aiforsec / cyner Goto Github PK
View Code? Open in Web Editor NEWCyber Security concepts extracted from unstructured threat intelligence reports using Named Entity Recognition
License: MIT License
Cyber Security concepts extracted from unstructured threat intelligence reports using Named Entity Recognition
License: MIT License













































































For me, the model isn't working as intended.
For the input
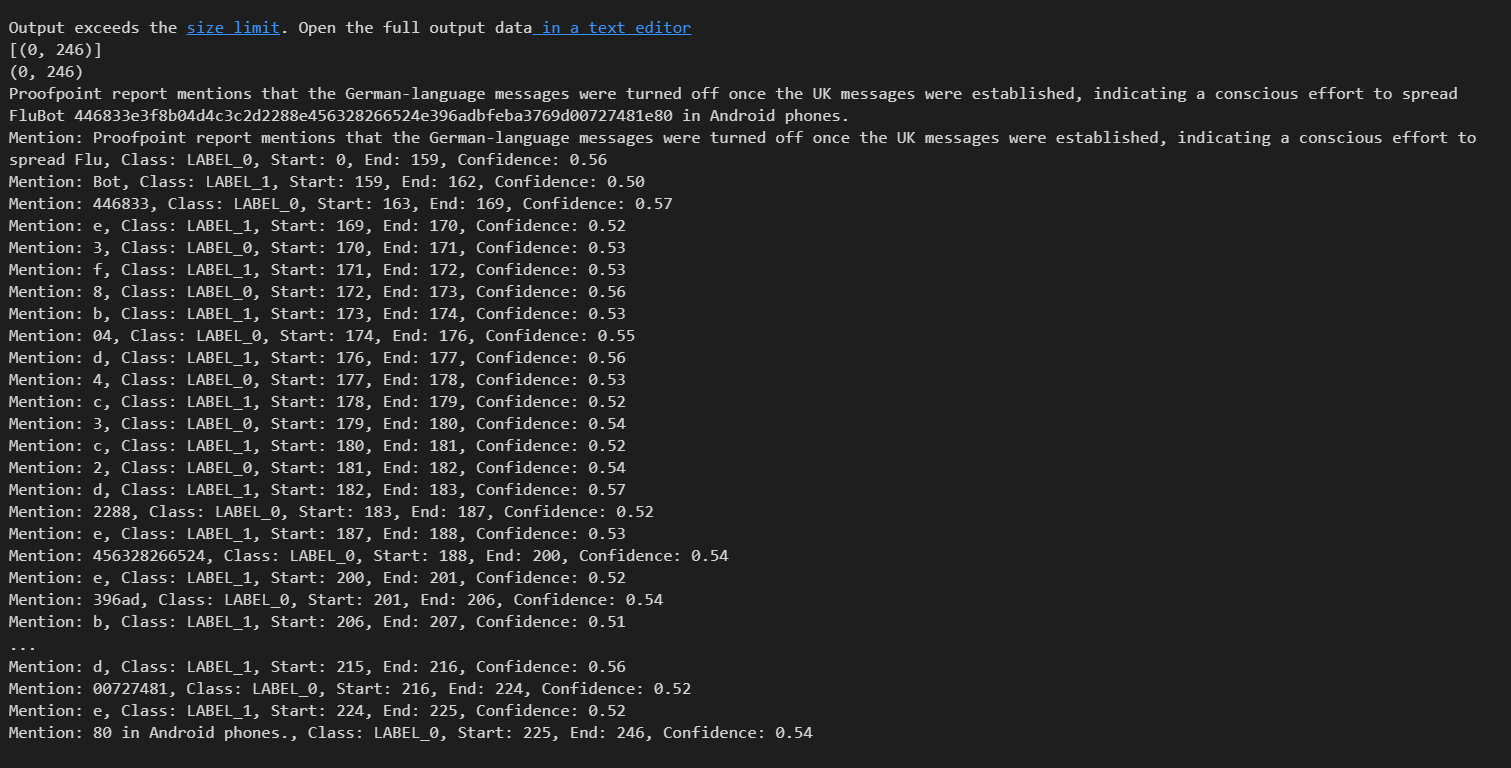
text2 = "Proofpoint report mentions that the German-language messages were turned off once the UK messages were established, indicating a conscious effort to spread FluBot 446833e3f8b04d4c3c2d2288e456328266524e396adbfeba3769d00727481e80 in Android phones."
I get the following output:
Mention: Proofpoint report mentions that the German-language messages were turned off once the UK messages were established, indicating a conscious effort to spread FluBot 446833e3f8b04d4c3c2d2288e456328266524e396adbfeba3769d00727481e80 in Android phones., Class: LABEL_1, Start: 0, End: 246, Confidence: 0.62
Problem 1:
The whole text is labeled as one entity.
For bigger text, multiple big sections are detected.
Problem 2:
Not the original labels but Label_1 is returned.
From the CyNER Demo.ipynb I have tried to train the model but I get this error.
# Training Code
cfg = {'checkpoint_dir': '.ckpt',
'dataset': 'dataset/mitre',
'transformers_model': 'xlm-roberta-large',
'lr': 5e-6,
'epochs': 20,
'max_seq_length': 128}
model = cyner.TransformersNER(cfg)
model.train()Output
2022-06-08 12:52:49 INFO *** initialize network ***
2022-06-08 12:52:50 INFO create new checkpoint
2022-06-08 12:52:50 INFO checkpoint: .ckpt
2022-06-08 12:52:50 INFO - [arg] dataset: dataset/mitre
2022-06-08 12:52:50 INFO - [arg] transformers_model: xlm-roberta-base
2022-06-08 12:52:50 INFO - [arg] random_seed: 1
2022-06-08 12:52:50 INFO - [arg] lr: 5e-06
2022-06-08 12:52:50 INFO - [arg] epochs: 20
2022-06-08 12:52:50 INFO - [arg] warmup_step: 0
2022-06-08 12:52:50 INFO - [arg] weight_decay: 1e-07
2022-06-08 12:52:50 INFO - [arg] batch_size: 32
2022-06-08 12:52:50 INFO - [arg] max_seq_length: 128
2022-06-08 12:52:50 INFO - [arg] fp16: False
2022-06-08 12:52:50 INFO - [arg] max_grad_norm: 1
2022-06-08 12:52:50 INFO - [arg] lower_case: False
2022-06-08 12:52:50 INFO target dataset: ['dataset/mitre']
2022-06-08 12:52:50 INFO data_name: dataset/mitre
2022-06-08 12:52:50 INFO formatting custom dataset from dataset/mitre
2022-06-08 12:52:50 INFO found following files: {'test': 'test.txt', 'train': 'train.txt', 'valid': 'valid.txt'}
2022-06-08 12:52:50 INFO note that files should be named as either `valid.txt`, `test.txt`, or `train.txt`
2022-06-08 12:52:50 INFO dataset dataset/mitre/test.txt: 747 entries
2022-06-08 12:52:50 INFO dataset dataset/mitre/train.txt: 2810 entries
2022-06-08 12:52:50 INFO dataset dataset/mitre/valid.txt: 812 entries
Some weights of the model checkpoint at xlm-roberta-base were not used when initializing XLMRobertaForTokenClassification: ['lm_head.layer_norm.weight', 'lm_head.dense.weight', 'lm_head.bias', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'lm_head.dense.bias']
- This IS expected if you are initializing XLMRobertaForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing XLMRobertaForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of XLMRobertaForTokenClassification were not initialized from the model checkpoint at xlm-roberta-base and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
Input In [2], in <cell line: 8>()
1 cfg = {'checkpoint_dir': '.ckpt',
2 'dataset': 'dataset/mitre',
3 'transformers_model': 'xlm-roberta-large',
4 'lr': 5e-6,
5 'epochs': 20,
6 'max_seq_length': 128}
7 model = cyner.TransformersNER(cfg)
----> 8 model.train()
File ~/Documents/Projects/Blog_Data_Extraction/prototype/test_CyNER/CyNER/cyner/transformers_ner.py:52, in TransformersNER.train(self)
34 cache_dir = config.get('cache_dir', None)
36 trainer = TrainTransformersNER(checkpoint_dir=checkpoint_dir,
37 dataset=dataset,
38 transformers_model=transformers_model,
(...)
49 num_worker=num_worker,
50 cache_dir=cache_dir)
---> 52 trainer.train(monitor_validation=True)
File ~/Documents/Projects/Blog_Data_Extraction/prototype/test_CyNER/CyNER/cyner/tner/model.py:292, in TrainTransformersNER.train(self, monitor_validation, batch_size_validation, max_seq_length_validation)
290 if self.args.is_trained:
291 logging.warning('finetuning model, that has been already finetuned')
--> 292 self.__setup_model_data(self.args.dataset, self.args.lower_case)
293 writer = SummaryWriter(log_dir=self.args.checkpoint_dir)
295 data_loader = {'train': self.__setup_loader('train', self.args.batch_size, self.args.max_seq_length)}
File ~/Documents/Projects/Blog_Data_Extraction/prototype/test_CyNER/CyNER/cyner/tner/model.py:155, in TrainTransformersNER.__setup_model_data(self, dataset, lower_case)
145 config = transformers.AutoConfig.from_pretrained(
146 self.args.transformers_model,
147 num_labels=len(self.label_to_id),
148 id2label=self.id_to_label,
149 label2id=self.label_to_id,
150 cache_dir=self.cache_dir)
152 self.model = transformers.AutoModelForTokenClassification.from_pretrained(
153 self.args.transformers_model, config=config)
--> 155 self.transforms = Transforms(self.args.transformers_model, cache_dir=self.cache_dir)
157 # optimizer
158 no_decay = ["bias", "LayerNorm.weight"]
File ~/Documents/Projects/Blog_Data_Extraction/prototype/test_CyNER/CyNER/cyner/tner/tokenizer.py:38, in Transforms.__init__(self, transformer_tokenizer, cache_dir)
36 def __init__(self, transformer_tokenizer: str, cache_dir: str = None):
37 """ NER specific transform pipeline """
---> 38 self.tokenizer = transformers.AutoTokenizer.from_pretrained(transformer_tokenizer, cache_dir=cache_dir)
39 self.pad_ids = {"labels": PAD_TOKEN_LABEL_ID, "input_ids": self.tokenizer.pad_token_id, "__default__": 0}
40 self.prefix = self.__sp_token_prefix()
File ~/anaconda3/envs/blogsIntel/lib/python3.9/site-packages/transformers/models/auto/tokenization_auto.py:546, in AutoTokenizer.from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
544 tokenizer_class_py, tokenizer_class_fast = TOKENIZER_MAPPING[type(config)]
545 if tokenizer_class_fast and (use_fast or tokenizer_class_py is None):
--> 546 return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
547 else:
548 if tokenizer_class_py is not None:
File ~/anaconda3/envs/blogsIntel/lib/python3.9/site-packages/transformers/tokenization_utils_base.py:1780, in PreTrainedTokenizerBase.from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1777 else:
1778 logger.info(f"loading file {file_path} from cache at {resolved_vocab_files[file_id]}")
-> 1780 return cls._from_pretrained(
1781 resolved_vocab_files,
1782 pretrained_model_name_or_path,
1783 init_configuration,
1784 *init_inputs,
1785 use_auth_token=use_auth_token,
1786 cache_dir=cache_dir,
1787 **kwargs,
1788 )
File ~/anaconda3/envs/blogsIntel/lib/python3.9/site-packages/transformers/tokenization_utils_base.py:1915, in PreTrainedTokenizerBase._from_pretrained(cls, resolved_vocab_files, pretrained_model_name_or_path, init_configuration, use_auth_token, cache_dir, *init_inputs, **kwargs)
1913 # Instantiate tokenizer.
1914 try:
-> 1915 tokenizer = cls(*init_inputs, **init_kwargs)
1916 except OSError:
1917 raise OSError(
1918 "Unable to load vocabulary from file. "
1919 "Please check that the provided vocabulary is accessible and not corrupted."
1920 )
File ~/anaconda3/envs/blogsIntel/lib/python3.9/site-packages/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py:139, in XLMRobertaTokenizerFast.__init__(self, vocab_file, tokenizer_file, bos_token, eos_token, sep_token, cls_token, unk_token, pad_token, mask_token, **kwargs)
123 def __init__(
124 self,
125 vocab_file=None,
(...)
135 ):
136 # Mask token behave like a normal word, i.e. include the space before it
137 mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
--> 139 super().__init__(
140 vocab_file,
141 tokenizer_file=tokenizer_file,
142 bos_token=bos_token,
143 eos_token=eos_token,
144 sep_token=sep_token,
145 cls_token=cls_token,
146 unk_token=unk_token,
147 pad_token=pad_token,
148 mask_token=mask_token,
149 **kwargs,
150 )
152 self.vocab_file = vocab_file
153 self.can_save_slow_tokenizer = False if not self.vocab_file else True
File ~/anaconda3/envs/blogsIntel/lib/python3.9/site-packages/transformers/tokenization_utils_fast.py:109, in PreTrainedTokenizerFast.__init__(self, *args, **kwargs)
106 fast_tokenizer = tokenizer_object
107 elif fast_tokenizer_file is not None and not from_slow:
108 # We have a serialization from tokenizers which let us directly build the backend
--> 109 fast_tokenizer = TokenizerFast.from_file(fast_tokenizer_file)
110 elif slow_tokenizer is not None:
111 # We need to convert a slow tokenizer to build the backend
112 fast_tokenizer = convert_slow_tokenizer(slow_tokenizer)
Exception: EOF while parsing a string at line 1 column 8862550
Unable to pinpoint where the problem is occurring. Could you help me with this?
Thank you.
Setup doesn't resolve nltk:
~/.../site-packages/cyner/transformers_ner.py in <module>
----> 1 from nltk.tokenize.punkt import PunktSentenceTokenizer as pt
2
3 from .entity_extraction import EntityExtraction
4 from .entity import Entity
5 from .tner import TrainTransformersNER
ModuleNotFoundError: No module named 'nltk'
I am currently trying to install CyNER in an Anaconda environment (Python 3.10). However when I tried to install the model directly through GitHub (as in the instruction), I got this problem with Matplotlib:
copying lib\matplotlib\mpl-data\stylelib\_classic_test_patch.mplstyle -> build\lib.win-amd64-cpython-310\matplotlib\mpl-data\stylelib
copying lib\matplotlib\mpl-data\fonts\ttf\STIXNonUniBol.ttf -> build\lib.win-amd64-cpython-310\matplotlib\mpl-data\fonts\ttf
UPDATING build\lib.win-amd64-cpython-310\matplotlib\_version.py
set build\lib.win-amd64-cpython-310\matplotlib\_version.py to '3.3.1'
running build_ext
Building freetype in build\freetype-2.6.1
msbuild build\freetype-2.6.1\builds\windows\vc2010\freetype.sln /t:Clean;Build /p:Configuration=Release;Platform=x64
error: command 'msbuild' failed: None
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
Rolling back uninstall of matplotlib
Moving to c:\users\hoang\anaconda3\lib\site-packages\__pycache__\pylab.cpython-310.pyc
from C:\Users\hoang\AppData\Local\Temp\pip-uninstall-k9zjxrv1\pylab.cpython-310.pyc
Moving to c:\users\hoang\anaconda3\lib\site-packages\matplotlib-3.7.0-py3.10-nspkg.pth
from C:\Users\hoang\AppData\Local\Temp\pip-uninstall-dx5xyrfv\matplotlib-3.7.0-py3.10-nspkg.pth
Moving to c:\users\hoang\anaconda3\lib\site-packages\matplotlib-3.7.0.dist-info\
from C:\Users\hoang\anaconda3\Lib\site-packages\~atplotlib-3.7.0.dist-info
Moving to c:\users\hoang\anaconda3\lib\site-packages\matplotlib\
from C:\Users\hoang\anaconda3\Lib\site-packages\~atplotlib
Moving to c:\users\hoang\anaconda3\lib\site-packages\mpl_toolkits\axes_grid1\
from C:\Users\hoang\anaconda3\Lib\site-packages\mpl_toolkits\~xes_grid1
Moving to c:\users\hoang\anaconda3\lib\site-packages\mpl_toolkits\axisartist\
from C:\Users\hoang\anaconda3\Lib\site-packages\mpl_toolkits\~xisartist
Moving to c:\users\hoang\anaconda3\lib\site-packages\mpl_toolkits\mplot3d\
from C:\Users\hoang\anaconda3\Lib\site-packages\mpl_toolkits\~plot3d
Moving to c:\users\hoang\anaconda3\lib\site-packages\pylab.py
from C:\Users\hoang\AppData\Local\Temp\pip-uninstall-dx5xyrfv\pylab.py
error: legacy-install-failure
× Encountered error while trying to install package.
╰─> matplotlib
note: This is an issue with the package mentioned above, not pip.
hint: See above for output from the failure.
I have tried to create a new environment (without any libraries from Python) to install the program again, but this issue still persists. So what would you recommend me to do in this case to get CyNER running?
Is there any python library for relationship extraction in cybersecurity domain
got this error:
2024-01-03 21:14:47 INFO *** initialize network ***
2024-01-03 21:14:47 INFO create new checkpoint
2024-01-03 21:14:47 INFO removed incomplete checkpoint .ckpt
2024-01-03 21:14:47 INFO checkpoint: .ckpt
2024-01-03 21:14:47 INFO - [arg] dataset: dataset/mitre
2024-01-03 21:14:47 INFO - [arg] transformers_model: xlm-roberta-base
2024-01-03 21:14:47 INFO - [arg] random_seed: 1
2024-01-03 21:14:47 INFO - [arg] lr: 5e-06
2024-01-03 21:14:47 INFO - [arg] epochs: 20
2024-01-03 21:14:47 INFO - [arg] warmup_step: 0
2024-01-03 21:14:47 INFO - [arg] weight_decay: 1e-07
2024-01-03 21:14:47 INFO - [arg] batch_size: 32
2024-01-03 21:14:47 INFO - [arg] max_seq_length: 128
2024-01-03 21:14:47 INFO - [arg] fp16: False
2024-01-03 21:14:47 INFO - [arg] max_grad_norm: 1
2024-01-03 21:14:47 INFO - [arg] lower_case: False
2024-01-03 21:14:47 INFO target dataset: ['dataset/mitre']
2024-01-03 21:14:47 INFO data_name: dataset/mitre
2024-01-03 21:14:47 INFO formatting custom dataset from dataset/mitre
2024-01-03 21:14:47 INFO found following files: {'test': 'test.txt', 'train': 'train.txt', 'valid': 'valid.txt'}
2024-01-03 21:14:47 INFO note that files should be named as either valid.txt, test.txt, or train.txt
Traceback (most recent call last):
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\c3.py", line 11, in
model.train()
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\transformers_ner.py", line 52, in train
trainer.train(monitor_validation=True)
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\model.py", line 292, in train
self.__setup_model_data(self.args.dataset, self.args.lower_case)
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\model.py", line 142, in __setup_model_data
self.dataset_split, self.label_to_id, self.language, self.unseen_entity_set = get_dataset_ner(
^^^^^^^^^^^^^^^^
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\get_dataset.py", line 153, in get_dataset_ner
data_split_all, label_to_id, language, ues = get_dataset_ner_single(d, **param)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\get_dataset.py", line 359, in get_dataset_ner_single
data_split_all, unseen_entity_set, label_to_id = decode_all_files(
^^^^^^^^^^^^^^^^^
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\get_dataset.py", line 459, in decode_all_files
label_to_id, unseen_entity_set, data_dict = decode_file(
^^^^^^^^^^^^
File "C:\Users\talia\OneDrive\Desktop\New folder (3)\CyNER-main\CyNER-main\cyner\tner\get_dataset.py", line 397, in decode_file
for n, line in enumerate(f):
File "C:\Users\talia\anaconda3\Lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 7701: character maps to
Hi, I have some trouble in model.get_entities.
The following picture is my code (same as demo), I'm not sure what's going on. :(

Sometimes will predict the different output with the same code (both of them are different from the demo's output).

When I config model1 = cyner.CyNER(transformer_model='xlm-roberta-large', use_heuristic=True, flair_model='ner', priority='HTFS'), the program went wrong, python gave the following feedback.
Traceback (most recent call last):
File "E:\PythonProject\CyNER\main.py", line 9, in
entities = model.get_entities(text)
File "C:\ProgramData\Anaconda3\lib\site-packages\cyner\cyner.py", line 60, in get_entities
entities = model.get_entities(text)
File "C:\ProgramData\Anaconda3\lib\site-packages\cyner\flair_ner.py", line 24, in get_entities
for x in pred['entities']:
KeyError: 'entities'
Anyone can help me, pls. /(ㄒoㄒ)/~~
https://markupsafe.palletsprojects.com/en/2.1.x/changes/
In 2.1.0, MarkupSafe: Remove soft_unicode, which was previously deprecated. Use soft_str instead. #261
Can cyNER be updated to remove this dependency?
When I want to change the transformers_model config in cfg, it would not achieve. Although I use the model in huggingface not for ner.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.