ReRead is a desktop based/self-hosted RSS feed reader.
It is a self-contained Java JAR file which only requires a Redis instance with Redis Modules. You can download a ready-to-use binary from Github releases.
Use the following Docker command to have redis running:
docker run -p 6379:6379 redislabs/redismod:latest
- Motivation
- Features
- Screenshots
- Architecture
- Redis modules used
- Issues encountered with Redis
- Redis commands usage
- When server starts up
- Loading the home page
- Adding a new feed
- Importing an OPML file
- Exporting an OPML file
- Crawling a feed
- Marking a post read/unread
- Viewing a feed timeline
- Viewing a folder timeline
- Subscribing a feed
- Subscribing a feed in a folder
- Unsubscribing a feed
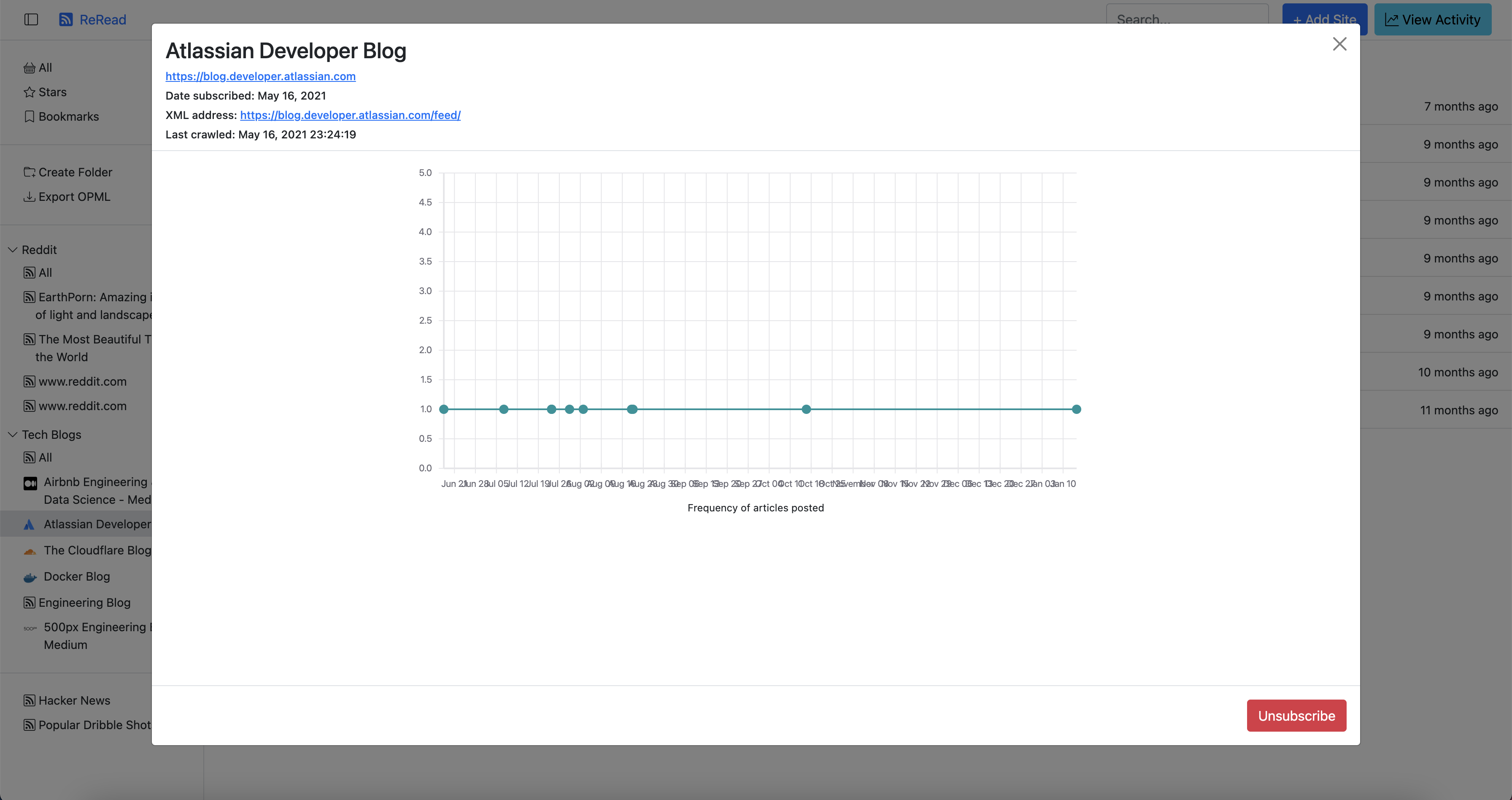
- Viewing feed details
- Viewing activity
- Searching for posts
- Tech Stack
- Deployment
- Hacking
- Improvement ideas
The motivation to develop reread came from my own personal itch. I have 100s of feeds
that I follow but no service currently allows to add all of them in a single free account.
- Feedly
- is limited to 100 sources in free plan
- InoReader
- is limited to 150 sources
- is paid to de-duplicate articles across feeds
- NewsBlur
- is limited to 64 sources
- no search
- FeedSpot
- has no search in free plan
- Winds
- only magazine style layout
- does not allow filtering by read/unread posts
- search does not works (atleast for me)
And last but not the least: PRIVACY. All these sites are ad-supported (which makes sense for free version), but in paid versions too, they are collecting a lot of analytics about the user behavior including the reading pattern. ReRead does not collect any information ensuring privacy.
As I read about the Redis Hackathon I thought it would be a good idea to develop something
that I can use in future as well. And thus was born reread.
ReRead comes with the following features:
- Clean/simple/minimalistic UI
- Discovers RSS/Atom feeds from a given site
- Add RSS/Atom feeds
- Import feeds and folders from an OPML file
- De-dupe posts (with same content) across multiple feeds
- Multiple layouts: cards, masonary, list, magazine, title only
- Sort by oldest/newest posts
- Filter to show only read/unread posts
- Star a post as favorite
- Bookmark a post to read later
- View all star/bookmark posts
- Create new folders
- Categorize feeds into folders
- View statistics as a graph on how frequently a feed posts
- View self reading habits such as how many posts you read every day
ReRead is a classic 3-tiered application, where the web tier connects with the service tier over REST services. All data persistence happens inside Redis. ReRead includes an embedded scheduler that
+-------+ +--------+ +------------+
| React | REST | Java | Redis Protocol | Redis with |
| UI |------------> | Server |-------------------> | modules |
+-------+ +--------+ +------------+
|
| Continual
| polling +------------+
+----------------> | Feed Hosts |
+------------+
ReRead utilizes continual polling for fetching new posts from RSS/Atom feeds. This is limited as there is no easy way of receiving webhooks on http://localhost for feeds with PubSubHubBub enabled.
The code can however be extended to use tunneling via ngrok, localtunnel or otherwise to make use of PubSubHubBub to reduce polling. Note: Not all feeds/sites support hooks and thus polling may still be required.
ReRead does not use authentication on purpose. It is intended for power users who subscribe of hundreds/thousands of feeds and would like to run it locally or self host.
In case of self-hosting, it is preferable to add IP-based restrictions along with BASIC authentication using a front-proxy like Nginx or Caddy Server that will also enable a Let's Encrypt based SSL certificate.
The project uses the following Redis modules for its functionality:
Redis Core used to check existence of keys and for other minor operations based on keys. This is also used to store the posts data due to a bug in the RedisJSON Java driver where it looses encoding of the text.
RedisJSON - this serves as the document store for us. All post data, details on feeds, when they were crawled etc is stored as JSON documents. This allows us fine grained atomic operations such as updating a single field within the document than read/writing the entire document again.
RediSearch - this is used to index and search across all posts. The full-text search built into the UI is powered by it.
RedisTimeSeries - this is used to store the activity behavior of user as well as the publishing behavior of the feeds. Dashboards such as number of posts read per day, per week etc are powered using this module.
RedisBloom - the most useful module of all. This helps us de-duplicate entries not just in the same feed, but also across the board. Thus if you have read the post once, why read it again?
Following is a list of Redis commands used per feature/workflow. Please refer to section on Notes on Security to read why authentication is not baked in.
This is used to show activity graph and serves as the start of universe.
// create startup time
SETNX $reread-start-time {currentSystemTime}
// create search index
FT.CREATE post-search SCHEMA {...fields with weights}
// Get the `FeedList` entity for the user
JSON.GET me {feedList}
// If it does not exist, create one
JSON.SET me . {feedList}
//Next get the first page of `all` timeline for the user
ZREVRANGE timeline:$all 0 {pageSize}
// For each ID get the actual post
GET {postID}
// First the feed is discovered using HTTP call to URL
// once user chooses the feed to be added
// convert the feed to MasterFeed entry
JSON.GET masterFeed:{id}
// if not present, create one
JSON.SET masterFeed:{id} . {masterFeed}
// get the feed list
JSON.GET me {feedList}
// If it does not exist, create one
JSON.PUT me {feedList}
// feed crawling starts
// refer to section on "Feed Crawling" to take a look at its commands
// once feed is crawled
// update the feed list
JSON.SET me . {feedList}
The commands used in this feature are a union of all the commands used in Adding a feed as described above. The extra commands used here are:
// get a list of all feeds in the folder
JSON.GET feedList:me
// now create a merged union store of all timelines
ZUNIONSTORE timeline:{folderID} {feedID1} {feedID2} {feedID3} {feedID4}
I had designed this to use ZDIFFSTORE to remove entries efficiently,
but the command is available starting Redis 6.2.0. However, the redismod
Docker image available on latest head contains Redis 6.0.1.
// get feed list
JSON.GET feedList:me
// read all entries from this timeline
ZRANGE timeline:{feedID} 0 -1
// remove the feed from folder timeline
ZREM timeline:{folderID} {...entries}
// remove the feed entries from all timeline
ZREM timeline:$all {...entries}
// update the feed list
JSON.SET feedList:me . {feedList}
// get feed list
JSON.GET feedList:me
// read all master feeds - this is more of performance improvement
KEYS masterFeed*
GET masterFeed:{masterFeedID}
// check if master feed already exists
// if not create a new master feed
JSON.SET masterFeed:{masterFeedID} . {masterFeed}
JSON.GET feedList:me
This is one of the most complex pieces, which touches all modules of Redis that we use.
// get the master feed
JSON.GET masterFeed:{masterFeedID}
// get previously crawled details
JSON.GET feedCrawlDetails:{feedID}
// crawl the feed here
// once crawled, update details like etag/last modified time
JSON.SET feedCrawlDetails:{feedID} .lastCrawled {currentSystemTime}
JSON.SET masterFeed:{feedID} .title {parsedFeed.title}
JSON.SET masterFeed:{feedID} .siteUrl {parsedFeed.siteUrl}
JSON.SET feedCrawlDetails:{feedID} .lastCrawled {parsedFeed.lastCrawled}
JSON.SET feedCrawlDetails:{feedID} .lastModifiedHeader {parsedFeed.lastModifiedHeader}
JSON.SET feedCrawlDetails:{feedID} .lastModifiedTime {parsedFeed.lastModifiedTime}
JSON.SET feedCrawlDetails:{feedID} .etag {parsedFeed.eTagHeader}
// filter already existing posts
BF.EXISTS bloom:hash {post.hash}
BF.EXISTS bloom:text {post.text}
BF.EXISTS bloom:uniqueID {post.uniqueID}
// now start saving all filtered posts
BF.ADD bloom:hash {post.hash}
BF.ADD bloom:text {post.text}
BF.ADD bloom:uniqueID {post.uniqueID}
// save each post
SET {postID} {post}
// index each post
FT.ADD postSearch {postID} 1 FIELDS {...fields}
// send for analytics
TS.MADD timeseries-feed:{feedID} {post.updated} 1
// update timelines as needed
ZADD timeline:{feedID} {postID} {post.updated}
ZADD timeline:{folderID} {postID} {post.updated}
ZADD timeline:$all {postID} {post.updated}
I was using JSON.GET/JSON.SET but due to an encoding bug in JreJson driver,
I had to using simple GET/SET. Bug has been filed as RedisJSON/JRedisJSON#37
// marking read
SET {postID} {post}
// marking unread
SET {postID} {post}
// when viewing by newest, first page
ZREVRANGE timeline:{feedID} 0 {pageSize}
// when viewing by newest, second page
ZRANK timeline:{feedID} {lastPostID}
ZCARD timeline:{feedID}
ZREVRANGE timeline:{feedID} {card - rank + 1} {card - rank + pageSize}
// when viewing by oldest, first page
ZRANGE timeline:{feedID} 0 {pageSize}
// when viewing by oldest, second page
ZRANK timeline:{feedID} {lastPostID}
ZRANGE timeline:{feedID} {rank + 1} {rank + pageSize}
// when viewing by newest, first page
ZREVRANGE timeline:{folderID} 0 {pageSize}
// when viewing by newest, second page
ZRANK timeline:{folderID} {lastPostID}
ZCARD timeline:{folderID}
ZREVRANGE timeline:{folderID} {card - rank + 1} {card - rank + pageSize}
// when viewing by oldest, first page
ZRANGE timeline:{folderID} 0 {pageSize}
// when viewing by oldest, second page
ZRANK timeline:{folderID} {lastPostID}
ZRANGE timeline:{folderID} {rank + 1} {rank + pageSize}
// get the master feed
JSON.GET masterFeed:{feedID}
// get details about feed when was last crawled
JSON.GET feedCrawlDetails:{feedID}
// get number of total posts
ZRANK timeline:{feedID}
// also get the chart data
ZRANGE timeline:{feedID} 0 0
// get the post
GET post:{postID}
// get analytics
TS.RANGE timeseries-feed:{feedID} {post.updated} {currentSystemTime} COUNT 60000
// read start of reread universe
GET $reread-start-time
// get activity chart data
TS.RANGE timeSeries-activity:{activityID} {rereadStartTime} {currentSystemTime} COUNT 60000
The current Java driver for RedisSearch does not provide an API to query in a specific index which serves as a hindrance. Thus, filtering of posts in the given index is done in the JVM. Refer here and here to see the current driver limitations.
FT.SEARCH {query}
- JDK 11
- Spring Boot
- Redis core and enterprise modules (via Redis docker image)
- Typescript
- React 17
- Bootstrap 5.0
- Apache Maven (for building server)
- NPM/Yarn (for building client)
See [pom.xml] and [package.json] file for a list of all 3rd-party libraries used.
You will need Redis docker image for using Redis enterprise modules. Go over this link to have it ready.
TL;DR: A published JAR is also available for download from Github. You can skip building
the project and directly use it to have reread running on your local machine.
To build and deploy the project, follow the below instructions:
# create the build for the web client
$ cd web-ui
$ npm install
$ npm run build
$ cd ..
# create the build for the server
$ cd server
$ cp -r ../web-ui/dist/* src/main/resources/static
$ mvn clean package
$ cd..
# Start the docker container
$ docker run -d -p 6379:6379 redislabs/redismod
# Start the project
$ java -jar server/target/reread.jarYou can now access the application at http://localhost:1309
reread is 100% hackable from the word go.
The front-end application is written in 100% Typescript and uses React underneath. To make changes to the UI client:
# Install dependencies
$ cd web-ui
$ npm install (or yarn install)
$ npm run watchThis shall start a local development server on http://localhost:1234 where the React application is continuously built and deployed. Open your favorite editor like VSCode, Atom or Sublime Text and start making changes.
The back-end application is written in Java and uses Spring Boot. All custom
beans are defined in SpringBeans.java file. All services are wired to their
implementation using the @Service annotation. Javadocs are mentioned over
the classes as well as methods to indicate what they do. That should help one
get started.
- Improve performance on OPML import - MasterFeed check takes a lot of time
- Allow users to selectively import from OPML
- Add support for podcasts
- Add settings pane to change connection to Redis (currently bound to localhost)
- Add settings to customize layouts, themes, fonts etc
- Use HTTPs proxy to serve images
- Add news sites available in free non-commercial license as mentioned here.

