The goal of the project is to predict industries using our employer_raw_data and industry_data ITo implement the project, we will learn different approaches to designing an nlp model that will rely on unclassified data. We will discuss the basics of topic classification, unsupervised sentence classification, and vectorization of words.
Throughout this project, we will create the following code/system:
- A prediction pipeline that transforms a company description and predicts its industry.
- Different models design on how to represent and classify information using words.
- Evaluate the performance of our model and understanding the weaknesses and advantages for each of them.
- python
- NumPy
- pandas
- seaborn
- matplotlib
- sys
- string
- regex
- os
- spacy
- nltk
- wordcloud
- scikit-learn
The general workflow used to create the model is:
These preprocessing steps are integral to model performance later on as they improve the quality and interpretability of the dataset. We will apply all the cleaning techniques on the dataset by creating a Regex function and string manipulations. The function will take a string as an input and will return the clean version of it.
We will also include lemmatization and stemming techniques to our dataset
- Step 01: Creating Regex for emails, location, website/URLs
Short for regular expression; a Regex is useful in extracting information from any text by searching for one or more matches of a specific search pattern
Sample of Website/URL Regex def remove_url(text): url_model = re.compile(r'https?://(\w+|www)+.[a-zA-Z]{2,4}') return url_model.sub(r'', text) example = "My college website is http://whittier.edu" print(remove_url(example))
- Step 02: String Operations to remove punctuations and change text to lowercase
Some of our operations were:
```
#Punctuation
def remove_punctuation(text : str):
return text.translate(str.maketrans(' ', ' ', puncts)) if use_punctuation else text
#Alpha
def alpha(text: str):
return re.sub("[^a-zA-Z]+", " ", text) if use_alpha else text
#Lower Case
def lower(text: str):
return text.lower() if use_lower else text
```
- Step 03: Lemmatization and Stemming
We will look into three stemming techniques namely snowball, porter stemmer and ARLStem Stemmer and use them to reduce all words to their stems. We will also perform lemmatization using nltk and spacy library.Unlike stemming, lemmatization reduces words to their base word, reducing the inflected words properly and ensuring that the root word belongs to the language.

- Step 04: Stopwords
We will use NLTK Library to remove stop words by dividing text into words and then remove the word if it exits in the list of stop words provided by NLTK.
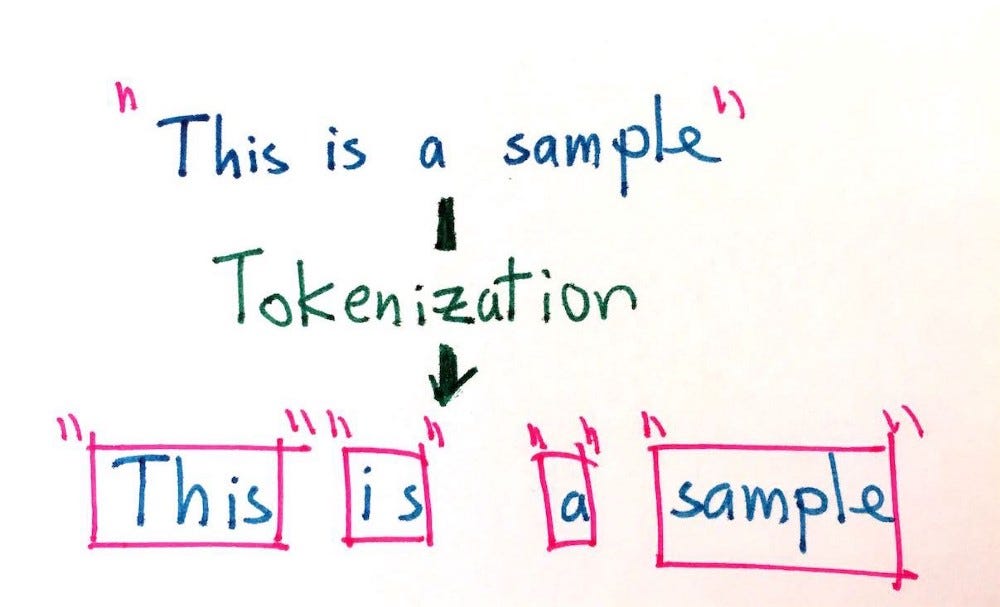
- Step 05: Tokenization
It is basically splitting/segmenting a text into words/sentences. It cuts a text into pieces called tokens.These tokens help in understanding the context and developing the model for the NLP. For this project, We will use word_tokenize to split the text into words.
This image illustrates what tokenization does to a text.
It is easier for any programming language to understand textual data in the form of numerical value. So, for this reason, we need to vectorize all of the text so that it is better represented. We will specifically work with Hashing Vectorizer, TF-IDF and NMF methods to convert our text into numbers.
-
We convert a corpus of documents into numbers to answer questions like:
- What are the prevailing topics in this corpus?
- To what extent is each topic important in each document?
- How well do these extracted topics describe the original document?
- How similar is one document to another?
-
Hashing Vectorizer Using this vectorizer that applies the hashing trick to encode tokens as numerical indexes. The hashing trick turns arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values as indices directly.

-
TFIDF Vector(Term Frequency — Inverse Document Frequency) We need the word counts of all the vocab words and the length of the document to compute TF. In case the term doesn’t exist in a particular document, that particular TF value will be 0 for that particular document. In an extreme case, if all the words in the document are the same, then TF will be 1.
-
NMF(Non-Negative Matrix Factorization) NMF utilizes linear algebra and the concept of matrix multiplication to reduce the features of the document-term matrix to create topics. Our NMF matrix will decompose the document-term matrix into two smaller matrices — The document-topic matrix (U) and the topic-term matrix (W) — each populated with unnormalized probabilities.
This is how it works:

- We will create WordClouds to see which words are the most frequent in a random sentence from the text
A Sample Word Cloud generated from the health industry of the employer's dataset:

We will create models using nmf and wordvectors.
-
For nmf: We will implement the nmf model on the wholde dataset and on top words then compare the results from both.
-
For word vectors: We will create a embeddings representation of each industry using spacy and find the closest industry using doc_1.similarity(industry_1)
The TfidfVectorizer will transform text to feature vectors that can be used as input to estimator.
We will then pick top words from the tfidf and use them to find the industry with the highest similarity to each employer.
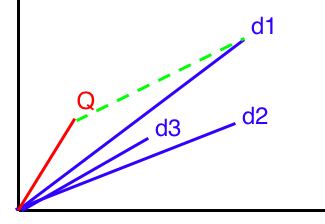
What cosine similarly does is that it will mark all the documents as vectors of tf-idf tokens and measures the similarity in cosine space (the angle between the vectors).
Since we are implementing unsupervised learning techniques, we cannot evaluate our model using evaluation metrics.
Instead we will analyze the model by creating visual bar graphs that show the frequency distribution of industries in the data set
From the bar plot, we expect to see the predicted industries to be fairly distributed amongst the employers.
We will also select random samples from the employer dasaset and see if their predicted industries closely match their real industries.
If there's a close match, then our model is efficient.
Below is an Image of the Industry Prediction using nmf on the whole dataset

