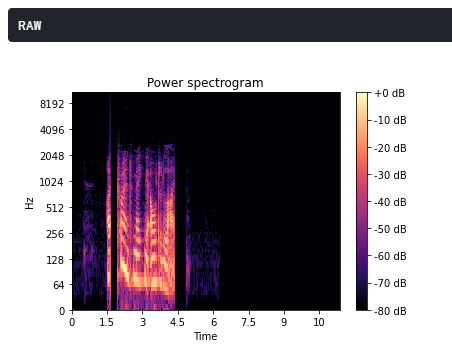
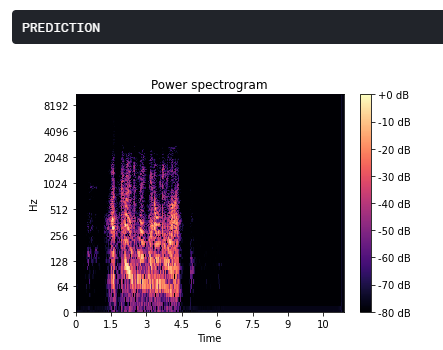
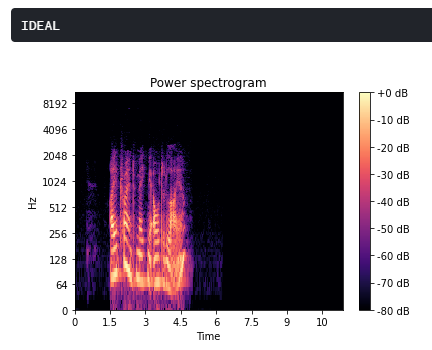
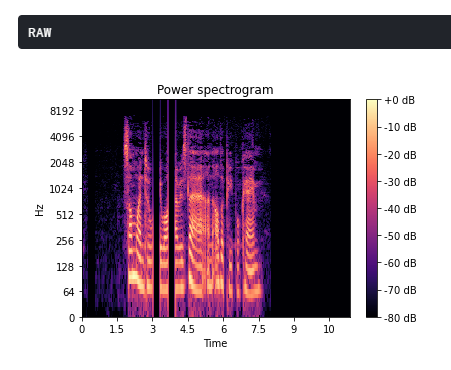
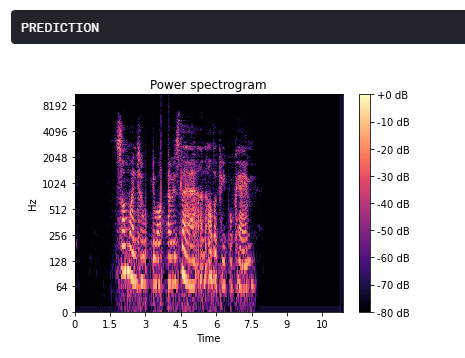
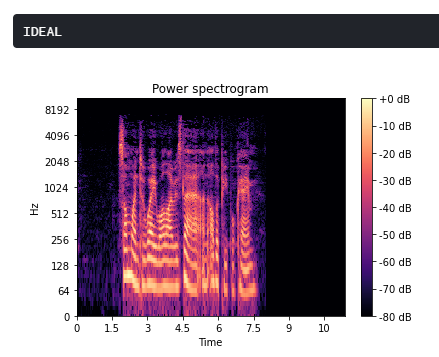
A recorded audio can have gaps in the signal due to various reasons such as faulty microphone or lagging network. Using the concept of Spectral Sound gap filling, the signal is first converted to its short-time Fourier transform. The spectrogram obtained has discernible recesses that are filled by a CNN architecture which takes the spectogram as the input and fills in the gaps. The output spectogram is then transformed back to the audio signal which is smoother and comprehensible.
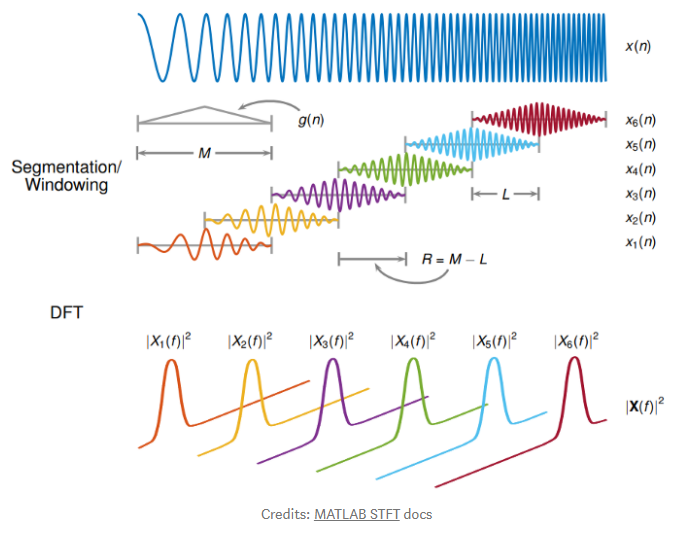
To calculate the STFT of a signal, we need to define a window of length M and a hop size value R. The latter defines how the window moves over the signal. Then, we slide the window over the signal and calculate the discrete Fourier Transform (DFT) of the data within the window. Thus, the STFT is simply the application of the Fourier Transform over different portions of the data. Lastly, we extract the magnitude vectors from the 2048-point STFT vectors and take the first 512-point by removing the remaining points. All this process was done using the Python Librosa library.
Length of window = 2048 samples
Hop length = 2048/4 = 512 samples
Common Voice is a corpus of speech data read by users on the Common Voice website (http://voice.mozilla.org/), and based upon text from a number of public domain sources like user submitted blog posts, old books, movies, and other public speech corpora. Its primary purpose is to enable the training and testing of automatic speech recognition (ASR) systems.
- 12.63 GB
- 16 different english accents
- 9 different age classes
- Pre split into train-test-validation sets
8 blocks of :
- 2D-Convolution
- Batch Normalization
- LeakyRELU activation
stacked sequentially. Input Size: (1025, 489, 1)