Potato leaf disease classification using VGG-16 is a cutting-edge application of deep learning technology in agriculture. VGG-16 is a powerful convolutional neural network (CNN) architecture that has shown remarkable success in image classification tasks. In this context, VGG-16 is trained to identify and classify various types of potato leaf diseases based on the visual patterns and characteristics present in leaf images. By leveraging its deep learning capabilities, VGG-16 can accurately distinguish between different diseases such as late blight, early blight, helping farmers and researchers make informed decisions about disease management and crop protection. This innovative approach holds great promise for enhancing crop yield and reducing losses in potato farming.
Step 1: Get kaggle.json from your kaggle account. profile>account>create new token. kaggle.json file will be downloaded
Step 2: Run following commands
! pip install -q kaggle
from google.colab import files
files.upload()
! mkdir ~/.kaggle
! cp kaggle.json ~/.kaggle/
! chmod 600 ~/.kaggle/kaggle.json
! kaggle datasets list
Step 3: Upload kaggle.json file on Google Colab
Step 4: Run following commands
!kaggle datasets download -d muhammadardiputra/potato-leaf-disease-dataset
Step 5:
!unzip potato-leaf-disease-dataset.zip
Download directly from: https://www.kaggle.com/datasets/muhammadardiputra/potato-leaf-disease-dataset
The data consits of potato leaf images divided into 3 classes [potato_early_blight , potato_late_blight, potato_healthy]. Each image is of size 256 x 256 x 3
(height, width, channels[RGB]) Note: This is for reprensentation purpose only not a real image
Image 1:
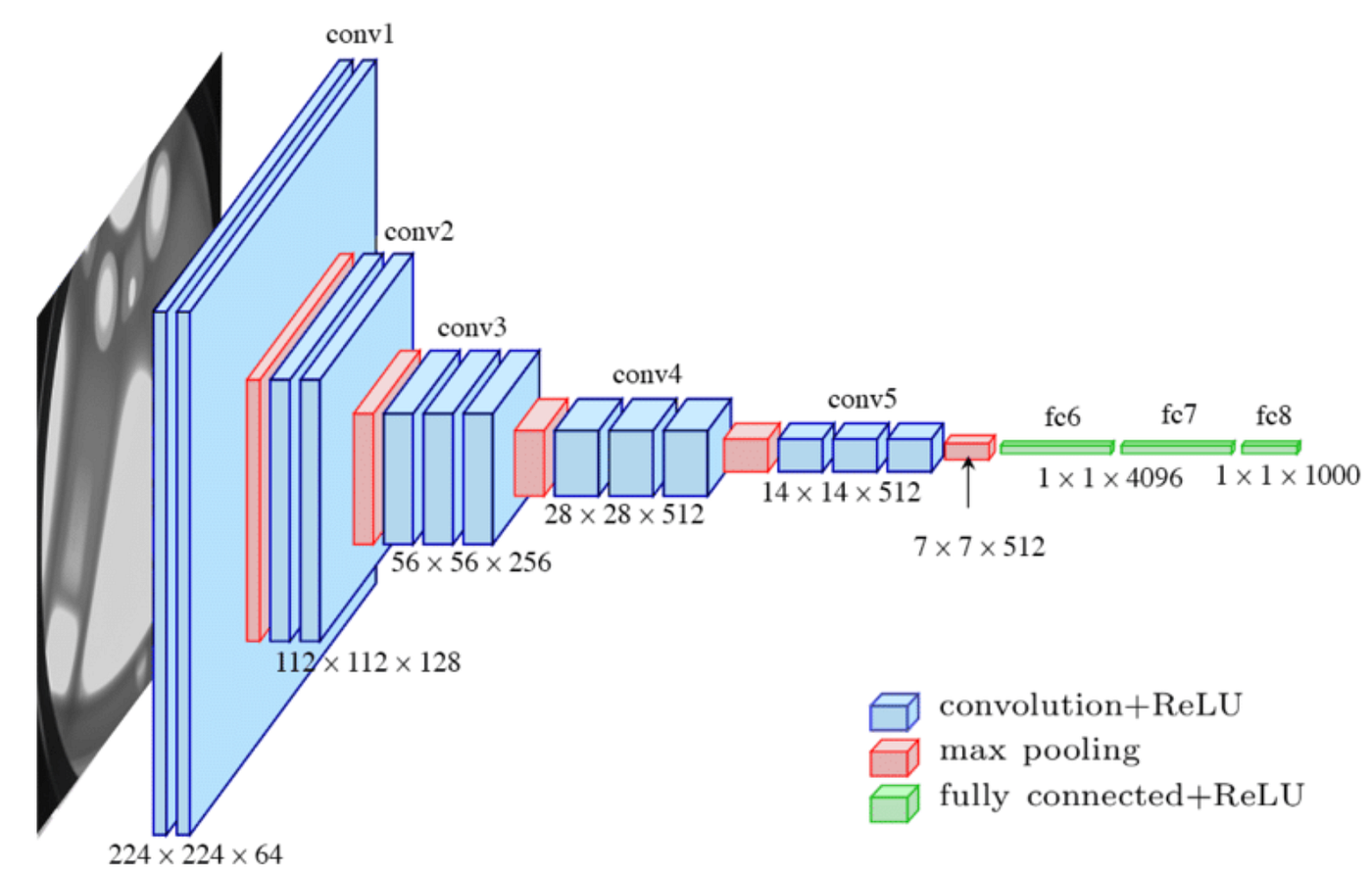
VGG16 is a convolutional neural network (CNN) that is 16 layers deep. It was developed by the Visual Geometry Group (VGG) at the University of Oxford in 2014. VGG16 is one of the most popular CNN architectures for image classification. It has been used to achieve state-of-the-art results on a variety of image classification benchmarks, including the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
The VGG16 architecture consists of 16 convolutional layers and 3 fully connected layers. The convolutional layers use a 3x3 kernel size and a stride of 1 pixel. The first 13 convolutional layers use a padding of 1 pixel, while the last 3 convolutional layers use a padding of 0 pixels. The fully connected layers have 4096 neurons each.
VGG16 is a very deep CNN, which means that it has a large number of parameters to learn. This makes it computationally expensive to train, but it also allows the network to learn more complex features from the images.
VGG16 can be used for a variety of image classification tasks, including object detection, face recognition, and scene classification. It can also be used for image segmentation and image retrieval.
Here are some of the key features of VGG16:
- It is a deep CNN with 16 layers.
- It uses a 3x3 kernel size and a stride of 1 pixel for the convolutional layers.
- It has a padding of 1 pixel for the first 13 convolutional layers and a padding of 0 pixels for the last 3 convolutional layers.
- It has 4096 neurons in each of the fully connected layers.
- It is a very powerful image classification model that can achieve state-of-the-art results on a variety of benchmarks.
Total params: 23,104,323
Trainable params: 23,104,323
Non-trainable params: 0
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
