![]()
Next-Gen ERD: Design, Explore, Document and Analyze your database, schema and data
azimutt.app • roadmap • @azimuttapp


Azimutt is a full-stack database exploration tool, from modern ERD made for real world databases (big & messy), to fast data navigation, but also documentation everywhere and whole database analysis.

Why building Azimutt?
Databases existed for more than 40 years and despite a lot of tool around them, we couldn't find any providing a great exploration experience.
- Database clients focus on querying experience, with auto-completion and table/column lists but no visual help
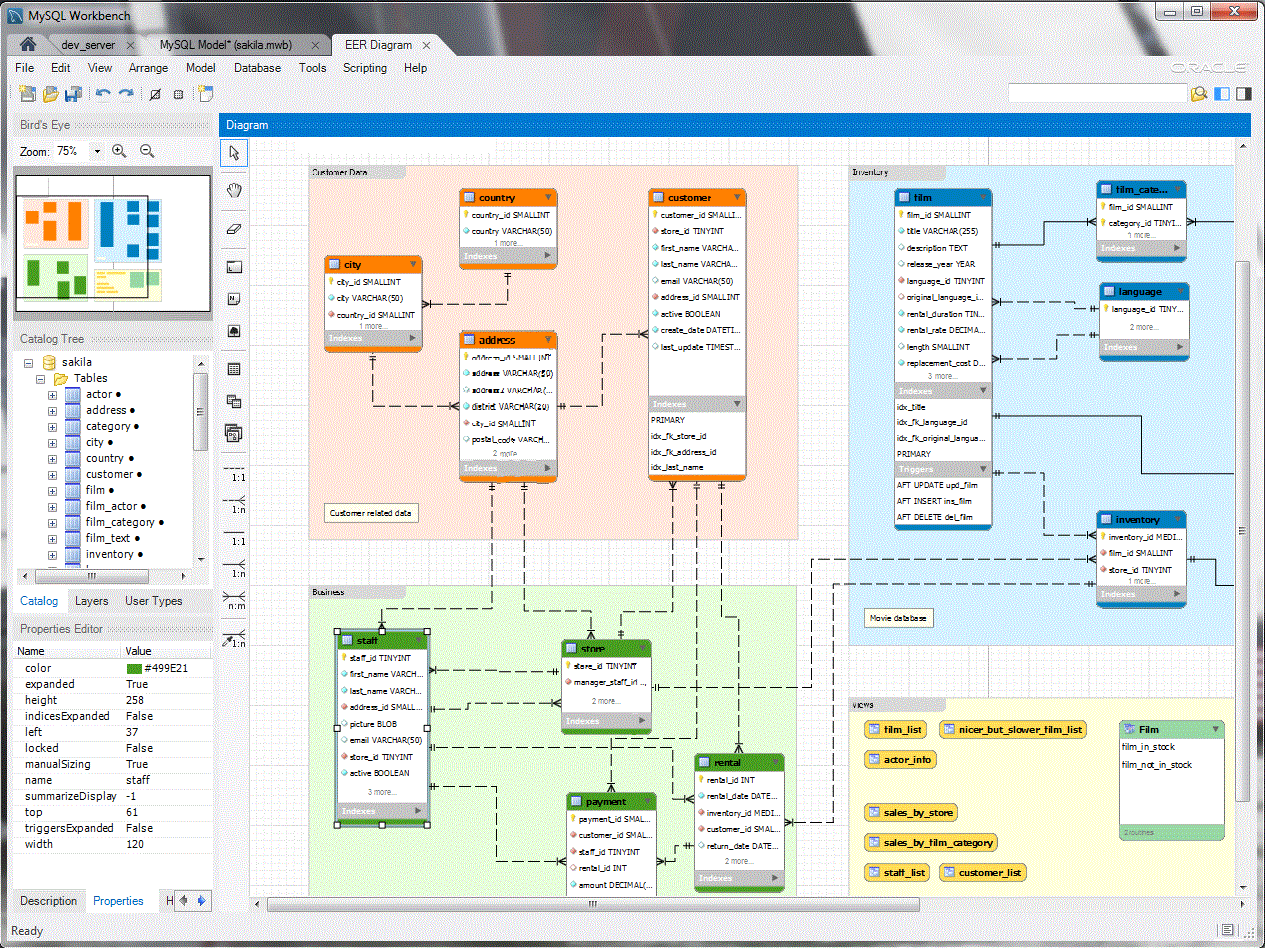
- ERDs have a great diagram UI but fall short when schema is growing (real-world use cases)
- Data catalogs are focused on data governance and lineage for data teams, miss relational db for developers
So we decided to built it 💪
Azimutt started as a schema exploration tool for databases with hundreds of tables, but now it has grown a lot:

- Design your schema using AML for a fast diagramming
- Explore your database schema using search everywhere, display only useful tables/columns and follow relations
- Query your data like never before, follow foreign keys and display entities in diagram
- Document using table/column notes and tags and layouts and memos for use cases, features or team scopes
- Analyze it to discover inconsistencies and best practices to apply
Azimutt goal is to be your ultimate tool to understand your database.
You can use our Docker image to easily deploy it. Here is the full guide.
Azimutt is built with Elixir/Phoenix (backend & admin) and Elm/elm-spa (editor).
For local development you will need to set up the environment:
- install
npm, Elm & elm-spa - install Phoenix and Elixir if needed (use asdf)
- install PostgreSQL, create a user
postgreswith passwordpostgresand a databaseazimutt_dev(seeDATABASE_URLin.envlater) - install pre-commit and run
pre-commit installbefore committing - copy
.env.exampleto.envand adapt values - source your environment and install dependencies:
source .env && npm run setup - you can now start the Azimutt server:
source .env && npm start - and finally navigate to localhost:4000 🎉
- you can login with
[email protected]email &adminpassword
Other things:
- API documentation is accessible at
/api/v1/swagger - You can use
npm run elm:bookto start Elm design system & components, and access it with localhost:4002
We have a lot of projects with a lot of commands, here is how they are structured:
- each project has its own commands (mostly npm but also elixir), the root project has global commands to launch them using a prefix
setupis a one time command to install what is requiredinstalldownload dependencies, should be run when new ones are addedstartlaunch project in dev modetestallows to run testsformatallows to run execute code formattinglintallows to run execute lintersbuildgenerate compilation outputdockersame asbuildbut in the docker image (paths are different 😕)updatebumps library versions
Prefixes in front of the command in root folder:
libs:run the command for every library inlibsfolderex:meaning elixir, it targets the backend (mostly runningmixcommands)fe:meaning frontend, target the frontend project with Elm, TypeScript & Tailwindelm:targets only Elm in the frontend projectts:targets only TypeScript in the frontend projectcli:run the command for thecliprojectdesktop:run the command for thedesktopprojectbe:meaning browser extension run the command for thebrowser-extensionproject
And then "special" commands:
elm:book: launch elm-book, the design system for Elm
npm run elm:bookto launch the Elm design system
- Install Stripe CLI and login with
stripe login - Run
stripe listen --forward-to localhost:4000/webhook/stripe - Copy your webhook signing secret to your
.env, it's look like (whsec_XXX) - Go to your Stripe dashboard to obtain your API Key and copy it into
STRIPE_API_KEYin your.envfile.
When testing interactively, use a card number, such as 4242 4242 4242 4242. Enter the card number in the Dashboard or in any payment form.
Use a valid future date, such as 12/34.
Use any three-digit CVC like 123 (four digits for American Express cards).
Use any value you like for other form fields.
See more in the stripe testing documentation
- Production & Staging
- Error logs with Sentry
- Design using TailwindCSS Framework
- Credo for static code analysis (automatically run with pre-commit)
The tool is available as open source under the terms of the MIT License.



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")