Comments (11)
 CrohnEngineer
commented on June 14, 2024
1
CrohnEngineer
commented on June 14, 2024
1
@nicobonne I re-opened the issue even though we fixed the bad naming for the result DataFrame, so @yksolanki9 can get in touch with us.
from icpr2020dfdc.
 nicobonne
commented on June 14, 2024
nicobonne
commented on June 14, 2024
Those are not folders, but parameters for specific dataset splits. Have you tried run the train with ff-c23-720-140-140?
from icpr2020dfdc.
CrohnEngineer
commented on June 14, 2024
Hey @yksolanki9 ,
Hey, I am trying to train the model using train_triplet.py. I can see that you have passed the ff-c23-720-140-140 directory as value for train_db
The parameter ff-c23-720-140-140 is not the directory of the FF++ dataset, but an argument used by the function make_split of split.py to create the training and validation splits during training, given the Pandas Dataframe containing all the info on the faces created by extract_faces.py.
Please refer to the bash scripts if you have any doubt about the meaning of the parameters used in any of the scripts of this repo.
Hope this helps!
Edoardo
from icpr2020dfdc.
 yksolanki9
commented on June 14, 2024
yksolanki9
commented on June 14, 2024
Okay. I tried running train_triplet.py using:
python3 train_triplet.py --net EfficientNetB4 --traindb ff-c23-720-140-140 --valdb ff-c23-720-140-140 --ffpp_faces_df_path facesdf/faces_df_from_video_0_to_video_0.pkl --ffpp_faces_dir faces/ --face scale --size 224
I got the following output:
Loaded pretrained weights for efficientnet-b4
Parameters
{'face': 'scale',
'net': 'EfficientNetB4',
'seed': 0,
'size': 224,
'traindb': 'ff-c23-720-140-140'}
Tag: net-EfficientNetB4_traindb-ff-c23-720-140-140_face-scale_size-224_seed-0
Loading data
Training triplets: 0
Validation triplets: 0
No training triplets. Halt.
Why is it not detecting any triplets?
Thank you!
from icpr2020dfdc.
CrohnEngineer
commented on June 14, 2024
Hey @yksolanki9 ,
It is not detecting any triplets because in the faces Dataframe you gave as argument there are faces from a video only (facesdf/faces_df_from_video_0_to_video_0.pkl) :)
In order to generate a triplet batch (in your example of size 1) you need at least 6 videos (3 FAKE, 3 REAL), and that is for training only, so double it up for having at least 1 triplet for validation also.
Moreover, keep in mind that when generating the splits for training, we are assuming that your faces_df is complete (i.e. you extracted the faces from all videos).
Bests,
Edoardo
from icpr2020dfdc.
yksolanki9
commented on June 14, 2024
Hey,
It is not detecting any triplets because in the faces Dataframe you gave as argument there are faces from a video only (facesdf/faces_df_from_video_0_to_video_0.pkl) :)
When I ran extract_faces.py on the whole FFPP dataset using:
python3 extract_faces.py --source dataset/ffpp/faceforensics/ --videodf data/ffpp_videos.pkl --facesfolder faces/ --facesdf faces_df/ --checkpoint checkpoints/
Only one .pkl file named faces_df_from_video_0_to_video_0.pkl was generated in faces_df/ folder. Did I miss something here?
Thank you
from icpr2020dfdc.
CrohnEngineer
commented on June 14, 2024
Hey @yksolanki9 ,
Only one .pkl file named faces_df_from_video_0_to_video_0.pkl was generated in faces_df/ folder. Did I miss something here?
You are not missing anything: I have checked the code, and the name you got for the result DataFrame from running the extact_faces.py is correct.
I know the naming convention is not straightforward (I got confused too lol 🙃) , so I will change it in the next commit (sorry for the inconvenience).
Just for a check, can you please tell me how many records the faces_df_from_video_0_to_video_0.pkl DataFrame contains?
All the other arguments you provided for the train_triplet.py script seems correct, however, can you please check also if the directory --ffpp_faces_dir faces/ contains all the faces extracted?
As a cross-check, can you please verify if there is any mismatch between the paths contained in the faces_df_from_video_0_to_video_0.pkl DataFrame and the faces in --ffpp_faces_dir faces/?
Sorry for all the questions, but it seems to me that there might be some parameter (either the directory where the faces have been saved, or the DataFrame with the info about them) that has something off, so we would like to check these things first.
Bests,
Edoardo
from icpr2020dfdc.
yksolanki9
commented on June 14, 2024
Hey,
Part 1
how many records the faces_df_from_video_0_to_video_0.pkl DataFrame contains?
For this, I ran the following code:
import pandas as pd
faces_df_pkl_path = "/home/chinmay/Desktop/icpr2020dfdc/facesdf/faces_df_from_video_0_to_video_0.pkl"
unpickled_df = pd.read_pickle(faces_df_pkl_path)
print("Total records in faces_df_from_video_0_to_video_0.pkl: ",len(unpickled_df.index))
Output:
Total records in faces_df_from_video_0_to_video_0.pkl: 300599
Part 2
check also if the directory --ffpp_faces_dir faces/ contains all the faces extracted?
To check this, I counted the number of jpg files in the faces directory using:
from glob import glob
faces_path = "/home/chinmay/Desktop/icpr2020dfdc/faces/"
faces_list = glob(faces_path + '**/*.jpg',recursive=True)
print("Total faces in faces/ directory: ", len(faces_list))
Output:
Total faces in faces/ directory: 300599
Part 3
verify if there is any mismatch between the paths contained in the faces_df_from_video_0_to_video_0.pkl DataFrame and the faces in --ffpp_faces_dir faces/?
-
Printing the whole Faces Dataframe:
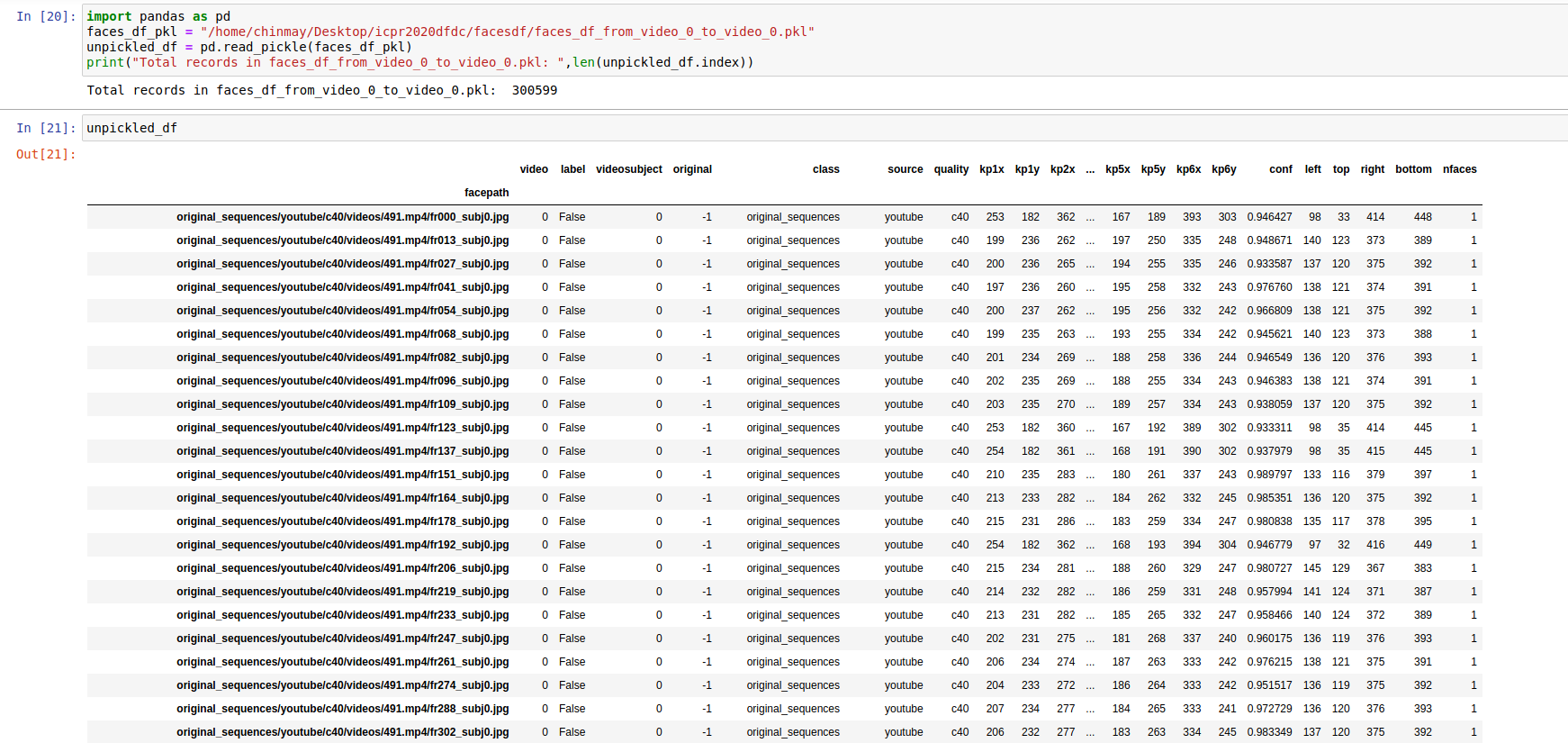
-
Printing paths of faces (.jpg files) inside faces/ directory:
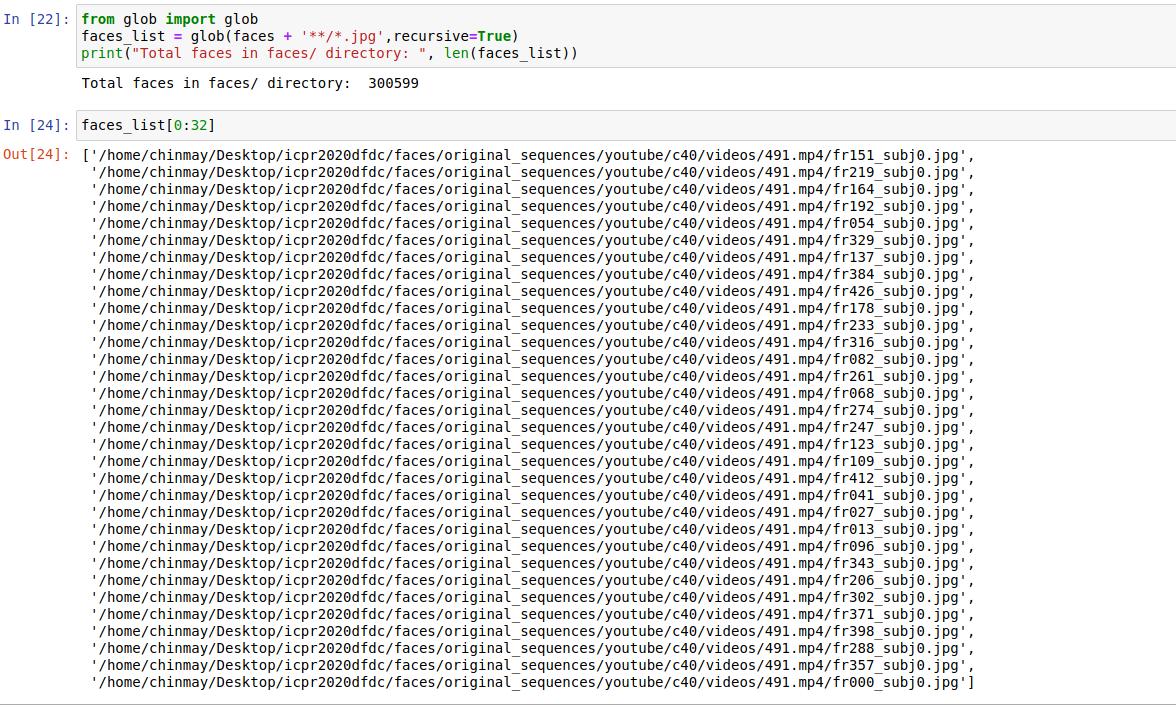
Obseravtions:
-
Total records in faces_df_from_video_0_to_video_0.pkl: 300599
-
Total faces (i.e .jpg files ) in faces/ directory: 300599
-
Total videos in FFPP dataset: 9431
-
In extract_faces.py, the default argument of fpv(frames per video) is 32.
-
So there should be 9431*32 = 301792 faces in the faces/ directory. But we only got 300599 faces.
-
It can be assumed that the face extractor could not find faces in some frames of some videos. Due to this, there are 301792 - 300599 = 1193 fewer faces in the faces/ directory.
-
From Part 3, the facespath as printed in the faces Dataframe is not the absolute path of the image. The absolute path of all the images is seen in the second image that I have uploaded in Part 3
Thank You
from icpr2020dfdc.
CrohnEngineer
commented on June 14, 2024
Hey @yksolanki9 ,
From Part 3, the facespath as printed in the faces Dataframe is not the absolute path of the image. The absolute path of all the images is seen in the second image that I have uploaded in Part 3
That's OK! When we load the faces using the FrameFaceIterableDataset function load_face, in line 28 we reconstruct the full-path for loading.
I don't see any mismatch between the index in the faces DataFrame and the directory containing the extracted faces you got, so I don't think that's the problem.
Total records in faces_df_from_video_0_to_video_0.pkl: 300599
Total faces (i.e .jpg files ) in faces/ directory: 300599
Total videos in FFPP dataset: 9431
In extract_faces.py, the default argument of fpv(frames per video) is 32.
So there should be 9431*32 = 301792 faces in the faces/ directory. But we only got 300599 faces.
It can be assumed that the face extractor could not find faces in some frames of some videos. Due to this, there are 301792 - 300599 = 1193 fewer faces in the faces/ directory.
Your numbers seem fine to me, but I think the issue lies here.
On our side the total number of videos is 16499, while the total number of faces 612834.
I see from the pictures you posted only entries for the quality factor c40: are you considering only those types of videos?
If that is correct, keep in mind that we use only the quality factor c23 for training and testing.
Therefore, when we take the split for training and validation calling the make_split function at line 226, we subsequently call the function get_split which, at line 58, considers only videos at quality factor c23.
If your DataFrame has entries only for c40, then the split will have no records and therefore the training stops since the DataLoader doesn't find any triplet: can you please check this?
Hope everything is clear, let me know if the issue persists.
Bests,
Edoardo
from icpr2020dfdc.
yksolanki9
commented on June 14, 2024
Hey,
I tried running the train_triplet.py after changing the quality factor at line 58 to df['quality'] == 'c40' in get_splt_df function of split.py. It detected all the triplets for training and validation. The training has started as expected. I haven't got any errors till now(after changing the quality factor to c40). I will download the c23 dataset and re-run the code as well.
Thank you for your help. I really appreciate it. :)
from icpr2020dfdc.
CrohnEngineer
commented on June 14, 2024
Hey @yksolanki9 ,
You're welcome, I'm glad we solved this!
Thank you for reaching out and checking our code :)
Have a nice weekend!
Edoardo
from icpr2020dfdc.
Related Issues (20)
- Facing error while running train_all.sh HOT 2
- Celebdf dataset HOT 1
- Can't find the file data_frame_df.pkl HOT 3
- network doesn't generalize well HOT 3
- Query HOT 4
- Unable to find "List_of_testing_videos.txt" HOT 1
- Source code of Ensemble models HOT 18
- index_dfdc errror HOT 2
- DFDC split HOT 1
- Question about the returned RuntimeError when using the Celeb-DF dataset HOT 7
- what is embedding_routine function used for? HOT 1
- how to set validation split for dfdc? HOT 4
- use pre-trained model to detect my videos, but filter out some specific datasets on the pre-train which may overlap HOT 2
- regarding attention heatmap HOT 1
- Training dataset for DFDC HOT 1
- models pretrained on DFDC works well, but why models pertrained on FFPP always give a low score? HOT 1
- EnvironmentNameNotFound: Could not find conda environment: icpr2020 HOT 3
- About Image prediction notebook on Colab HOT 3
- val_sample HOT 1
- Regarding Top-up Training to improve the accuracy of existing deepfake model
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from icpr2020dfdc.