Comments (17)
 RobSmithDev
commented on May 28, 2024
RobSmithDev
commented on May 28, 2024
Hi
Yes it does all sound plausible and should be relatively easy to modify. I may have been mixing up rpm and bps, much of this was derived from http://lclevy.free.fr/adflib/adf_info.html
Anyway the magic numbers in the read function are based on http://amiga.robsmithdev.co.uk/history#attempt12
From the graph I worked out center points and messed with the numbers to easily separate the different time intervals between bits.
Hope this helps
Regards
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 19 Mar 2018, at 21:47, Ewen McNeill ***@***.***> wrote:
Further to #1 and #3, I'm wondering if it would be possible to adapt this project to read 5.25" double density ("360KB"-ish) floppies, originally written via NEC 765 (original IBM PC-style) floppy controller, in a track-at-once mode?
As far as I can tell, the Amiga floppies the code currently reads are 3.5" double density floppies, written with a custom floppy controller (ie, part of the Amiga chipset, rather than a third party "floppy controller" chip like the NEC 765). These seem to be MFM encoded ("double density"), 8x track, double sided, 3.5" floppies, spun at 300rpm. And it appears that the Amiga always wrote them in "track at once" mode, which allowed omitting inter-sector gaps and thus fitting 11 * 512 byte sectors onto the track (versus the 9, or perhaps 10, possible with a NEC 765 style controller that tried to update individual sectors in place). Giving a total capacity of 880KiB (80 * 11 * 2 * 512 bytes) or so.
5.25" double density is also MFM encoded, onto floppies spun at 300rpm, and either single or double sided, with usually 4x tracks per side. These figures seem relatively close to what the code already supports (and track stepping is already independent of reading the track). As best I can remember/find out, 5.25" double density drives using MFM encoding had a data rate of 250Kbps, as discussed in #1, which means the bit rate might need changing.
This HxC thread seems to suggest the Amiga bit rate was close to 250Kbps but slightly different (the same thread suggests PC double density fits 12500 +/- 0.5% bits per track, just slightly less than the Amiga).
But I see in #1 you suggest the Amiga bit rate was 300Kbps? Do you happen to remember where you got the 300Kbps figure from? (It's fine if it was just off the top of your head; just trying to figure out how much the timing constants might need tweaking.)
There seem to be some magic values in the read code, which I'm guessing are related to the data rate coming in. Do you have any notes on how those values were calculated? And/or any other raw media bit rates values in the code to look out for (timer programming values)?
My thought here is that maybe it would be possible to read (I have no interest in writing) non-Amiga disks simply by stepping to the right track, doing a raw track media read with "read track" and then decoding both the MFM encoding and the sector data from the track bits on the PC side later. Does that sound plausible? From memory the NEC 765 style controllers write sector preambles and other framing that one can search for to locate the sectors out of the track bits, so I'm assuming given a MFM-transition timing accurate media bit rate read of the track data it should in theory be "just a matter of programming" to decode the sectors out of the MFM data, and put it into some suitable (existing) container format.
Does this sound plausible to you?
Thanks in advance,
Ewen
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
 ewenmcneill
commented on May 28, 2024
ewenmcneill
commented on May 28, 2024
Hi Rob,
Thanks, that's a very useful pointer to where the timing numbers came from -- statistical analysis of inter-transition timings on reading actual floppies. Since it seems like the Amiga and PC-style double density MFM bps rate is fairly similar, it seems likely that the same bucketing technique you use should work, maybe just with minor tweaks of timing bin boundaries.
The "300" rpm and bps confusion definitely sounds like a plausible place the 300Kbps figure in #1 might have come from. Thanks for clarifying.
Of note, the reference you gave gives the bit rate information of "Controller clock rate : 2 microseconds per bit cell", which would imply 500Kbps (1/0.000002), but AFAICT that would be a 3.5" high density bit rate and the 880KiB format implies double density (and thus a lower bit rate, around 250Kbps as I found before). Possibly that 2 microseconds value refers to something lower level than the typically quoted bit rate, ie something to do with the way it is being output. Or maybe it does refer to high density floppy discs. (But AFAICT most Amigas only supported 880KiB double density floppy discs, including the Amiga 500 that you seem to have been targetting.)
Also from that same reference it looks like the Amiga tracks are 0x1900 "words" long, which seems to be 16-bit words, for 0x1900 * 2 = 12800 bytes (102400 bits). Those seem to be relatively similar to the lengths I've seen for PC double density formats, again suggesting 250Kbps-like speed for a notional 300rpm rather than something dramatically different. (It also looks like the Amiga on-disk sector format took 1088/0x440 bytes per sector, including headers, checksums, etc; 12800/1088 = 11.7ish, suggesting 11 sectors packed with fairly minimal extra overheads.)
Ewen
PS: As an aside, in terms of timing, there's definitely a relationship between rpm (rate at which the floppy is spinning) and the practical (rather than theoretical) bps rate, even assuming the disks were written at the same/similar theoretical bps rate (eg, 250Kbps or similar). If the drive reading the media is spinning faster than the drive that wrote it, then the bits will seems to arrive faster; if the drive reading the media is spinning slower than the drive that wrote it, then the bits will seem to arrive slower. MFM, being self-clocking, was used to help recover the from-media actual clock rate to self-synchronise to deal with this. But even then the rpm needed to be fairly close for reliable reading otherwise the PLL wouldn't lock on. In practice if one can assume a fairly close rpm rate on the reading drive and the writing drive the "binning" approach you use seems likely to compensate for minor variations in rotational speed without the complexity of trying to do PLL syncing in software. And perhaps also compensate for the minor differences in Amiga bps rate and PC floppy controller bit rates. I'm very impressed with how simple the Arduino code seems to be, well done.
from arduinofloppydiskreader.
RobSmithDev
commented on May 28, 2024
Hi, 500kbps is while the data is MFM, once decoded it’s 250kbps, but that’s done on the PC side as I didn’t want to risk missing a bit by doing in on the Arduino.
Hope this clears that up.
Regards
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 20 Mar 2018, at 00:54, Ewen McNeill ***@***.***> wrote:
Hi Rob,
Thanks, that's a very useful pointer to where the timing numbers came from -- statistical analysis of inter-transition timings on reading actual floppies. Since it seems like the Amiga and PC-style double density MFM bps rate is fairly similar, it seems likely that the same bucketing technique you use should work, maybe just with minor tweaks of timing bin boundaries.
The "300" rpm and bps confusion definitely sounds like a plausible place the 300Kbps figure in #1 might have come from. Thanks for clarifying.
Of note, the reference you gave gives the bit rate information of "Controller clock rate : 2 microseconds per bit cell", which would imply 500Kbps (1/0.000002), but AFAICT that would be a 3.5" high density bit rate and the 880KiB format implies double density (and thus a lower bit rate, around 250Kbps as I found before). Possibly that 2 microseconds value refers to something lower level than the typically quoted bit rate, ie something to do with the way it is being output. Or maybe it does refer to high density floppy discs. (But AFAICT most Amigas only supported 880KiB double density floppy discs, including the Amiga 500 that you seem to have been targetting.)
Also from that same reference it looks like the Amiga tracks are 0x1900 "words" long, which seems to be 16-bit words, for 0x1900 * 2 = 12800 bytes (102400 bits). Those seem to be relatively similar to the lengths I've seen for PC double density formats, again suggesting 250Kbps-like speed for a notional 300rpm rather than something dramatically different. (It also looks like the Amiga on-disk sector format took 1088/0x440 bytes per sector, including headers, checksums, etc; 12800/1088 = 11.7ish, suggesting 11 sectors packed with fairly minimal extra overheads.)
Ewen
PS: As an aside, in terms of timing, there's definitely a relationship between rpm (rate at which the floppy is spinning) and the practical (rather than theoretical) bps rate, even assuming the disks were written at the same/similar theoretical bps rate (eg, 250Kbps or similar). If the drive reading the media is spinning faster than the drive that wrote it, then the bits will seems to arrive faster; if the drive reading the media is spinning slower than the drive that wrote it, then the bits will seem to arrive slower. MFM, being self-clocking, was used to help recover the from-media actual clock rate to self-synchronise to deal with this. But even then the rpm needed to be fairly close for reliable reading otherwise the PLL wouldn't lock on. In practice if one can assume a fairly close rpm rate on the reading drive and the writing drive the "binning" approach you use seems likely to compensate for minor variations in rotational speed without the complexity of trying to do PLL syncing in software. And perhaps also compensate for the minor differences in Amiga bps rate and PC floppy controller bit rates. I'm very impressed with how simple the Arduino code seems to be, well done.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
Hi Rob,
Thanks, that's a very useful clarification to my understanding of how the off-media signal looks, and what data rates to expect at which points. It also makes me fairly confident that the timings from Amiga 880KiB 3.5" discs should be fairly transferable to 5.25" PC-style "360KiB" double density disks (ie, 500Kbps off media MFM encoded; 250Kbps recovered rate).
Based on 300rpm == 5 rotations/second = 200ms per rotation, 250Kbps, gives 50K decodeable bits (250Kbps * 0.2s) per rotation, gives 6250 decodeable bytes (50K/8), gives room for 11 * 512 byte sectors + 618 bytes for overhead (or 10 * 512 byte sectors + 1130 bytes for overhead, including gaps; or 9 * 512 byte sectors + 1642 bytes for overhead, including gaps). And that also implies that with 500Kbps raw MFM data off the media, about 100 Kbits needs to be transferred to the PC per track to represent it, which is useful sizing information. (I think that also makes sense of the 0x1900 magic value; 0x1900 = 6240 == 6250 - tiny gap left; which would make it times 2 -- or 16-bit words rather than bytes -- in order to read the MFM data off the media pre-decoding. It looks like the 0x440 sector length value defined in the reference you give is also "as encoded in MFM", ie at the 500Kbps rate.)
BTW, doing the MFM decoding on the PC side was one of the bits of your design I liked the most: it takes it out of being a real-time struggle, and turns it into a post processing step somewhere with lots of processing power. Noticing that "standard" "async" serial chips can be pushed faster than floppy drives these days (eg, 2Mbps versus 250Kbps/500Kbps) with almost no effort is a very insightful realisation. (The only other system I'm aware using that split processing approach is the KyroFlux range (eg stream protocol documentation), and they use a "small" ARM processor; managing something similar with a smaller AT Mega is impressive, and your wire protocol is also impressively minimalistic. KyroFlux's approach is clearly better for exact representation archival purposes, since it records more of the timing details for posterity, but doing something similar on inexpensive off the shelf hardware is very cool.)
I'll close the ticket for now, as I think I have all the information I need to give it a try with the 5.25" double density floppies I have. But I'll come back and let you know how I get on once I've had a chance to find enough time to try it out (potentially in several weeks).
Ewen
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
For the benefit of anyone finding this later, this PDF describing floppy drive technology has a bunch of useful detail on the NEC 765's on-media format. One of the things that stands out on skimming through it is that it seems to use "missing clock transition" magic codes in a few places as special markers, which seems like it could throw off this "timing bucket" based approach if there isn't a way to compensate for it (eg, by knowing it only happens within certain bit patterns, and adjusting how they got read). I also found another summary which confirms these missing clock transition markers (apparently to allow spotting framing as distinct from "user data"). This IBM 34 format post seems to suggest there are variations on the "missing clock transition as a marker" approach.
I also found another really useful summary of the NEC 765/IBM 34/etc on-disk format while looking for a NEC 765 manual (I think I've seen one online this year; and IIRC I have an old photocopy somewhere...). Amongst other things it confirms "6250 bytes per track is the (rough) upper limit for fixed speed MFM 5.25" drives" which matches my calculations above.
(The IBM 3740 described in that document seems to be 8" single density, FM encoded; I believe the IBM 34 format mentioned is the first 8" double density/MFM drive -- this Atari floppy format post points at a diagram of the IBM 34 format, and the WD FD1791 manual gives another example of the "IBM 34" format.)
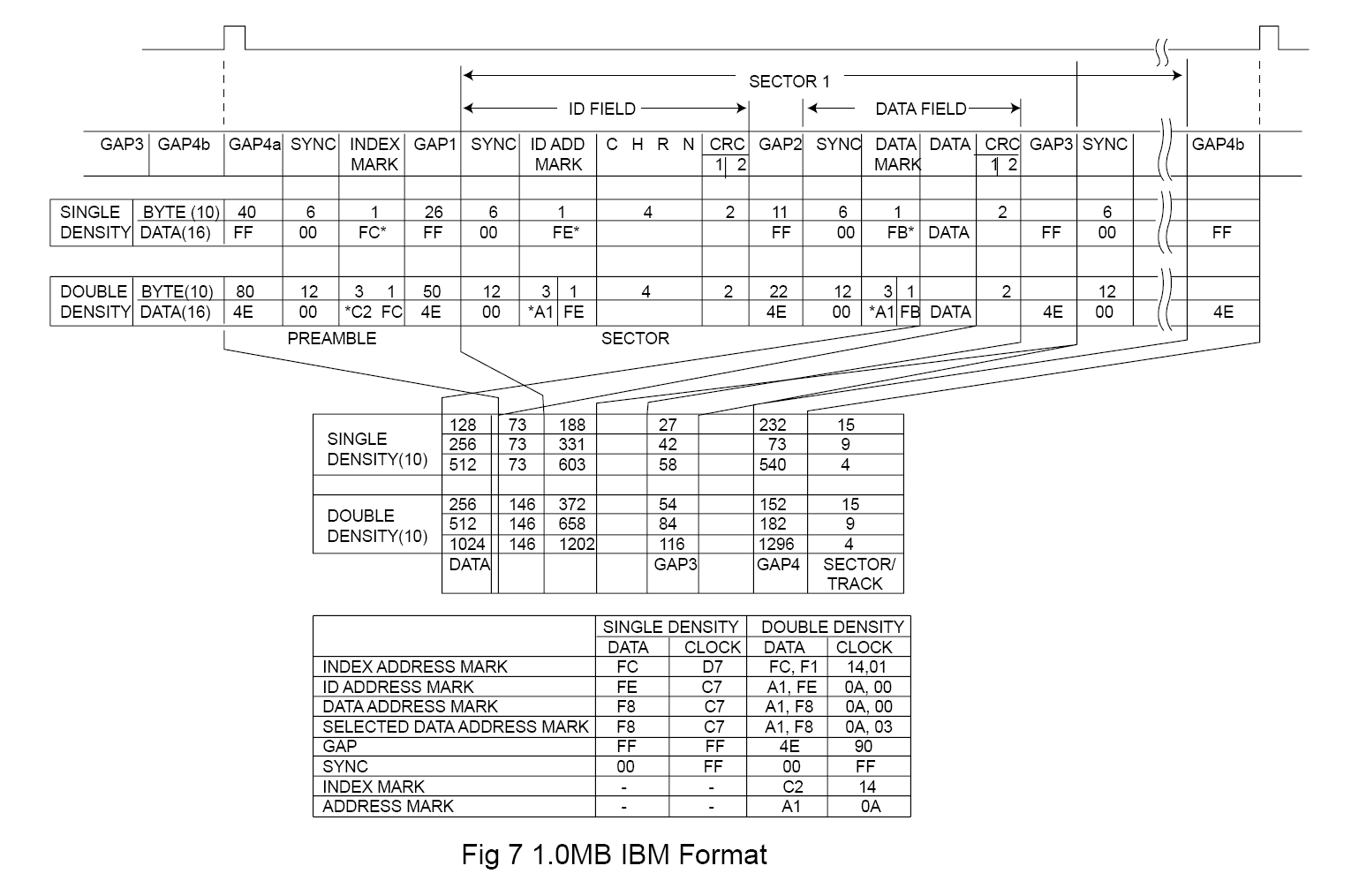{kind=link}
So it appears maybe conversion to IBM PC-style floppies (720KiB 3.5" or 360KiB 5.25") might not be quite as easy as I'd hoped, given the reliance on MFM coding exceptions that it appears the Amiga chipset floppy controller never uses (due to the track-at-once implementation).
Ewen
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
I think this is the next best thing to the NEC uPD765(A) manual -- a scan of the NEC uPD72070 manual (also saved at archive.org) via the Wikipedia page on Floppy Controllers. The NEC uPD72070 is described as being on-disc compatible with the NEC uPD765A in MFM mode (but also supports, eg, Apple ][ style GCR nibble encoding in hardware). That document also describes the use of MFM encoding errors as markers, and when they appear (or at least some of them -- eg start of track index marker; the first PDF I found, in the previous comment, appears to be a more complete description of the places where the IBM format uses MFM missing clock transition exception codes).
Ewen
from arduinofloppydiskreader.
RobSmithDev
commented on May 28, 2024
Hi actually shouldn’t be too much of an issue - the Amiga searches for the start of the sector looking for that sequence of (hex) AAAA4489, the 4489 is actually invalid MFM (done this way so it could never be treated as data) so should be ok still
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 20 Mar 2018, at 10:25, Ewen McNeill ***@***.***> wrote:
I think this is the next best thing to the NEC uPD765(A) manual -- a scan of the NEC uPD72070 manual (also saved at archive.org) via the Wikipedia page on Floppy Controllers. The NEC uPD72070 is described as being on-disc compatible with the NEC uPD765A in MFM mode (but also supports, eg, Apple ][ style GCR nibble encoding in hardware). That document also describes the use of MFM encoding errors as markers, and when they appear (or at least some of them -- eg start of track index marker; the first PDF I found, in the previous comment, appears to be a more complete description of the places where the IBM format uses MFM missing clock transition exception codes).
Ewen
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
Hi Rob,
0xAAAA4489 is really interesting to note. I'd seen it in the Amiga reference you mentioned, but I hadn't realised it too was an invalid MFM code -- presumably an invalid MFM code for the same reason the IBM 34 format does that (ie, to avoid "packet in packet" confusion with user data).
Looking closer at the source, there appear to be 3 timing buckets:
- 0-79: 2 bits, 0b01
- 80-111: 4 bits, 0b0011
- 112-max: 3 bits, 0b010
Does the third one explicitly account for the "invalid MFM, missing clock transition"? Or just do that by side effect? (I'm unclear what the PC end has to decode in the case of the missing clock transitions, ie whether it gets the on-media MFM data, or just ends up slipping off by a bit. Particularly since the IBM 34 format seems to use them in more places, including around key things like sector marks.)
Ewen
PS: I found the scanned NEC uPD765 PDF that I'd seen, so that's an Internet Archive cached version of the link (original is on a small third party Wiki). The last page has a sector "on media" layout diagram.
from arduinofloppydiskreader.
RobSmithDev
commented on May 28, 2024
Hi
The bucket system is just encoded to reduce data transfer, essentially (and this might be the wrong order) if it sees a pulse within the first bucket it sends binary 01, if in the second then it knows a flux pulse was missing and sends 10 and the third bucket 11. The pc then uncompresses this back into a raw MFM stream of ‘01’, ‘001’ and ‘0001’. Seeing as ‘00001’ isn’t allowed we don’t test that far. This isn’t allowed mainly because of something to do with needing a flux transition every so many bits anyway. You also can’t have two ‘1’s in a row so we don’t look for that either. AAAA4489 converts to binary as 10101010101010100100010010001001 which still fits the rules above and is exactly what is seen.
If you ‘MFM’ encoded the AAAA4489 you wouldn’t come out with the same sequence
Hope this helps
Regards
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 21 Mar 2018, at 06:31, Ewen McNeill ***@***.***> wrote:
Hi Rob,
0xAAAA4489 is really interesting to note. I'd seen it in the Amiga reference you mentioned, but I hadn't realised it too was an invalid MFM code -- presumably an invalid MFM code for the same reason the IBM 34 format does that (ie, to avoid "packet in packet" confusion with user data).
Looking closer at the source, there appear to be 3 timing buckets:
0-79: 2 bits, 0b01
80-111: 4 bits, 0b0011
112-max: 3 bits, 0b010
Does the third one explicitly account for the "invalid MFM, missing clock transition"? Or just do that by side effect? (I'm unclear what the PC end has to decode in the case of the missing clock transitions, ie whether it gets the on-media MFM data, or just ends up slipping off by a bit. Particularly since the IBM 34 format seems to use them in more places, including around key things like sector marks.)
Ewen
PS: I found the scanned NEC uPD765 PDF that I'd seen, so that's an Internet Archive cached version of the link (original is on a small third party Wiki). The last page has a sector "on media" layout diagram.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
Hi Rob,
Thanks again, that helps a great deal. I'd assumed that the Arduino -> PC connection was sending reconstructed "raw" MFM bits (so 500Kbps of them), based on from guesses from the timing. But from your explanation the Arduino -> PC is sending "time to next pulse" buckets, effectively in "short" / "medium" / "long" delay since last pulse. (That seems like a "pre-bucketed" version of KyroFlux's Stream Protocol, which seems to send back actual counter timings in 1/2/3 byte encodings. I think they also spot every flux reversal, rather than just the ones going in one direction.)
I should take a closer look at the exact on-disk bit patterns of the IBM 34 format's "missing transition" exceptions, but it sounds like providing there are no more than 3 on-media timing windows of 0 before a 1, it should work "as is" with those "non MFM encoded" bit patterns too. (If there's any case of "00001" it might need modifications, and figuring out some way to signal that.)
Ewen
PS: I've also figured out how to get the TEAC FD55GFR 193-U drive I plan to use (5.25" HD/DD) to spin at 300rpm (jumper settings, and appropriate tying of the density select line on the 34-pin connector); the "used in PC" ones default to always spinning at 360rpm (ie 5.25" HD speed) and just reading double density at 300Kbps instead of 250Kbps to compensate (which most "modern" floppy controllers supported); that would of course throw off all the timings here.
from arduinofloppydiskreader.
RobSmithDev
commented on May 28, 2024
Hi
The drive ‘pulses’ on a flux transition, so they are all captured here. It doesn’t mater which way it transitions which is why we just get a pulse Simon a sense works exactly the same
Regards
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 21 Mar 2018, at 08:31, Ewen McNeill ***@***.***> wrote:
Hi Rob,
Thanks again, that helps a great deal. I'd assumed that the Arduino -> PC connection was sending reconstructed "raw" MFM bits (so 500Kbps of them), based on from guesses from the timing. But from your explanation the Arduino -> PC is sending "time to next pulse" buckets, effectively in "short" / "medium" / "long" delay since last pulse. (That seems like a "pre-bucketed" version of KyroFlux's Stream Protocol, which seems to send back actual counter timings in 1/2/3 byte encodings. I think they also spot every flux reversal, rather than just the ones going in one direction.)
I should take a closer look at the exact on-disk bit patterns of the IBM 34 format's "missing transition" exceptions, but it sounds like providing there are no more than 3 on-media timing windows of 0 before a 1, it should work "as is" with those "non MFM encoded" bit patterns too. (If there's any case of "00001" it might need modifications, and figuring out some way to signal that.)
Ewen
PS: I've also figured out how to get the TEAC FD55GFR 193-U drive I plan to use (5.25" HD/DD) to spin at 300rpm (jumper settings, and appropriate tying of the density select line on the 34-pin connector); the "used in PC" ones default to always spinning at 360rpm (ie 5.25" HD speed) and just reading double density at 300Kbps instead of 250Kbps to compensate (which most "modern" floppy controllers supported); that would of course throw off all the timings here.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
Hi Rob,
FTR, I simply meant that your code seems to only capture the falling edge (high to low transition) of the flux changes/pulse, whereas it's my understanding that KyroFlux captures the timing of both the rising edge (low to high) and the falling edge (high to low) separately. Due to MFM encoding there should always be both rising and falling edges around all important points. So I think the only case that'd make a difference is archival, and particularly being able to exactly recreate the timing of the on-media rising and falling edge transitions later.
Ewen
from arduinofloppydiskreader.
RobSmithDev
commented on May 28, 2024
Hi
I’m not sure that’s how it works, the drive only detects a flux transition (magnetic pole switch), the switch denotes a ‘1’, no transition means a ‘0’. The drive never tells you which way it went, just that it happened, or not, which it signals with a short pulse.
My code just looks for the pulse.
Hope that clears things up a little.
Rob Smith
Creative/Frontend/Backend Developer
http://robsmithdev.co.uk
… On 21 Mar 2018, at 20:00, Ewen McNeill ***@***.***> wrote:
Hi Rob,
FTR, I simply meant that your code seems to only capture the falling edge (high to low transition) of the flux changes/pulse, whereas it's my understanding that KyroFlux captures the timing of both the rising edge (low to high) and the falling edge (high to low) separately. Due to MFM encoding there should always be both rising and falling edges around all important points. So I think the only case that'd make a difference is archival, and particularly being able to exactly recreate the timing of the on-media rising and falling edge transitions later.
Ewen
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
Hi Rob,
That too is very useful information! Apparently my mental model of the data at the read head was assuming an electrical signal (ie, high/low, with rising/falling edges). But of course, with the benefit of your insight, magnetism doesn't easily work like that: detecting north/south orientation of the magnetism is possible, but not easy at high speed, but detecting "hey it changed direction" at high speed is easy as there's a fairly distinctive transition edge as it moves past at "high" speed.
I hadn't realised the drive read line was "pulse per flux transition" reconstructed, but given the above background it's the obvious thing to expect. That also seems to mean that your RLE (run length encoded) bucketed timing could be turned into (approximate) KyroFlux timing files, which might allow using tools written for the KyroFlux capture format to be used (ie, pick "typical" timing values for each of the buckets, and write those out).
I continue to be impressed with just how much potential functionality you've pre-built into your Arduino server.
Ewen
from arduinofloppydiskreader.
 kollokollo
commented on May 28, 2024
kollokollo
commented on May 28, 2024
Just a thought: Would it be possible to just sample the DATA stream as fast as possible with the Arduino and let the data recontruction be done externally (by a PC)?
I see that the Arduino cannot store a whole Track in RAM this way, and also sendint the data on the fly via UART to the PC would not be possible. But one could read chuncks of say 1024 Samples, each on a single revolution of the disk with shifted start timing, some overlap so that they later can be put together. This would be slow, but It would allow to read any(!) Disk format available.
The interface would be simple: The read_chunck() function is given just a delay, which counts drom the INDEX pulse. Selecting the right delay, shifting it with some overlap, etc.. is the responsibility of the PC software.
from arduinofloppydiskreader.
ewenmcneill
commented on May 28, 2024
@kollokollo The approach you describe (sample data stream, and reconstruct later) is practical, and how the KyroFlux devices work. The Arduino devices are pretty small and slow, and basically at their limit CPU wise and uplink (serial) bandwidth wise, handling the approach used by https://github.com/RobSmithDev/ArduinoFloppyDiskReader/. So I don't think it'd be possible to send more exact timing information out (like KyroFlux) with an Arduino. In practice that seems to limit this Arduino approach to something using MFM coding (most floppy discs, but not all of them; the main other two on media encodings are FM on really old floppies, and GCR on some floppies like the Apple ][).
You're right that maybe the Arduino could buffer tiny chunks of the raw flux transition timings and send those out (not in real time), and try to figure out overlapping chunks, and try to align those overlapping chunks. But that would both be slow to capture and also present a non-trivial unpredictable problem of reassembling the track read from partial reads, since you'd have to re-align each overlapping chunk with all the others (and depending on exactly which flux transition you saw first at your, eg, +100ms read, the timings might not match at the beginning). All of which sounds very non-trivial to me.
However given more capable capture hardware, which could buffer the timings for an entire track at once, it's definitely a viable approach to just capture magnetic flux transition timings of the track and "figure it out later".
Ewen
from arduinofloppydiskreader.
kollokollo
commented on May 28, 2024
Thank you for your long answer. It is amazing, anyways, what that little Arduino can do.That all sounds really great!
from arduinofloppydiskreader.
Related Issues (20)
- Question-WD1793FDC compatible use? HOT 2
- Created Python scripts to read IBM/DOS/Commodore 1581 via ArduinoReader
- Visual Studio 2019
- Write errors in first sectors HOT 3
- Checksum errors while reading HOT 12
- Porting to RaspberryPi HOT 2
- It does not run under WindowsXP HOT 4
- Writting .d81 files HOT 1
- Broken access on Linux - firmware 1.8 HOT 4
- Inconsistent writing HOT 11
- BBC Micro - floppy drive HOT 16
- Linux capsimage segfault
- Baud rate not set correctly on macOS Ventura
- Linux compile does not work OOTB with latest desktop ubuntu
- Using Arduino Duemilanove with on-board USB UART (FT232RL) for read-only? HOT 5
- How to write on a sector
- Writing doesn't work for me HOT 15
- Ported the sketch to work with Arduino Pro Micro (Atmega32U4, 5V, 16Mhz) HOT 4
- Sucessfully read ATARI ST DD Disks (720 MBytes, 820 mBytes, 930 MBytes ) HOT 13
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from arduinofloppydiskreader.