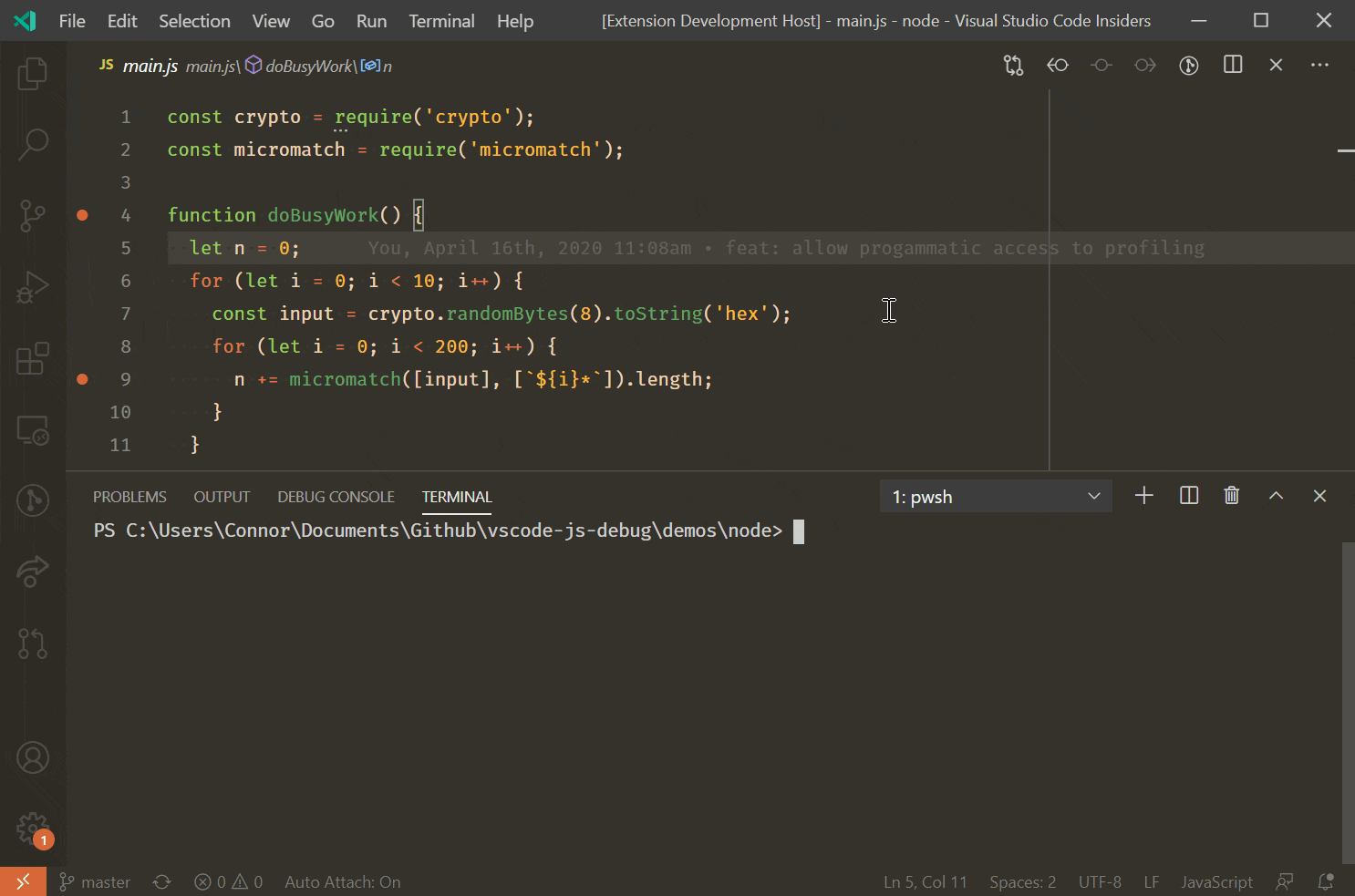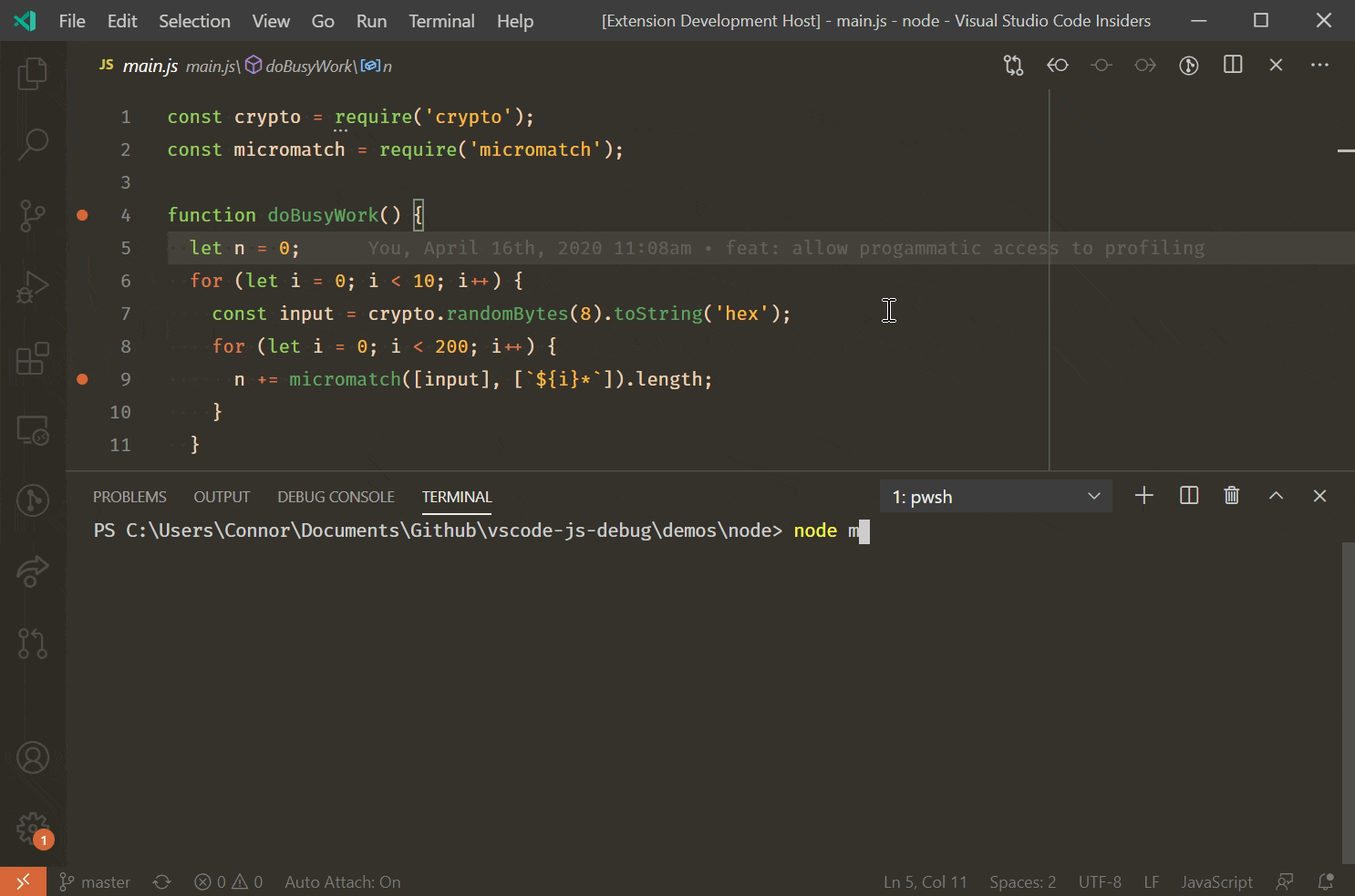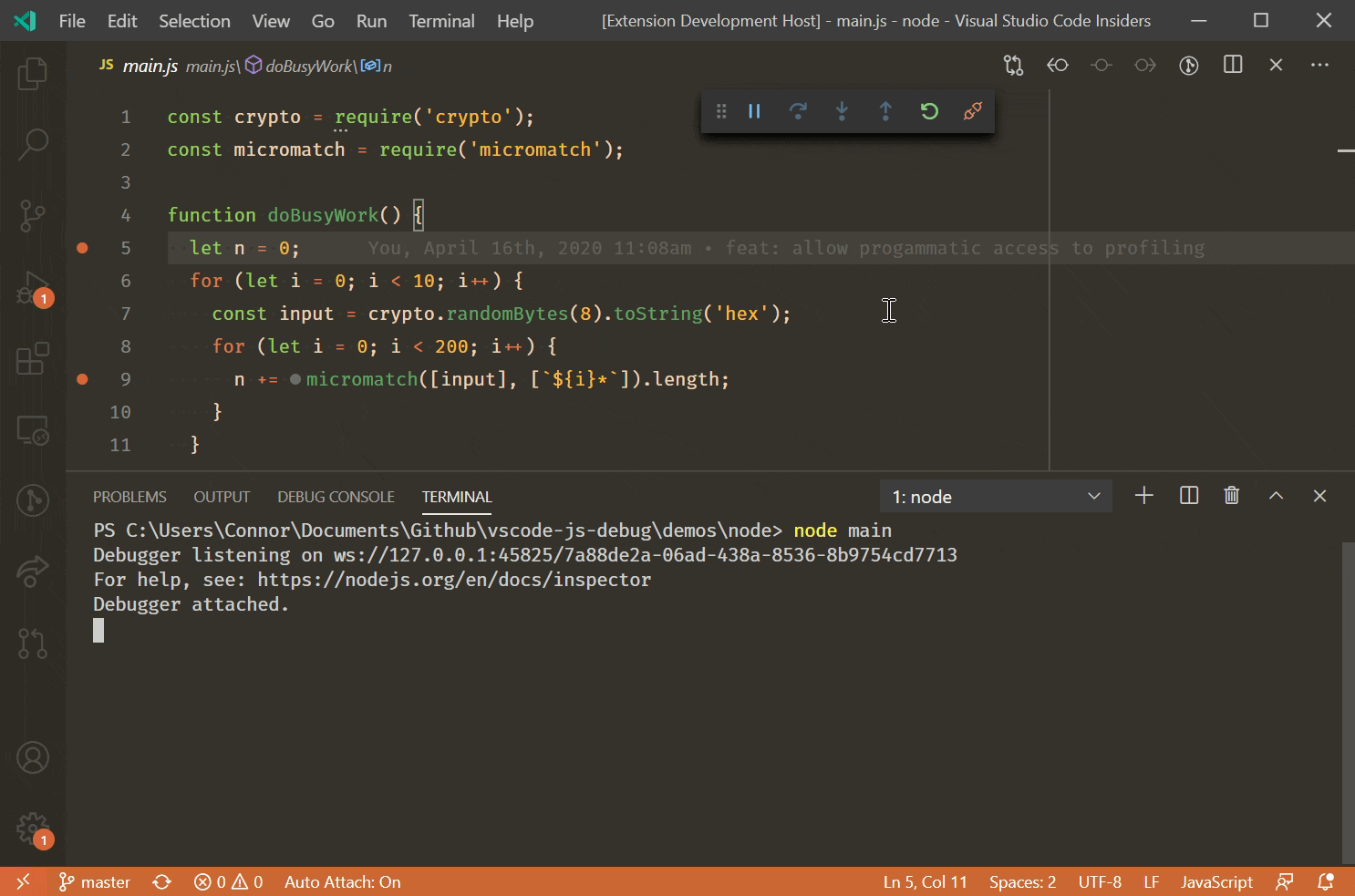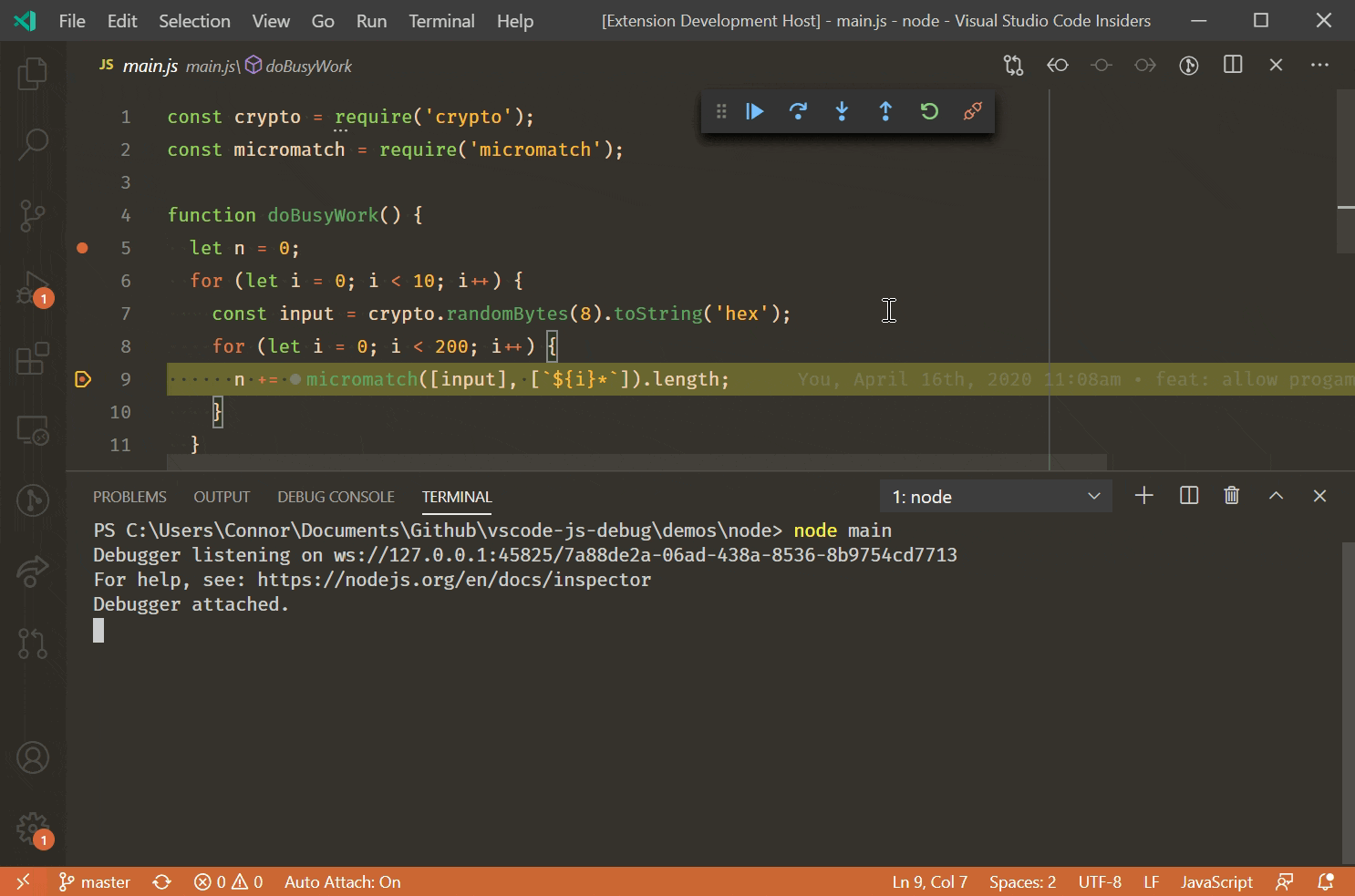
上个月 GitHub 一个新功能(Navigating code)开启 beta 测试, 目前只对部分用户开放. 作为一个非常依赖 GitHub 看源码/学(chao)技(dai)术(ma)的程序员, 虽然我日常一直使用 sourcegraph 插件作为源码辅助阅读工具, 看到 GitHub 官方终于开始着力提升代码阅读体验, 还是期待了很久.
简单来说它主要的作用是在 GitHub 仓库代码里点击相应符号显示一些信息(譬如函数签名, 变量类型)并且可以跳转到定义的位置, 也就是我们在 IDE 里常用到的 hover 和 gotoDefinition. 可以方便的在线阅读代码, 对于一些中大型的项目可以省去 clone 到本地用 IDE 阅读的成本. 最近在某些仓库代码区域顶部已经可以看到 You're using jump to definition to discover and navigate code. 字样, 表示 jump to definition 功能可以在这个仓库使用. 初步体验了一下除了第一次索引较慢, 之后跳转和显示信息速度都还能接受.
在 GitHub 官方博客中可以看到这个功能是基于前段时间开源的 semantic 实现的, 关于这个项目纸糊上也有相关的讨论, 有兴趣可以移步围观, 这里我就不献丑了.
关于在线代码阅读辅助工具, 我个人比较常用的就是 sourcegraph , 包含了独立的网站, 命令行工具和 Chrome 插件, 这个项目使用支持 LSP 的语言服务在后台对项目代码进行分析, 关于一些技术细节可以看一下他们的官方博客, 其中一些文章详细介绍了他们基于 LSP 的整体架构和对 LSP 的一些扩展. sourcegraph 也支持类似 VS Code API 的插件系统, 开发者可以通过插件的形式增强 sourcegraph 对语言的支持, 目前 sourcegraph 已经支持数十种主流编程语言, 并且完全免费开源.
今年 2 月份, VS Code 官方博客更新了一篇名为**The Language Server Index Format (LSIF)**的文章, 介绍了主要用于增强代码阅读体验的语言服务索引格式(LSIF)规范, 定义了一种基于图的索引数据结构, 将 IDE 中 hover , 跳转, 引用等 feature 的结果预先缓存下来, 可以为 GitHub 这种代码托管平台提供丰富的阅读体验, 只要平台提供相应的 Client 请求并显示这些内容. 目前 LSIF 规范还在草案阶段, 但已经有了 TypeScript , Java 等语言的实现. sourcegraph 也已经着手准备开发下一代代码阅读辅助工具. 但到目前为止, 还没有看到基于 LSIF 的代码阅读工具, 官方只有一个 VS Code 插件作为演示 demo, 但我的需求并不是在 VS Code 里看代码, 而是 GitHub. 所以我开发了基于 LSIF 的 Chrome 插件(目前只支持 TypeScript), 一方面作为一个尝试, 另一方面可以弥补在网络状况不佳(你懂)的情况下 sourcegraph 速度太慢的不足.
先来看一下插件的功能
鼠标划过显示类型或注释信息
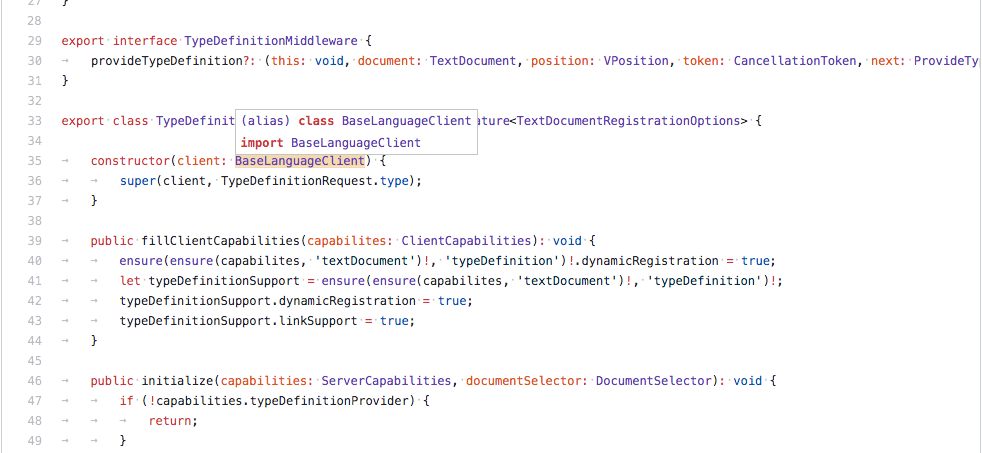
和 VS Code outline 同款的代码导航
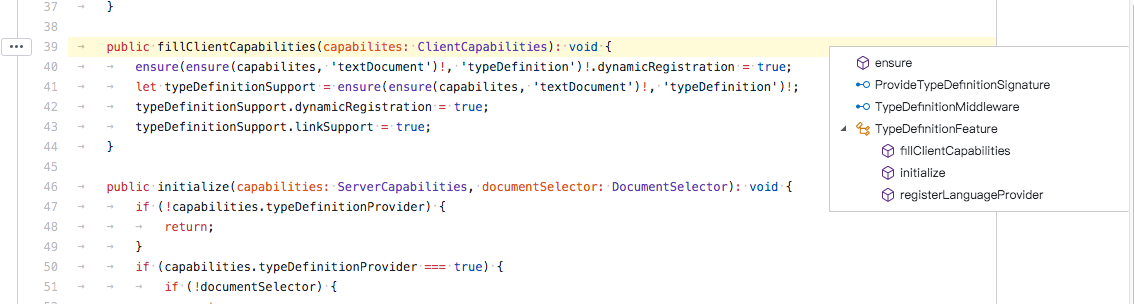
是的, 目前只有这两个功能. 这个插件大概花了不到一星期的时间开发, 还有很多坑, 目前也只是能实现基本的功能.
实现原理
首先插件需要通过类似 LSP 的方式和一个 LSIF 后端通信, 这里借鉴了 LSP 的一部分方法, 初次打开 GitHub 项目会发送一个 initialize 请求告诉 LSIF 后端开始初始化, LSIF 后端会 clone 项目代码并使用 lsif-tsc 工具分析一遍项目代码, 然后将结果缓存在一个特定文件中, 索引结果大概长这样
{"id":1,"type":"vertex","label":"metaData","version":"0.4.2","projectRoot":"file:///path/to/project"}
{"id":2,"type":"vertex","label":"project","kind":"typescript"}
{"id":3,"type":"vertex","label":"$event","kind":"begin","scope":"project","data":2}
{"id":4,"type":"vertex","label":"document","uri":"file:///path/to/project/file.ts","languageId":"typescript","contents":"xxxx"}
{"id":5,"type":"vertex","label":"$event","kind":"begin","scope":"document","data":4}
{"id":6,"type":"vertex","label":"resultSet"}
{"id":7,"type":"vertex","label":"moniker","kind":"export","scheme":"tsc","identifier":"out/common/file:"}
{"id":8,"type":"edge","label":"moniker","outV":6,"inV":7}
{"id":9,"type":"vertex","label":"range","start":{"line":0,"character":0},"end":{"line":0,"character":0},"tag":{"type":"definition","text":"","kind":7,"fullRange":{"start":{"line":0,"character":0},"end":{"line":39,"character":1}}}}
{"id":10,"type":"edge","label":"next","outV":9,"inV":6}
{"id":11,"type":"vertex","label":"document","uri":"file:///path/to/project/file.ts","languageId":"typescript","contents":"yyyyy"}
{"id":12,"type":"vertex","label":"$event","kind":"begin","scope":"document","data":11}
{"id":13,"type":"vertex","label":"resultSet"}
{"id":14,"type":"vertex","label":"moniker","kind":"export","scheme":"tsc","identifier":"out/common/diffHunk:"}
{"id":15,"type":"edge","label":"moniker","outV":13,"inV":14}
{"id":16,"type":"vertex","label":"range","start":{"line":0,"character":0},"end":{"line":0,"character":0},"tag":{"type":"definition","text":"","kind":7,"fullRange":{"start":{"line":0,"character":0},"end":{"line":291,"character":0}}}}
{"id":17,"type":"edge","label":"next","outV":16,"inV":13}
{"id":18,"type":"vertex","label":"resultSet"}
{"id":19,"type":"vertex","label":"moniker","kind":"export","scheme":"tsc","identifier":"out/common/diffHunk:DiffHunk"}
{"id":20,"type":"edge","label":"moniker","outV":18,"inV":19}
{"id":21,"type":"vertex","label":"range","start":{"line":49,"character":13},"end":{"line":49,"character":21},"tag":{"type":"definition","text":"DiffHunk","kind":5,"fullRange":{"start":{"line":49,"character":0},"end":{"line":59,"character":1}}}}
{"id":22,"type":"edge","label":"next","outV":21,"inV":18}
{"id":23,"type":"vertex","label":"hoverResult","result":{"contents":[{"language":"typescript","value":"class DiffHunk"}]}}
{"id":24,"type":"edge","label":"textDocument/hover","outV":18,"inV":23}
{"id":25,"type":"vertex","label":"resultSet"}
{"id":26,"type":"edge","label":"next","outV":25,"inV":18}
{"id":27,"type":"vertex","label":"moniker","scheme":"$local","identifier":"vYHm3Ot2dv3ly39PHoEc0w=="}
{"id":28,"type":"edge","label":"moniker","outV":25,"inV":27}
{"id":29,"type":"vertex","label":"range","start":{"line":5,"character":9},"end":{"line":5,"character":17},"tag":{"type":"definition","text":"DiffHunk","kind":7,"fullRange":{"start":{"line":5,"character":9},"end":{"line":5,"character":17}}}}
{"id":30,"type":"edge","label":"next","outV":29,"inV":25}
{"id":31,"type":"vertex","label":"hoverResult","result":{"contents":[{"language":"typescript","value":"(alias) class DiffHunk\nimport DiffHunk"}]}}
{"id":32,"type":"edge","label":"textDocument/hover","outV":25,"inV":31}
{"id":33,"type":"vertex","label":"range","start":{"line":5,"character":25},"end":{"line":5,"character":37},"tag":{"type":"reference","text":"'./diffHunk'"}}
{"id":34,"type":"edge","label":"next","outV":33,"inV":13}
{"id":35,"type":"vertex","label":"resultSet"}
{"id":36,"type":"vertex","label":"moniker","kind":"export","scheme":"tsc","identifier":"out/common/file:GitChangeType"}这个过程一般不会很久(除非是超大项目), 例如 vscode-languageserver-node 这个项目大概需要 20s 以内的时间, 最终会生成 24m 的索引文件, 然后将这个文件逐行读取并构造出一个图(来不及解释了, 这段代码是我抄的), 可以以很快的速度查询 hover/references 等数据. 之后会返回 initialized 表示初始化完毕, 这时候就可以发起像 LSP 一样的请求了.
我的第一个需求是显示一个类似 VS Code 大纲视图的列表, 方便我在读超长的代码时快速跳转到文件内相应的位置, 只需要发送 documentSymbol 请求, 在后端会去之前构造的图里找到对应文件的 documentSymbol 结果并返回给客户端(这里的客户端就是我们的 Chrome 插件). documentSymbol 的结构长这样
{
"result": [
{
"name": "uriToFilePath",
"detail": "",
"kind": 12,
"range": {
"start": { "line": 15, "character": 0 },
"end": { "line": 35, "character": 1 }
},
"selectionRange": {
"start": { "line": 15, "character": 16 },
"end": { "line": 15, "character": 29 }
}
},
{
"name": "isWindows",
"detail": "",
"kind": 12,
"range": {
"start": { "line": 37, "character": 0 },
"end": { "line": 39, "character": 1 }
},
"selectionRange": {
"start": { "line": 37, "character": 9 },
"end": { "line": 37, "character": 18 }
}
},
],
"id": 2,
"method": "documentSymbol"
}可以看到相应是一个数组, 包含了文件中所有 definition 的名称, kind(表示他是啥)以及位置信息(zero base).
拿到这些就可以在 GitHub 代码页面展示出来了, 大概就是每个 item 放一个 a 标签, 指向对应的行
https://github.com/microsoft/vscode-languageserver-node/blob/[commit]/server/src/files.ts#L162 , 点击这个 a 标签会跳转到相应的行并高亮显示(GitHub 自带).
另一个功能是 hover 效果, 这也是 LSP 本身就支持的方法, 需要先找到触发事件的 token 所处的位置, 可以通过遍历页面 DOM 节点计算得出, 具体不再赘述. 然后发起 hover 请求, 并带上表示 token 位置和路径的参数, 在 LSIF 服务端同样去图里找到预先缓存的 hoverResult 返回即可. 界面上可以用 marked + highlight.js 这套组合将返回的信息以 markdown 的形式渲染出来, 因为标准的 jsdoc 等注释内容在 LSP/LSIF 的实现里可以被解析为 markdown 格式的字符串. 剩下的事情对我这个切图仔来说就很简单了😀.
以上就是整个插件的实现过程, 因为大部分是抄了 LSP 的实现, 所以一些代码是从其他开源项目中直接 copy 过来的, 当然也有一些坑点需要解决.
- 索引需要和 Git 版本对应, 查看 master 分支的代码不能返回 dev 分支的索引信息, 这里我目前的做法是 initialize 时携带 commit 号或分支名, 索引文件以 <commit/branch>.lsif 命名.
- 索引前需要 clone 代码到服务端, 后续推送了代码需要及时 fetch 下来, 这部分还没想好怎么优雅的处理.
- 索引和代码文件会比较大, 暂时没有找到合适的数据库方案存储, 目前只是存放在特定目录😂.
- lsif-node 本身支持 npm 依赖分析, 如果要做的话还需要 npm install 一次, 有点不能接受.
- lsif-tsc 基于 TypeScript 编译器进行代码分析, 部分 tsconfig 不全的项目分析会有异常抛出(可能要等官方后续更新)
插件和 LSIF 服务端代码都在我的 GitHub, 有兴趣的可以 pr/issue 甩过来.
lsif-typescript-chrome-extension
lsif-typescript-server
后续会继续维护这两个项目, 尽量实现 TypeScript 代码阅读的体验能超过 sourcegraph.
参考链接
- Navigating code on GitHub
- 如何评价 GitHub 开源的程序分析库 semantic ?
- Part 1: How Sourcegraph scales with the Language Server Protocol
- Part 2: How Sourcegraph scales with the Language Server Protocol
- The Language Server Index Format (LSIF)
- lsif-node