Regression Loss Functions
Source: https://heartbeat.fritz.ai/5-regression-loss-functions-all-machine-learners-should-know-4fb140e9d4b0
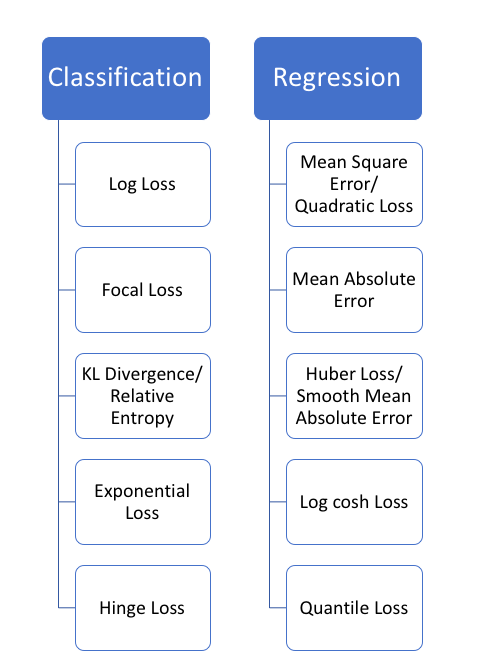
- Mean Square Error, Quadratic loss, L2 Loss
- Mean Absolute Error, L1 Loss
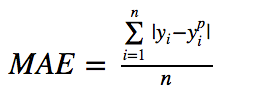
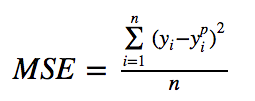
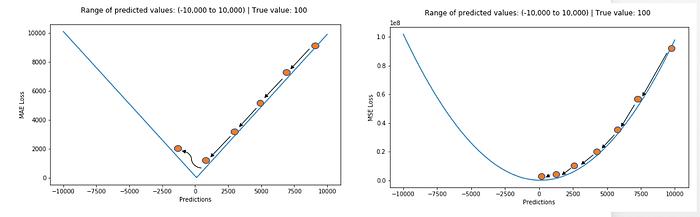
MAE loss is useful if the training data is corrupted with outliers (i.e. we erroneously receive unrealistically huge negative/positive values in our training environment, but not our testing environment). L1 loss is more robust to outliers, but its derivatives are not continuous, making it inefficient to find the solution. L2 loss is sensitive to outliers, but gives a more stable and closed form solution (by setting its derivative to 0.)
3. Huber Loss, Smooth Mean Absolute Error
One big problem with using MAE for training of neural nets is its constantly large gradient, which can lead to missing minima at the end of training using gradient descent. For MSE, gradient decreases as the loss gets close to its minima, making it more precise.
Huber loss can be really helpful in such cases, as it curves around the minima which decreases the gradient. And it’s more robust to outliers than MSE. Therefore, it combines good properties from both MSE and MAE. However, the problem with Huber loss is that we might need to train hyperparameter delta which is an iterative process.

4. Log-Cosh Loss
log(cosh(x)) is approximately equal to (x ** 2) / 2 for small x and to abs(x) - log(2) for large x. This means that 'logcosh' works mostly like the mean squared error, but will not be so strongly affected by the occasional wildly incorrect prediction. It has all the advantages of Huber loss, and it’s twice differentiable everywhere, unlike Huber loss.
second derivative is available



5.Quantile Loss
Prediction interval from least square regression is based on an assumption that residuals (y — y_hat) have constant variance across values of independent variables. We can not trust linear regression models that violate this assumption.
γ is the required quantile and has value between 0 and 1.

