.
├── MyCrawler // ---scrapy爬虫项目---
│ ├── MyCrawler
│ │ ├── __init__.py
│ │ ├── data //爬取数据存放路径
│ │ │ └── agri_economic.json
│ │ ├── items.py //items对应图谱中的结点
│ │ ├── middlewares.py
│ │ ├── pipelines.py //过滤管道
│ │ ├── settings.py
│ │ └── spiders //爬虫脚本存放路径
│ │ ├── __init__.py
│ │ └── agri_pedia.py
│ ├── mySpider.log
│ └── scrapy.cfg
└── demo // ---django知识图谱项目---
├── demo // 存放view,用于后台和前端交互
│ ├── __init__.py
│ ├── detail_view.py
│ ├── index_ERform_view.py
│ ├── index_view.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
├── neo4jModel // 自己写的neo4j Model层
│ ├── __init__.py
│ └── models.py
├── static // 用于保存静态模板
│ ├── css
│ │ └── bootstrap.min.css
│ └── js
│ ├── bootstrap.min.js
│ └── jquery.min.js
└── templates // html前端页面
├── base.html
├── detail.html
└── index.html
系统需要安装:
- scrapy ---爬虫框架
- django ---web框架
- neo4j ---图数据库
- thulac ---分词、词性标注
- py2neo ---python连接neo4j的工具
1.根据19000条农业网词条,按照筛法提取名词(分批进行,每2000条1批,每批维护一个不可重集合)
2.将9批词做交集,生成农业词典
3.将词典中的词在互动百科中进行爬取,抛弃不存在的页面,提取页面内容,存到数据库中
4.根据页面内容,构造每个词的特征,进行聚类/分类
5.最后提取出农业词语,剔除非农业词语
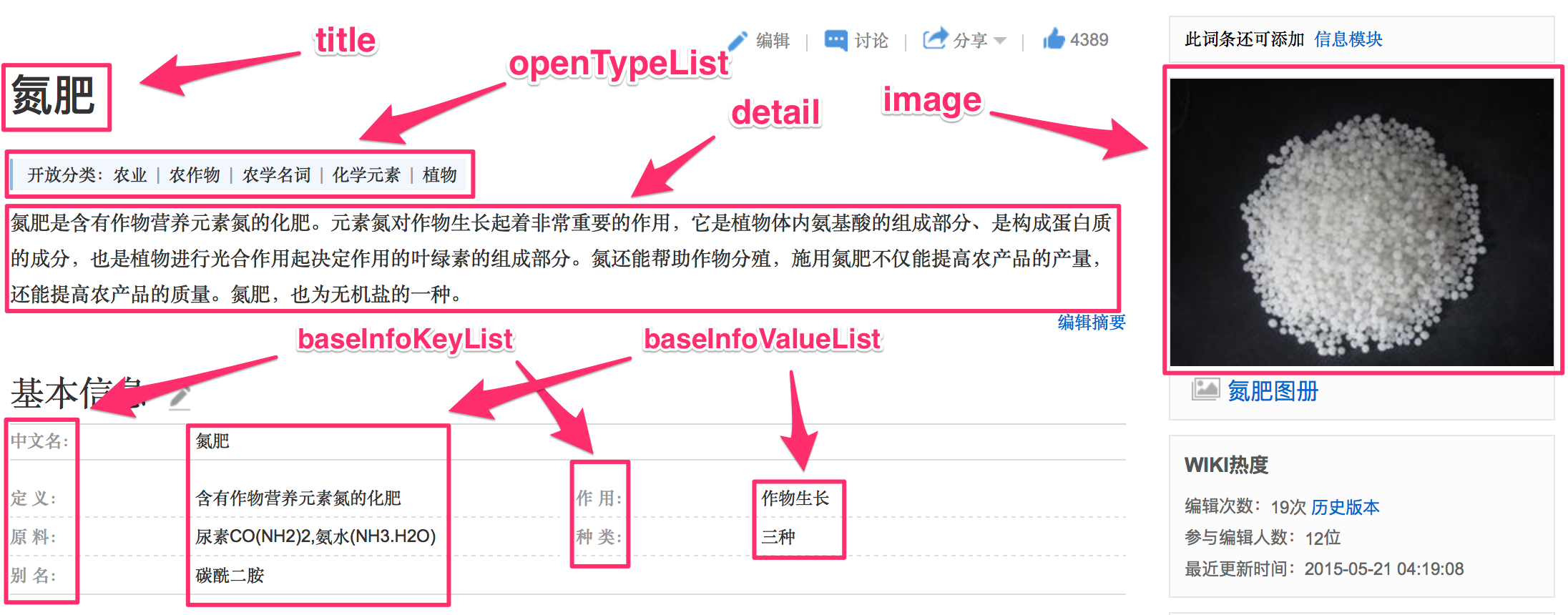
- 无需表示成向量,比较相似度即可
- title之间的word2vec值
- 2组openType之间的word2vec的平均值
- Detail中2组关键词之间的word2vec的平均值(每个文本只取前m个TF-IDF值最高的词作为关键词)
- 相同baseInfoKey的个数
- 相同baseInfoKey下baseInfoValue相同的个数
| Label | NE Tags | Example |
|---|---|---|
| 0 | Invalid(不合法) | “色调”,“文化”,“景观”,“条件”,“A”,“234年”(不是具体的实体,或一些脏数据) |
| 1 | Person(人物,职位) | “袁隆平”,“***”,“皇帝” |
| 2 | Location(地点,区域) | “福建省”,“三明市”,“大明湖” |
| 3 | Organization(机构,会议) | “华东师范大学”,“上海市农业委员会” |
| 4 | Political economy(政治经济名词) | “惠农补贴”,“基本建设投资” |
| 5 | Animal(动物学名词,包括畜牧类,爬行类,鸟类,鱼类,等) | “绵羊”,“淡水鱼”,“麻雀” |
| 6 | Plant(植物学名词,包括水果,蔬菜,谷物,草药,菌类,植物器官,其他植物) | “苹果”,“小麦”,“生菜” |
| 7 | Chemicals(化学名词,包括肥料,农药,杀菌剂,其它化学品,术语等) | “氮”,“氮肥”,“硝酸盐”,“吸湿剂” |
| 8 | Climate(气候,季节) | “夏天”,“干旱” |
| 9 | Food items(动植物产品) | “奶酪”,“牛奶”,“羊毛”,“面粉” |
| 10 | Diseases(动植物疾病) | “褐腐病”,“晚疫病” |
| 11 | Natural Disaster(自然灾害) | “地震”,“洪水”,“饥荒” |
| 12 | Nutrients(营养素,包括脂肪,矿物质,维生素,碳水化合物等) | “维生素A”,"钙" |
| 13 | Biochemistry(生物学名词,包括基因相关,人体部位,组织器官,细胞,细菌,术语) | “染色体”,“血红蛋白”,“肾脏”,“大肠杆菌” |
| 14 | Agricultural implements(农机具,一般指机械或物理设施) | “收割机”,“渔网” |
| 15 | Technology(农业相关术语,技术和措施) | “延后栽培",“卫生防疫”,“扦插” |
| 16 | other(除上面类别之外的其它名词实体,可以与农业无关但必须是实体) | “加速度",“cpu”,“计算机”,“爱鸟周”,“人民币”,“《本草纲目》”,“花岗岩” |