
Keras implementation of AdamW, SGDW, NadamW, and Warm Restarts, based on paper Decoupled Weight Decay Regularization - plus Learning Rate Multipliers
- Weight decay fix: decoupling L2 penalty from gradient. Why use?
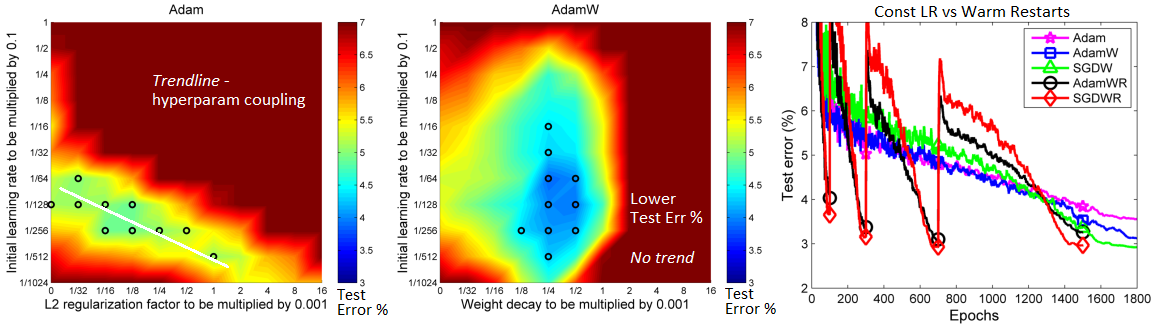
- Weight decay via L2 penalty yields worse generalization, due to decay not working properly
- Weight decay via L2 penalty leads to a hyperparameter coupling with
lr, complicating search
- Warm restarts (WR): cosine annealing learning rate schedule. Why use?
- Better generalization and faster convergence was shown by authors for various data and model sizes
- LR multipliers: per-layer learning rate multipliers. Why use?
- Pretraining; if adding new layers to pretrained layers, using a global
lris prone to overfitting
- Pretraining; if adding new layers to pretrained layers, using a global
AdamW(.., weight_decays=weight_decays)
Two methods to set weight_decays = {<weight matrix name>:<weight decay value>,}:
# 1. Use keras_adamw.utils.py
Dense(.., kernel_regularizer=l2(0)) # set weight decays in layers as usual, but to ZERO
wd_dict = get_weight_decays(model)
ordered_values = [1e-4, 1e-3, ..] # print(wd_dict) to see returned matrix names, note their order
weight_decays = fill_dict_in_order(wd_dict, ordered_values)# 2. Fill manually
model.layers[1].kernel.name # get name of kernel weight matrix of layer indexed 1
weight_decays.update({'conv1d_0/kernel:0':1e-4}) # exampleAdamW(.., use_cosine_annealing=True, total_iterations=200) - refer to Use guidelines below
AdamW(.., lr_multipliers=lr_multipliers) - to get, {<layer name>:<multiplier value>,}:
- (a) Name every layer to be modified (recommended), e.g.
Dense(.., name='dense_1')- OR
(b) Get every layer name, note which to modify:[print(idx,layer.name) for idx,layer in enumerate(model.layers)] - (a)
lr_multipliers = {'conv1d_0':0.1} # target layer by full name- OR
(b)lr_multipliers = {'conv1d':0.1} # target all layers w/ name substring 'conv1d'
from keras.layers import Input, Dense, LSTM
from keras.models import Model
from keras.regularizers import l2
from keras_adamw.optimizers import AdamW
from keras_adamw.utils import get_weight_decays, fill_dict_in_order
import numpy as np
ipt = Input(shape=(120,4))
x = LSTM(60, activation='relu', recurrent_regularizer=l2(0), name='lstm_1')(ipt)
out = Dense(1, activation='sigmoid', kernel_regularizer =l2(0), name='output')(x)
model = Model(ipt,out)wd_dict = get_weight_decays(model) # {'lstm_1/recurrent:0':0, 'output/kernel:0':0}
weight_decays = fill_dict_in_order(wd_dict,[4e-4,1e-4]) # {'lstm_1/recurrent:0':4e-4,'output/kernel:0':1e-4}
lr_multipliers = {'lstm_1':0.5}
optimizer = AdamW(lr=1e-4, weight_decays=weight_decays, lr_multipliers=lr_multipliers,
use_cosine_annealing=True, total_iterations=24)
model.compile(optimizer, loss='binary_crossentropy')for epoch in range(3):
for iteration in range(24):
x = np.random.rand(10,120,4) # dummy data
y = np.random.randint(0,2,(10,1)) # dummy labels
loss = model.train_on_batch(x,y)
print("Iter {} loss: {}".format(iteration+1, "%.3f"%loss))
print("EPOCH {} COMPLETED".format(epoch+1))
K.set_value(model.optimizer.t_cur, 0) # WARM RESTART: reset cosine annealing argument
(Full example + plot code: example.py)
- Set L2 penalty to ZERO if regularizing a weight via
weight_decays- else the purpose of the 'fix' is largely defeated, and weights will be over-decayed --My recommendation lambda = lambda_norm * sqrt(batch_size/total_iterations)--> can be changed; the intent is to scale λ to decouple it from other hyperparams - including (but not limited to), train duration & batch size. --Authors (Appendix, pg.1) (A-1)
- Set
t_cur = 0to restart schedule multiplier (see Example). Can be done at compilation or during training. Non-0is also valid, and will starteta_tat another point on the cosine curve. Details in A-2,3 - Set
total_iterationsto the # of expected weight updates for the given restart --Authors (A-1,2) eta_min=0, eta_max=1are tunable hyperparameters; e.g., an exponential schedule can be used foreta_max. If unsure, the defaults were shown to work well in the paper. --Authors- Save/load optimizer state; WR relies on using the optimizer's update history for effective transitions --Authors (A-2)
# 'total_iterations' general purpose example
def get_total_iterations(restart_idx, num_epochs, iterations_per_epoch):
return num_epochs[restart_idx] * iterations_per_epoch[restart_idx]
get_total_iterations(0, num_epochs=[1,3,5,8], iterations_per_epoch=[240,120,60,30])- Best used for pretrained layers - e.g. greedy layer-wise pretraining, or pretraining a feature extractor to a classifier network. Can be a better alternative to freezing layer weights. --My recommendation
- It's often best not to pretrain layers fully (till convergence, or even best obtainable validation score) - as it may inhibit their ability to adapt to newly-added layers. --My recommendation
- The more the layers are pretrained, the lower their fraction of new layers'
lrshould be. --My recommendation

