Comments (3)
 rasbt
commented on August 16, 2024
1
rasbt
commented on August 16, 2024
1
Thanks for the note, but I think my figure is correct. The best source for this would be the original GPT-2 model implementation, which you can find here:
https://github.com/openai/gpt-2/blob/9b63575ef42771a015060c964af2c3da4cf7c8ab/src/model.py#L123-L130
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams)
x = x + m
return x, presentUnless I am reading this incorrectly, the shortcut path starts before not after LayerNorm.
from llms-from-scratch.
 d-kleine
commented on August 16, 2024
1
d-kleine
commented on August 16, 2024
1
Yes, I think you're right, including about the official code. For Pre-LN, the residual connection starts with the shortcut before the layer normalization step, which is nicely illustrated in your figure here and the official illustration of Pre-LN on the far right side:
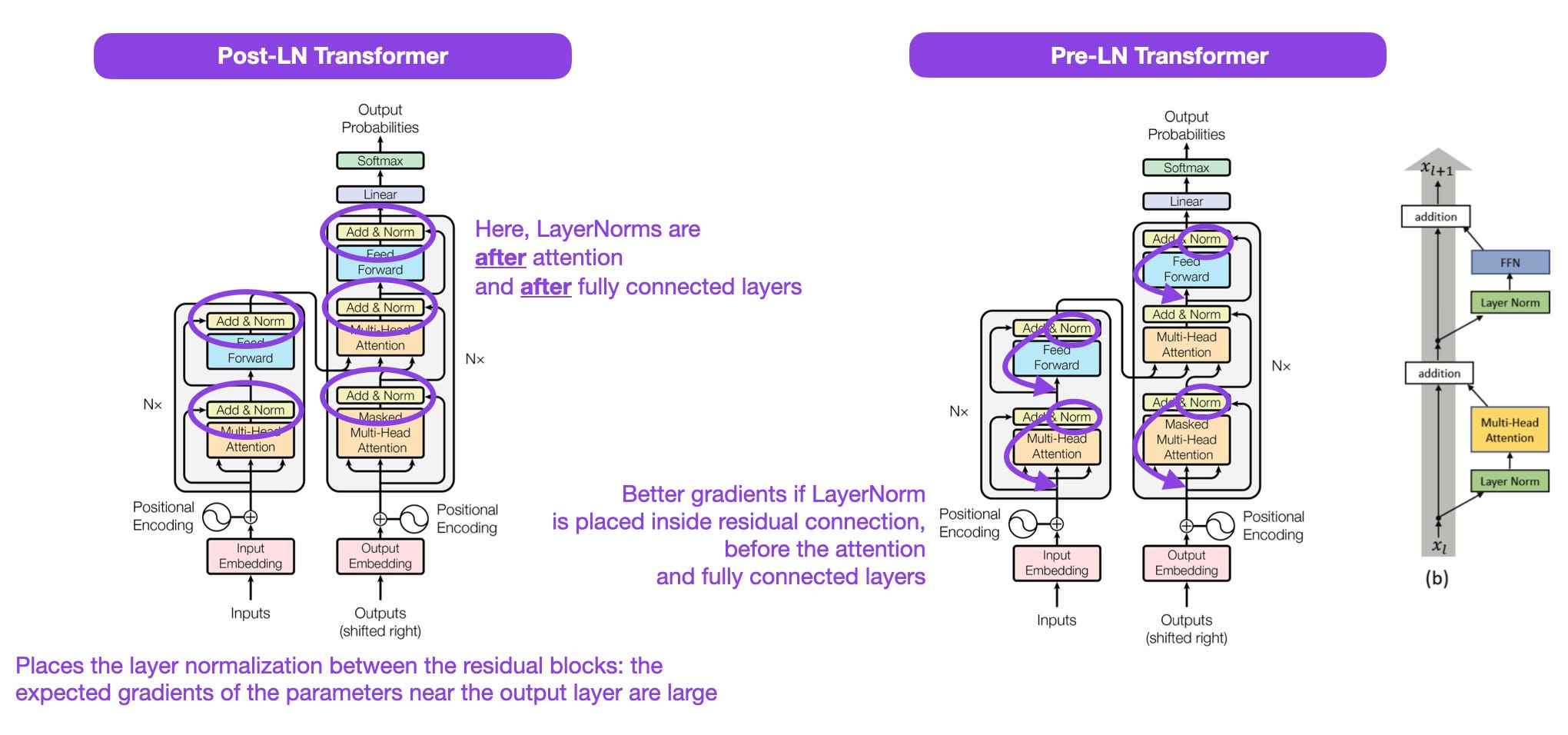
Apologies - I have only found a few graphics illustrating the GPT-2 architecture, and it seems like all of them were incorrect about the Pre-LN step (even on Wikipedia, surprisingly).
Thanks again, and issue can be closed then 🙂
from llms-from-scratch.
rasbt
commented on August 16, 2024
1
Nice, I am glad that it all makes sense now (and also looks correct haha). Thanks for raising this issue though, it's always good to have multiple sets of eyes on these things!
from llms-from-scratch.
Related Issues (20)
- 2.7 Creating token embeddings - Text in bold print HOT 2
- Inconsistent vocabulary sizes mentioned in the same section (2.3 Converting tokens into token IDs) HOT 1
- Ch-07 instruction tuning HOT 3
- The GPT 2 Model url link needs to be corrected HOT 3
- Duplicated line in the Listing 2.6 (2.6 Data sampling with a sliding window) HOT 1
- Detaching a Tensor from the graph doesn't have effect (Embedding Layers and Linear Layers) HOT 3
- (Enhancement) Applying mask to attention in one operation (3.5 Hiding future words with causal attention) HOT 2
- Inconsistency in cases for applying dropout in the book and in the notebook (3.5.2 Masking additional attention weights with dropout) HOT 3
- Question of training on conversational datasets HOT 1
- generate_model_scores function bug? HOT 3
- lower validation&train loss with poorer performance
- Several typos/questions (Sections 4.1-4.2) HOT 1
- Edge case: Gradient accumulation HOT 3
- Typo of figure labeling? (5.1.2 Calculating the text generation loss) HOT 1
- An unusual link in the pdf version (5.1.2 Calculating the text generation loss) HOT 1
- Different figures in the book and jupyter notebook for Figure 5.9 (5.1.3 Calculating the training and validation set losses) HOT 1
- Inconsistencies in the book and Jupyter notebook (5.2 Training an LLM) HOT 4
- Missing word in a sentence (5.3.1 Temperature scaling) HOT 4
- Output and code cells are in the wrong order (5.3.1 Temperature scaling) HOT 1
- Incorrect formatting of the text as code (5.3.1 Temperature scaling) HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from llms-from-scratch.