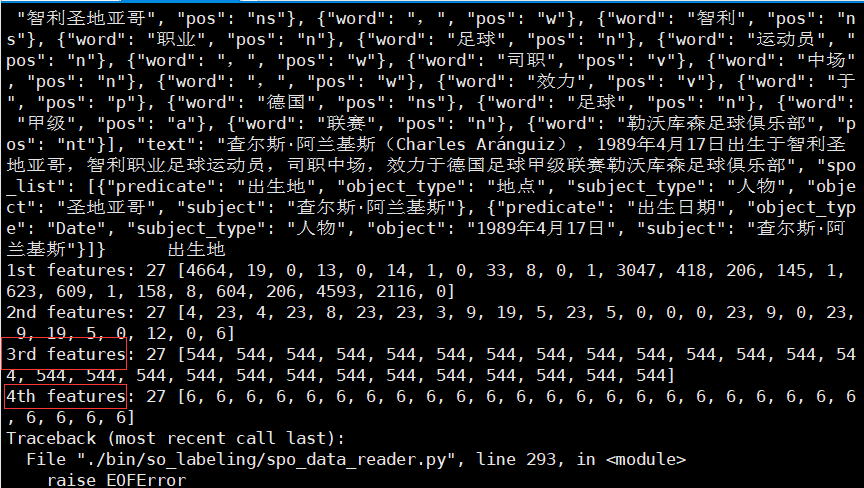
After the training is completed, you can choose a trained model for prediction. The following command is used to predict with the last model. You can also use the development set to select the optimal model for prediction. To do inference by using two trained models with the demo test data (under ./data/test_demo.json), please execute the command in two steps:
python bin/p_classification/p_infer.py --conf_path=./conf/IE_extraction.conf --model_path=./model/p_model/final/ --predict_file=./data/test_demo.json > ./data/test_demo.p
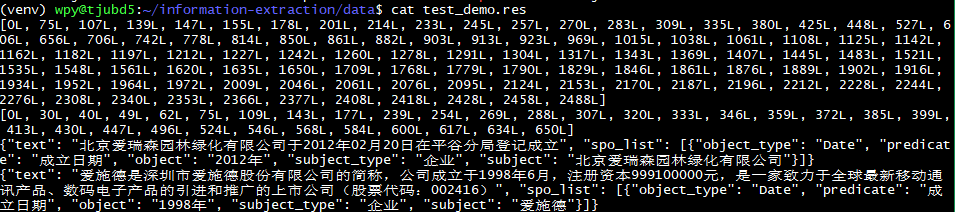
python bin/so_labeling/spo_infer.py --conf_path=./conf/IE_extraction.conf --model_path=./model/spo_model/final/ --predict_file=./data/test_demo.p > ./data/test_demo.res
The predicted SPO triples will be saved in the folder ./data/test_demo.res.
Precision, Recall and F1 score are used as the basic evaluation metrics to measure the performance of participating systems. After obtaining the predicted triples of the model, you can run the following command. Considering data security, we don't provide the alias dictionary.
zip -r ./data/test_demo.res.zip ./data/test_demo.res
python bin/evaluation/calc_pr.py --golden_file=./data/test_demo_spo.json --predict_file=./data/test_demo.res.zip
If you have any question, you can submit an issue in github and we will respond periodically.
Copyright 2019 Baidu.com, Inc. All Rights Reserved
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may otain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
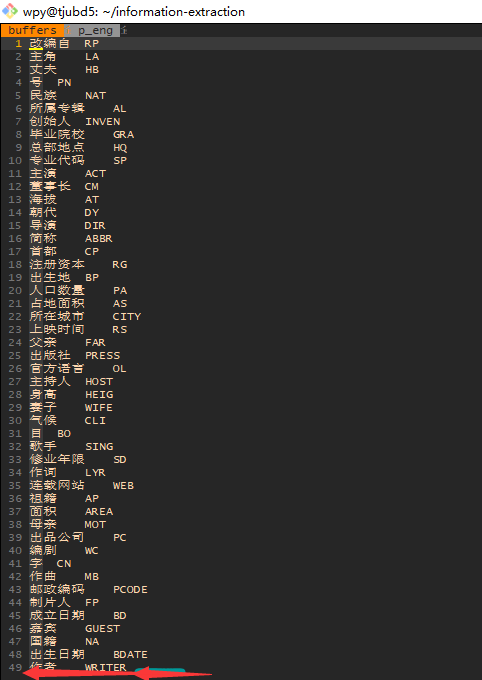
In the released dataset, the field ‘postag’ of sentences represents the segmentation and part-of-speech tagging information. The abbreviations of part-of-speech tagging (PosTag) and their corresponding part of speech meanings are shown in the following table.
In addition, the given segmentation and part-of-speech tagging of the dataset are only references and can be replaced with other segmentation results.
| POS | Meaning |
|---|---|
| n | common nouns |
| f | localizer |
| s | space |
| t | time |
| nr | noun of people |
| ns | noun of space |
| nt | noun of tuan |
| nw | noun of work |
| nz | other proper noun |
| v | verbs |
| vd | verb of adverbs |
| vn | verb of noun |
| a | adjective |
| ad | adjective of adverb |
| an | adnoun |
| d | adverbs |
| m | numeral |
| q | quantity |
| r | pronoun |
| p | prepositions |
| c | conjunction |
| u | auxiliary |
| xc | other function word |
| w | punctuations |