A fast matrix library with GPU support.
Three components in the file:
- CL_Base : contains most openCL operations in a simple class
- Matrix : includes matrix manipulation using OpenCL
- SMatrix : a simple matrix for competency test, use expression templates to alleviate workload
OPENCL required. It contains most OpenCL environment object:
cl_platform_idcl_device_idcl_contextcl_command_queuecl_program
I declare one initailized static object in the ww_clwrapper namespace. Users only need to config what device they need and kernel code to compile.
Here is one simple example to config this object:
ww_clwrapper::_clconfig.init("gpu", 0, 0);
ww_clwrapper::_clconfig.create_program(FILE_NAME);
After this config finish, users can access openCL through ww_clwrapper::_clconfig object.
I used two layer implementation as boost::ublas library.
I designed one Storage class for holding actual data elements. this design is similar to bounded_array and unbounded_array in ublas but has less functionality.
| Storage member | type | description |
|---|---|---|
| _clconfig | static CL_Base | static type, includes environment objects |
| _val_array | shared_ptr<T[]> | use shared_ptr to manage resources and provide move semantics to allow fast data transformation |
| _buffer | mutable cl_mem | buffer inside matrix |
| _buffer_available | bool | records buffer usage, return true after create buffer, destructor needs to check it |
| _row_size | size_t | row size |
| _col_size | size_t | column size |
Storage class can access elements using Storage a(i,j). and all its other interface will be the same as other matrix class.
Matrix class is like a higher wrapper for Storage, it includes all interface Storage have and composite it as its member.
template<typename T, typename Expr = Storage<T>>
class Matrix {
typedef Expr expression_type;
...
expression_type _expr;
template<typename T2, typename Expr>
Matrix& operator= (Matrix<T2, Expr> const & other)
{
pass_val(other, ww_traits::__traits<Expr>::_copy_move());
return *this;
}
};
There is one pass_val function inside can instantiate different version of code to pass the left matrix. If the other matrix contains a temp storage, this will call the move constructor to efficiently pass data. However, if the matrix supports lazy evaluation, which means it must be passed through one iteration, it will choose the second version.
template<typename T2, typename Expr2>
void pass_val(Matrix<T2, Expr2> const & other, ww_traits::_true_type)
{
_expr = other.rep().rep();
}
//every template parameter name can only instaintiated once
template<typename T3, typename Expr3>
void pass_val(Matrix<T3, Expr3> const & other, ww_traits::_false_type)
{
size_t row_num = other.rw_size();
size_t col_num = other.cl_size();
for (size_t i = 0; i < row_num; i++)
{
for (size_t j = 0; j < col_num; j++)
{
_expr(i, j) = other(i, j);
}
}
}
This class implements the add expression for lazy evalution, it supports interfaces for Matrix class. (But actually, this class behaves terrible in terms of computing speed).
I use Intel corei7-7700HQ processor to record the speed adding two matrix a and b. With the change of their size, their completion time and computing power can be summarized with following picture. For here, matrix size means the length of row or col, and both matrix are square matrix.
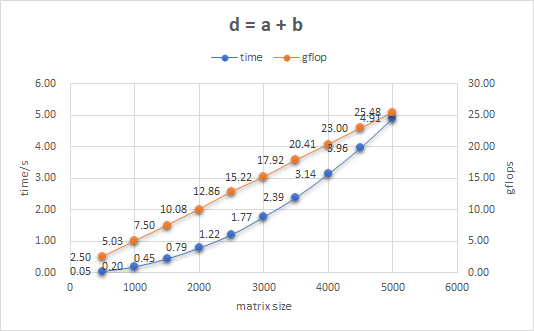
The supporting claim for expression template is that when optimized by compiler, the code can unroll different loop and achieve code like this:
e = a + b + c + d
for (size_t i = 0; i < row; i++) {
for (size_t j = 0; j < col; j++) {
e(i,j) = a(i,j) + b(i,j) + c(i,j) + d(i,j);
}
}
And I also test its behavior with five matrix:
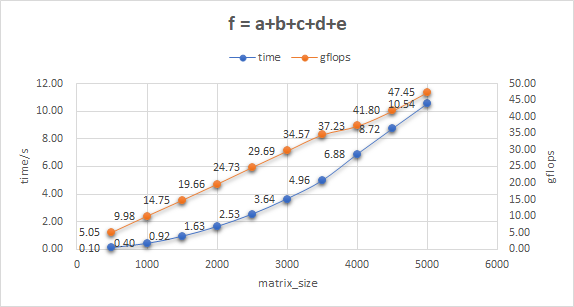
In terms of computing power, it truly helps to improve gflops but as for computing time, this can be a bit long.
If we want to use GPU, there must be two "real" matrixs, since we cannot send expression to GPU. There are main two issues for this matrix: (1) expression must convert to true matrix (2) matrix padding
The first issue requires evaluate previous expression and store its result. I wrote one template copy construction to achieve this. And Matrix_Mult_gpu contains three data : Matrix<T> _lhs, Matrix<T> _rhs and Matrix<T> _ret.
After the initialization, it will call openCL interface to achieve matrix multification and store the result in Matrix<T> _ret.
The second issue is the design of kernel code, I wrote three kernel functions:
__kernel void padding(const int M, const int N,
const int M_Ex, const int N_Ex,
const __global double* input,
__global double* output)
__kernel void return_padding(const int M_Ex, const int N_Ex,
const int M, const int N,
const __global double* input,
__global double* output)
__kernel void core(const int M, const int N, const int K,
const __global double* A,
const __global double* B,
__global double* C)
These three function are able to use tile method in GPU computation for any matrix size. Here is my test result on NVIDIA 1060 GPU:

For addition, since late evaluation can be helpful when matrix size is small, I implemented both version, one for GPU, and another for non-gpu code. The kernel code is simple for addition:
__kernel void add(const int M, const int N,
const __global double* A,
const __global double* B,
__global double* output)
{
const int globalrow = get_global_id(0);
const int globalcol = get_global_id(1);
double tmp = 0.0;
tmp = A[globalcol * M + globalrow] + B[globalcol * M + globalrow];
output[globalcol * M + globalrow] = tmp;
}
Implementation in Matrix_Add_gpu will store temporary variable, and the expression evaluation stage will be fast by just moving points.
Another version is Matrix_Add which solely used expression template, it will store both expressions until the final evaluation stage.
#ifdef USE_GPU
template<typename T, typename OP1, typename OP2>
Matrix<T, Matrix_Add_gpu<T, OP1, OP2>> operator + (Matrix<T, OP1> const & lhs,
Matrix<T, OP2> const & rhs) {
assert(lhs.rw_size() == rhs.rw_size() && lhs.cl_size() == rhs.cl_size());
#ifdef PRINT
printf("Use Matrix_Add_gpu\n");
#endif
return Matrix<T, Matrix_Add_gpu<T, OP1, OP2>>(Matrix_Add_gpu<T, OP1, OP2>(lhs.rep(), rhs.rep()));
}
#else
template<typename T, typename OP1, typename OP2>
Matrix<T, Matrix_Add<T, OP1, OP2>> operator + (Matrix<T, OP1> const & lhs,
Matrix<T, OP2> const & rhs) {
assert(lhs.rw_size() == rhs.rw_size() && lhs.cl_size() == rhs.cl_size());
#ifdef PRINT
printf("Use Matrix_Add\n");
#endif
return Matrix<T, Matrix_Add<T, OP1, OP2>>(Matrix_Add<T, OP1, OP2>(lhs.rep(), rhs.rep()));
}
#endif
We can choose which Matrix addition to use by defining USE_GPU.
SMatrix class is the normal expression template. The expression on the right hand side do not evaluate until calling operator= at left hand side. So there needs to be some middle stage object to store the operation, and find the value at final stage. An optimized compiler can make this process even faster and generate code like this:
e = a + b + c + d
for (size_t i = 0; i < row; i++) {
for (size_t j = 0; j < col; j++) {
e(i,j) = a(i,j) + b(i,j) + c(i,j) + d(i,j);
}
}
Another important point is to implement one operator = which accepts any expression. I did it by:
template<typename T2, typename Expr2>
SMatrix& operator= (SMatrix<T2, Expr2> const & other)
{
_row_size = other.rw_size();
_col_size = other.cl_size();
_expr.resize(_row_size, _col_size, 0);
for (size_t i = 0; i < _row_size; i++) {
for (size_t j = 0; j < _col_size; j++) {
_expr(i,j) = other(i, j);
}
}
return *this;
}
Add operator+ and operator* needs to have special treatment:
template<typename T, typename Expr1, typename Expr2>
SMatrix<T, SMatrix_Add<T, Expr1, Expr2>> operator + (SMatrix<T, Expr1> const & lhs,
SMatrix<T, Expr2> const & rhs) {
assert(lhs.rw_size() == rhs.rw_size() && lhs.cl_size() == rhs.cl_size());
return SMatrix<T, SMatrix_Add<T, Expr1, Expr2>>(SMatrix_Add<T, Expr1, Expr2>(lhs.rep(), rhs.rep()));
}
template<typename T, typename Expr1, typename Expr2>
SMatrix<T, SMatrix_Mul<T, Expr1, Expr2>> operator * (SMatrix<T, Expr1> const & lhs,
SMatrix<T, Expr2> const & rhs) {
assert(lhs.cl_size() == rhs.rw_size());
return SMatrix<T, SMatrix_Mul<T, Expr1, Expr2>>(SMatrix_Mul<T, Expr1, Expr2>(lhs.rep(), rhs.rep()));
}
The purpose of this expression template is to decrease temporary variable but this cannot be done by A = A*B, because this matrix multiplication requires to use the same value multiple times. This can be alleviated by implementing *= operator, but the code will become not easy to write(This problem can be eliminated by using ww_matrix::Matrix class, since most of its operator requires temporary variable).
