Live demo | Documentation | Website
Just looking to test out SkillNer? Check out our demo.
SkillNer is an NLP module to automatically Extract skills and certifications from unstructured job postings, texts, and applicant's resumes.
Skillner uses EMSI databse (an open source skill database) as a knowldge base linker to prevent skill duplications.

It is easy to get started with SkillNer and take advantage of its features.
- First, install SkillNer through the
pip
pip install skillNer- Next, run the following command to install
spacy en_core_web_lgwhich is one of the main plugins of SkillNer. Thanks to its modular nature, you can customize SkillNer behavior just by adjusting | plugin | unplugin modules. Don't worry about these details, we will discuss them in detail in the upcoming Tutorial section.
python -m spacy download en_core_web_lgNote: The later installation will take a few seconds before it gets done since spacy en_core_web_lg is a bit too large (800 MB). Yet, you need to wait only one time.
With these initial steps being accomplished, let’s dive a bit deeper into skillNer through a worked example.
Let’s say you want to extract skills from the following job posting:
“You are a Python developer with a solid experience in web development and can manage projects.
You quickly adapt to new environments and speak fluently English and French”
We start first by importing modules, particularly spacy and SkillExtractor. Note that if you are using skillNer for the first time, it might take a while to download SKILL_DB.
SKILL_DB is SkillNer default skills database. It was built upon EMSI skills database .
# imports
import spacy
from spacy.matcher import PhraseMatcher
# load default skills data base
from skillNer.general_params import SKILL_DB
# import skill extractor
from skillNer.skill_extractor_class import SkillExtractor
# init params of skill extractor
nlp = spacy.load("en_core_web_lg")
# init skill extractor
skill_extractor = SkillExtractor(nlp, SKILL_DB, PhraseMatcher)
# extract skills from job_description
job_description = """
You are a Python developer with a solid experience in web development
and can manage projects. You quickly adapt to new environments
and speak fluently English and French
"""
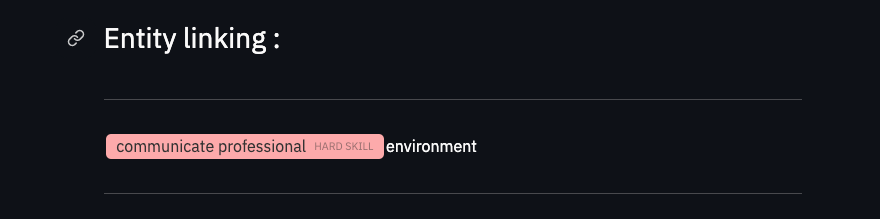
annotations = skill_extractor.annotate(job_description)Voilà! Now you can inspect results by rendering the text with the annotated skills.
You can achieve that through the .describe method. Note that the output of this method is
literally an HTML document that gets rendered in your notebook.

Besides, you can use the raw result of the annotations.
Below is the value of the annotations variable from the code above.
# output
{
'text': 'you are a python developer with a solid experience in web development and can manage projects you quickly adapt to new environments and speak fluently english and french',
'results': {
'full_matches': [
{
'skill_id': 'KS122Z36QK3N5097B5JH',
'doc_node_value': 'web development',
'score': 1, 'doc_node_id': [10, 11]
}
], '
ngram_scored': [
{
'skill_id': 'KS125LS6N7WP4S6SFTCK',
'doc_node_id': [3],
'doc_node_value': 'python',
'type': 'fullUni',
'score': 1,
'len': 1
},
# the other annotated skills
# ...
]
}
}SkillNer is the first Open Source skill extractor. Hence it is a tool dedicated to the community and thereby relies on its contribution to evolve.
We did our best to adapt SkillNer for usage and fixed many of its bugs. Therefore, we believe its key features make it ready for a diversity of use cases. However, it still has not reached 100% stability. SkillNer needs the assistance of the community to be adapted further and broaden its usage.
You can contribute to SkillNer either by
-
Reporting issues. Indeed, you may encounter one while you are using SkillNer. So do not hesitate to mention them in the issue section of our GitHub repository. Also, you can use the issue as a way to suggest new features to be added.
-
Pushing code to our repository through pull requests. In case you fixed an issue or wanted to extend SkillNer features.
-
A third (friendly and not technical) option to contribute to SkillNer will be soon released. So, stay tuned...
Finally, make sure to read carefully our guidelines before contributing. It will specify standards to follow so that we can understand what you want to say.
Besides, it will help you setup SkillNer on your local machine, in case you are willing to push code.
- Visit our website to learn about SkillNer features, how it works, and particularly explore our roadmap
- Get started with SkillNer and get to know its API by visiting the Documentation
- Test our Demo to see some of SkillNer capabilities