Hotels play a crucial role in travelling and with the increased access to information new pathways of selecting the best ones emerged. With this model, you can explore what makes a great hotel and maybe even use this model in your travels.
Table of contents
- Description and the aim of Project
- Packages used
- Text Analysis
- Pre-processing of text
- Vectorization and Modeling
- Deployment and testing
- Conclusion.
The aim of the model is to predict the Rating of hotel by Review. These Model is trained by dataset of hotel consisting of 20k reviews crawled from Tripadvisor. These Dataset has two features, first one is Review and another one is Rating. Review is the opinion of the customer in form of text and Rating is the opinion of customers in form of number from 1 to 5.These model gives Binary Rating when we pass Text Review in it.
- Pandas
- Numpy
- Seaborn
- Matplotlib
- TextBlob
- Natural Language Toolkit(NLTK)
- SnowballStemmer
- Regular Expression(re)
- WordCloud
- Scikitlearn(sklearn)
- pickle
Exploratory data analysis (EDA) to analyze and investigate dataset and summarize their main characteristics, often employing data visualization methods using Seaborn and Matplotlib Then, Sentiment analysis to gain the sentiment of customer by 'Polarity' and 'Subjectivity' using TextBlob
Polarity - It is the expression that determines the sentimental aspect of an opinion. In textual data, the result of sentiment analysis can be determined for each entity in the sentence, document or sentence. The sentiment polarity can be determined as positive, negative and neutral.
Subjectivity - Subjectivity generally refer to personal opinion, emotion or judgment whereas objective refers to factual information of the writer.
- Removing Stopwords - Stopwords are the English words which does not add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence. For example, the words like the, he, have etc. Such words are already captured this in corpus named corpus. Using Natural Language Toolkit(NLTK) package
- Stemming/lemmatization - Stemming and Lemmatization both generate the root form of the inflected words, Difference is that stem might not be an actual word whereas, lemma is an actual language word. But, when for that specific problem stemming works better than lemmatization using Natural Language Toolkit(NLTK) package
- Applied Regular Expression(re) to remove the punctuation and unwanted symbols if any using.
- Ploted WordCloud to check the frequent words used in all reviews.
Vectorization - Word vectorization is the process of encoding individual words into vectors so that the text can be easily analyzed or consumed by the machine learning algorithm. It’s difficult to analyse the raw corpus therefore a need to be convert it in to integers(best format is vectors) where we can apply mathematical operations and get insights from the data using Scikitlearn(sklearn).
Modeling - The process of modeling means training a machine learning algorithm to predict the labels from the features, tuning it for the business need, and validating it on holdout data. To choose best performing model.
Tested six combination of algorithm and vectorization techniques using Scikitlearn(sklearn) which are as follows:-
- TF-IDF with Logistic regression
- TF-IDF with Random Forest
- TFIDF with Naive Bayes
- Count Vectorizer Vectorization with Logistic regression
- Count Vectorizer with Random Forest
- Count Vectorizer with Naive Bayes.
At first, best model chosen out of the six combination of vectorizer and algorithm than perform the same for whole dataset without splitting the dataset. The best model and vectorizer method is stored by using pickle. For deployment testing a function was defined by using stored model from pickle, when a single sentence review passed to that function it returns sentiment of customer (you can also get that files which uploaded with these repository).
These model is deployed using Streamlit, screenshot is also attached to it.
Using anaconda prompt to run the streamlit
Have a look of streamlit application
When passed a Review which has Positive sentiment it returns Positive Review
.jpg?raw=true)
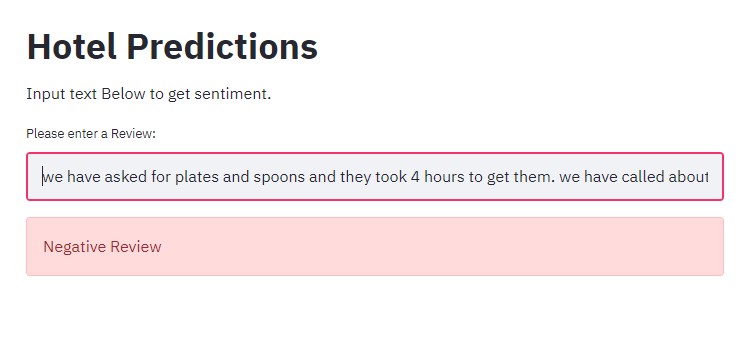
When passed a Review which has Negative sentiment it returns Negative Review
Performed modeling by split the dataset, Performed six different combination of vectorization and algorithm for train the model then found that the Logistic Regression with tfidf vectorization gives best accuracy among all. Then, applied those combination of Vectorizer and algorithm on whole dataset. These model gave 94.7% accuracy.

