![]()
![]()


Examples | Docs | Installation | API Reference | Contributing | Contact
The following example uses xlogit to estimate a mixed logit model for choices of electricity supplier (See the data here). The parameters are:
X: 2-D array of input data (in long format) with choice situations as rows, and variables as columnsy: 1-D array of choices (in long format)varnames: List of variable names that matches the number and order of the columns inXalts: 1-D array of alternative indexes or an alternatives listids: 1-D array of the ids of the choice situationspanels: 1-D array of ids for panel formationrandvars: dictionary of variables and their mixing distributions ("n"normal,"ln"lognormal,"t"triangular,"u"uniform,"tn"truncated normal)
The current version of xlogit only supports input data in long format.
# Read data from CSV file
import pandas as pd
df = pd.read_csv("examples/data/electricity_long.csv")
# Fit the model with xlogit
from xlogit import MixedLogit
varnames = ['pf', 'cl', 'loc', 'wk', 'tod', 'seas']
model = MixedLogit()
model.fit(X=df[varnames],
y=df['choice'],
varnames=varnames,
ids=df['chid'],
panels=df['id'],
alts=df['alt'],
n_draws=600,
randvars={'pf': 'n', 'cl': 'n', 'loc': 'n',
'wk': 'n', 'tod': 'n', 'seas': 'n'})
model.summary()GPU processing enabled.
Optimization terminated successfully.
Current function value: 3888.413414
Iterations: 46
Function evaluations: 51
Gradient evaluations: 51
Estimation time= 2.6 seconds
----------------------------------------------------------------------
Coefficient Estimate Std.Err. z-val P>|z|
----------------------------------------------------------------------
pf -0.9996286 0.0331488 -30.1557541 9.98e-100 ***
cl -0.2355334 0.0220401 -10.6865870 1.97e-22 ***
loc 2.2307891 0.1164263 19.1605300 5.64e-56 ***
wk 1.6251657 0.0918755 17.6887855 6.85e-50 ***
tod -9.6067367 0.3112721 -30.8628296 2.36e-102 ***
seas -9.7892800 0.2913063 -33.6047603 2.81e-112 ***
sd.pf 0.2357813 0.0181892 12.9627201 7.25e-31 ***
sd.cl 0.4025377 0.0220183 18.2819903 2.43e-52 ***
sd.loc 1.9262893 0.1187850 16.2166103 7.67e-44 ***
sd.wk -1.2192931 0.0944581 -12.9083017 1.17e-30 ***
sd.tod 2.3354462 0.1741859 13.4077786 1.37e-32 ***
sd.seas -1.4200913 0.2095869 -6.7756668 3.1e-10 ***
----------------------------------------------------------------------
Significance: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Log-Likelihood= -3888.413
AIC= 7800.827
BIC= 7847.493For more examples of xlogit see this Jupyter Notebook in Google Colab. Google Colab provides GPU resources for free, which will significantly speed up your model estimation using xlogit.
Install xlogit using pip as follows:
pip install xlogitHint
To enable GPU processing, you must install the CuPy Python library. When xlogit detects that CuPy is properly installed, it switches to GPU processing without any additional setup. If you use Google Colab, CuPy is usually installed by default.
For additional installation details check xlogit installation instructions at: https://xlogit.readthedocs.io/en/latest/install.html
xlogit can also be used without a GPU. However, if you need to speed up your model estimation, there are several low cost and even free options to access cloud GPU resources. For instance:
- Google Colab offers free GPU resources with no setup required, as the service can be accessed using a web browser. Using xlogit in Google Colab is very easy as it runs out of the box without having to to install CUDA or CuPy, which are installed by default. For examples of xlogit running in Google Colab see this link.
- Amazon Sagemaker Studio Lab offers Python runtime environments with free GPUs.
- Google Cloud platform offers GPU processing at less than $1 USD per hour for NVIDIA Tesla K80 GPU with 4,992 CUDA cores.
- Amazon Sagemaker offers virtual machine instances with the same TESLA K80 GPU at a similar price range of less than $1 USD per hour.
As shown in the plots below, xlogit is significantly faster than existing estimation packages. Also, xlogit provides convenient scaling when the number of random draws increases. These results were obtained using a modest and low-cost NVIDIA GTX 1060 graphics card. More sophisticated graphics cards are expected to provide even faster estimation times. For additional details about this benchmark and for replication instructions check https://xlogit.readthedocs.io/en/latest/benchmark.html.
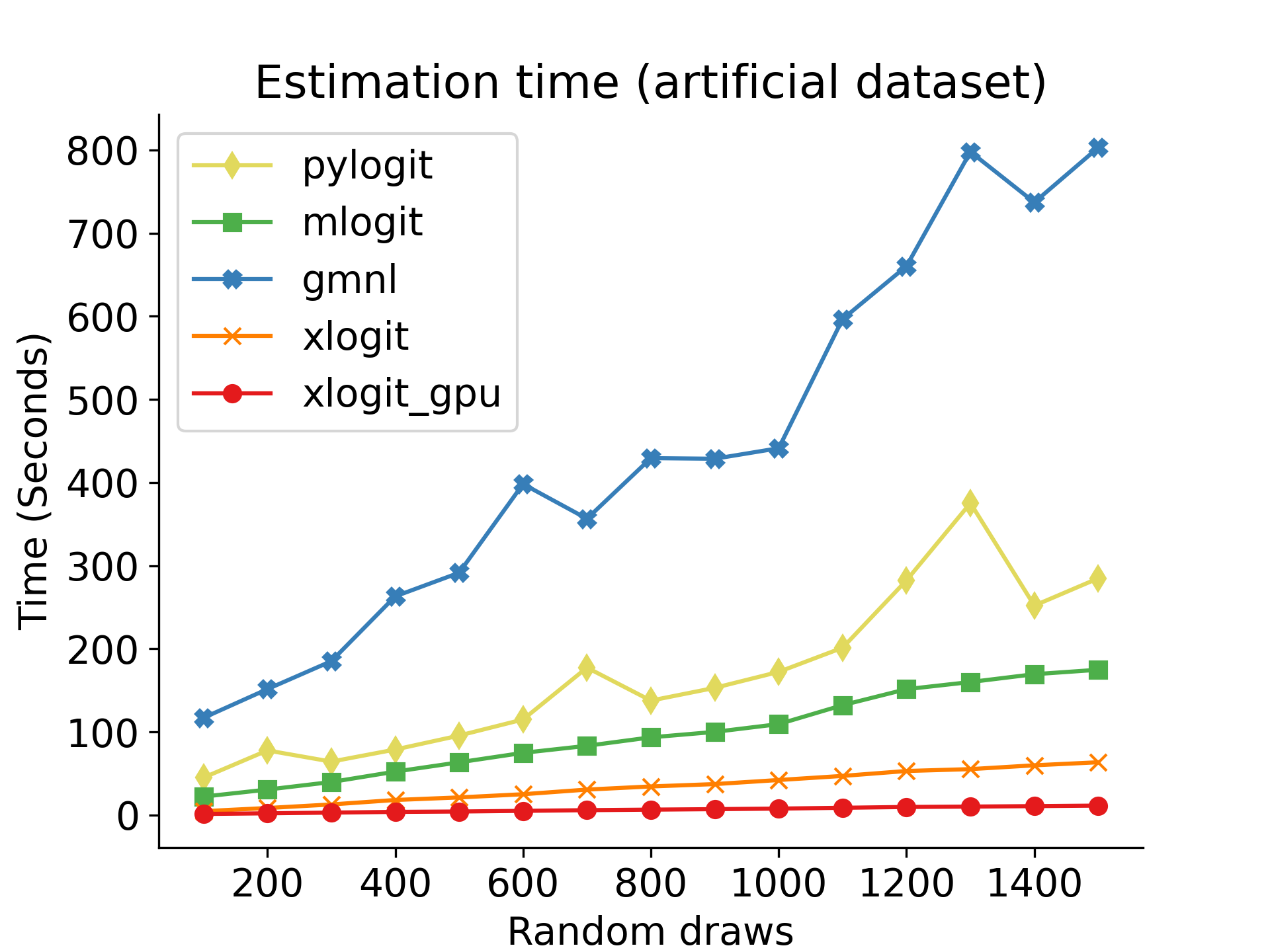
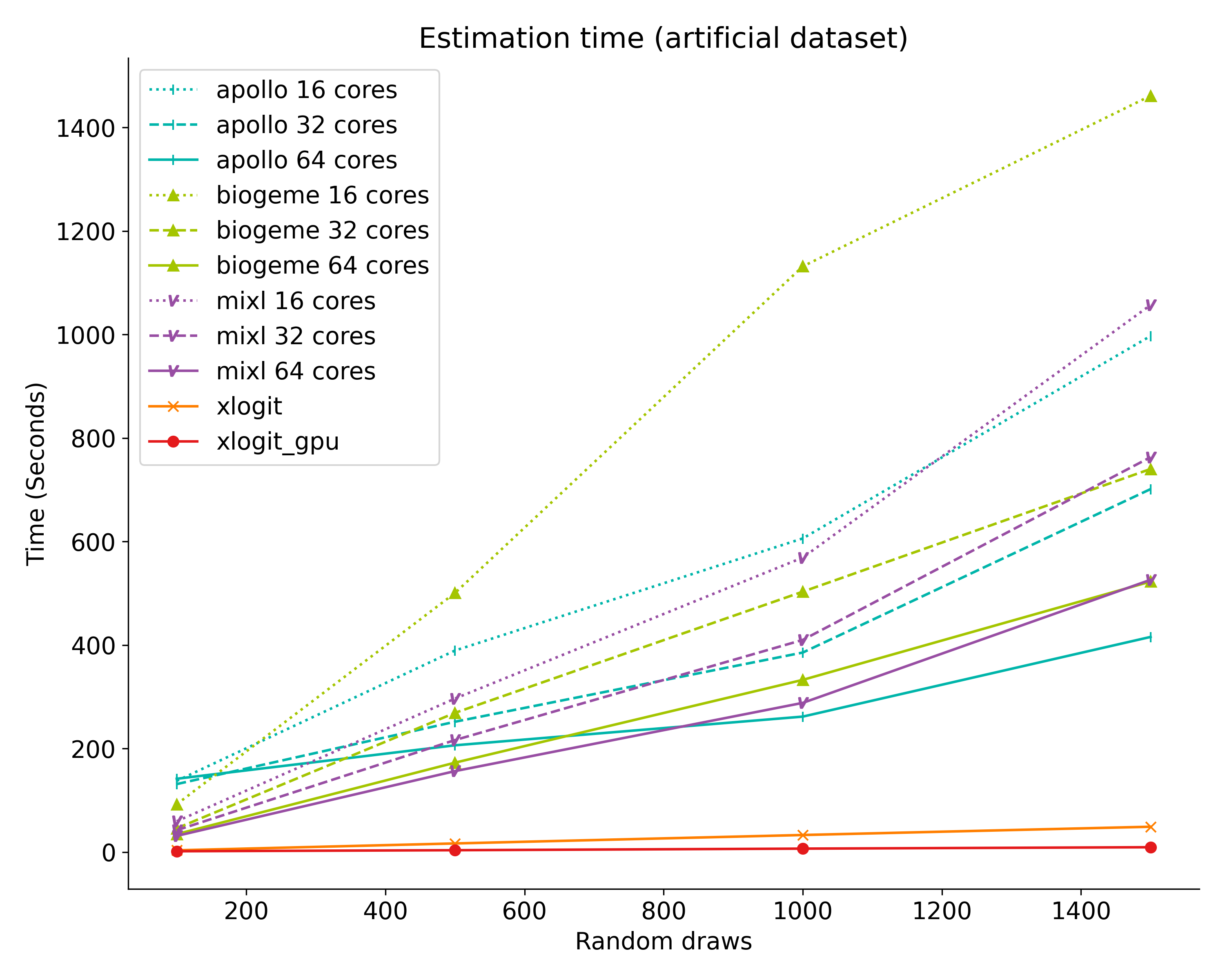
The current version allows estimation of:
- Mixed Logit with several types of mixing distributions (normal, lognormal, triangular, uniform, and truncated normal)
- Mixed Logit with panel data
- Mixed Logit with unbalanced panel data
- Mixed Logit with Halton draws
- Multinomial Logit models
- Conditional logit models
- WTP space models
- Handling of unbalanced availability of choice alternatives for all of the supported models
- Post-estimation tools for prediction and specification testing
- Inclusion of sample weights for all of the supported models
The following contributors have tremendously helped in the enhancement and expansion of xlogit's features.
- @crforsythe
- John Helveston (@jhelvy)
If you have any questions, ideas to improve xlogit, or want to report a bug, chat with us on gitter or open a new issue in xlogit's GitHub repository.
Please cite xlogit as follows:
Arteaga, C., Park, J., Beeramoole, P. B., & Paz, A. (2022). xlogit: An open-source Python package for GPU-accelerated estimation of Mixed Logit models. Journal of Choice Modelling, 42, 100339. https://doi.org/10.1016/j.jocm.2021.100339
Or using BibTex as follows:
@article{xlogit,
title = {xlogit: An open-source Python package for GPU-accelerated estimation of Mixed Logit models},
author = {Cristian Arteaga and JeeWoong Park and Prithvi Bhat Beeramoole and Alexander Paz},
journal = {Journal of Choice Modelling},
volume = {42},
pages = {100339},
year = {2022},
issn = {1755-5345},
doi = {https://doi.org/10.1016/j.jocm.2021.100339},
}























































