Comments (24)
 parrt
commented on May 14, 2024
1
parrt
commented on May 14, 2024
1
Ok, i think this was because compute_class_weight() was called even for regressors, but it only makes sense for classifiers. ALSO, it sounds like maybe your tree_y was not a simple 1D array but maybe 2D.
from dtreeviz.
parrt
commented on May 14, 2024
it wants a list not an array for sure, but not sure why your list doesn't work. what type is boston.feature_names?
from dtreeviz.
 grilhami
commented on May 14, 2024
grilhami
commented on May 14, 2024
@parrt When I print it on Jupyter notebook, the output looks something like this
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'],
dtype='<U7')
It has a dtype of <U7. I tried to math my array as the same data type, but it still spits out the same error.
from dtreeviz.
parrt
commented on May 14, 2024
@grilhami Hmm...it can't be the features as this works:
>>> import numpy as np
>>> np.array(['a','b','c'])
array(['a', 'b', 'c'], dtype='<U1')
>>> x = np.array(['a','b','c'])
>>> set(x)
{'a', 'c', 'b'}
>>>
It must be the class weights passed to the tree model. can you print regr.class_weight for me?
from dtreeviz.
 JSAN730
commented on May 14, 2024
JSAN730
commented on May 14, 2024
I'm getting the same issue... has this been fixed?
from dtreeviz.
JSAN730
commented on May 14, 2024
regr.class_weight is none for me
from dtreeviz.
parrt
commented on May 14, 2024
@JSAN730 are you using 0.3.3 dtreeviz?
from dtreeviz.
JSAN730
commented on May 14, 2024
Yup, I'm using 0.3.3 dtree viz
from dtreeviz.
parrt
commented on May 14, 2024
Damn. ok, if you send me a small test.py and a sample dataset (or pull from sklearn), I'll track it down
from dtreeviz.
JSAN730
commented on May 14, 2024
I was assuming that feature_names was just a list of the column names for the data with predictor variables. I'll send you the test.py and sample dataset. Below is my code:
features = list(vf_ulta_per_data)
viz = dtreeviz(regr,
vf_ulta_per_data,
vf_ulta_per_target,
target_name= 'VF % ULTA 2018', # this name will be displayed at the leaf node
feature_names=features
)
viz
from dtreeviz.
parrt
commented on May 14, 2024
Hmm...yeah, that should work. let's figure this out. you can email me at [email protected]
from dtreeviz.
parrt
commented on May 14, 2024
I'm getting a different error than was reported. Is this what you see @JSAN730 ?
ValueError Traceback (most recent call last)
<ipython-input-1-c47ac4c24103> in <module>
27 vf_ulta_per_target,
28 target_name= 'VF % ULTA 2018', # this name will be displayed at the leaf node
---> 29 feature_names=features
30 )
31 viz
~/anaconda3/lib/python3.7/site-packages/dtreeviz-0.3.2-py3.7.egg/dtreeviz/trees.py in dtreeviz(tree_model, X_train, y_train, feature_names, target_name, class_names, precision, orientation, show_root_edge_labels, show_node_labels, fancy, histtype, highlight_path, X, max_X_features_LR, max_X_features_TD)
681
682 shadow_tree = ShadowDecTree(tree_model, X_train, y_train,
--> 683 feature_names=feature_names, class_names=class_names)
684
685 if X is not None:
~/anaconda3/lib/python3.7/site-packages/dtreeviz-0.3.2-py3.7.egg/dtreeviz/shadow.py in __init__(self, tree_model, X_train, y_train, feature_names, class_names)
68 self.unique_target_values = np.unique(y_train)
69 self.node_to_samples = ShadowDecTree.node_samples(tree_model, X_train)
---> 70 self.class_weights = compute_class_weight(tree_model.class_weight, self.unique_target_values, self.y_train)
71
72 tree = tree_model.tree_
~/anaconda3/lib/python3.7/site-packages/sklearn/utils/class_weight.py in compute_class_weight(class_weight, classes, y)
40
41 if set(y) - set(classes):
---> 42 raise ValueError("classes should include all valid labels that can "
43 "be in y")
44 if class_weight is None or len(class_weight) == 0:
ValueError: classes should include all valid labels that can be in y
from dtreeviz.
JSAN730
commented on May 14, 2024
Yes, I'm getting that same message.
ValueError: classes should include all valid labels that can be in y
from dtreeviz.
parrt
commented on May 14, 2024
ah. well, isn't that supposed to be same?
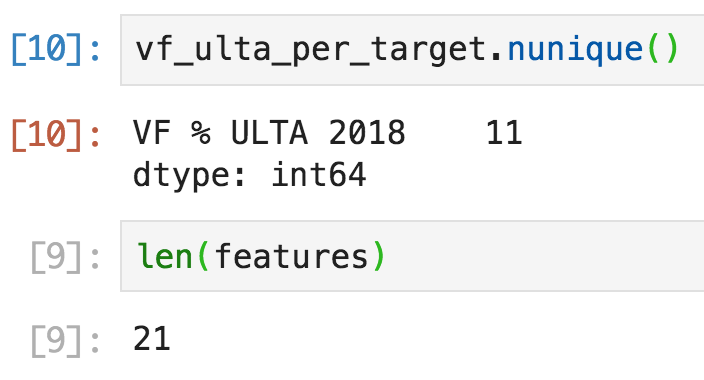
from dtreeviz.
JSAN730
commented on May 14, 2024
how should I code it if the target is a continuous variable (like sales) and I'm using the other columns in the dataset to create a regression tree as predictor variables?
from dtreeviz.
parrt
commented on May 14, 2024
if continuous, then it's regression so you can't use class_weights. Maybe you want sample_weights?
from dtreeviz.
JSAN730
commented on May 14, 2024
That's correct, I'm trying to run a regression tree. I'm new to python, I'll try to find where I can replace class_weights to sample_weights. I thought the tree.DecisionTreeRegressor() took care of that.
from dtreeviz.
parrt
commented on May 14, 2024
The term "class" is meant for classifiers so that arg is definitely not the one you want. :)
from dtreeviz.
 lucas817
commented on May 14, 2024
lucas817
commented on May 14, 2024
I'm having the same issue (ValueError: classes should include all valid labels that can be in y). I don't fully understand the previous discussion: is this a bug that will be fixed, or is there a way to make the function not try to use class weights on a regression tree? Because as it is the only regression trees that can be visualised are the ones from built-in datasets like the boston one, which would be a shame.
from dtreeviz.
parrt
commented on May 14, 2024
I wonder if you are mixing up regression versus classifier. Classifiers are the only ones that need to pass in the target class names. There are no such things for a regressor, which predicts a numeric value.
from dtreeviz.
lucas817
commented on May 14, 2024
I know what the difference between regression and classification is, I'm a statistician. My point is that the error appears every time, whether you pass a regression model or a classifier, it makes no difference. The only way I've gotten this to work is with built in datasets like iris and boston. Is this package only meant to be used with those or can it also be used with pandas dataframes (and if so, how)?
from dtreeviz.
parrt
commented on May 14, 2024
oh! Sorry. I've used on all sorts of datasets. Can you send me a failing example? I'll track it down! [email protected] It must be a weird data type issue with the list of feature names.
oh, so if you pass nothing or None, you also get an error? weird
from dtreeviz.
JSAN730
commented on May 14, 2024
for me, I changed the target dataset a numpy array and it worked
penetrationtarget = np.array(penetrationbeddf_c['vf_penetration'])
from dtreeviz.
parrt
commented on May 14, 2024
oh! yeah, it has to be a dataframe series or a numpy array I think. what type are you passing in? i can update.
from dtreeviz.
Related Issues (20)
- from dtreeviz.trees import * Import necessary libraries HOT 1
- Color keyword argument - Value error HOT 14
- Add support for TensorFlow GradientBoostedTreesModel model
- _regr_leaf_viz calculates the mean for prediction value.
- WARNING:matplotlib.font_manager:findfont: Font family 'Arial' not found. HOT 2
- Decision Tree visualize wrong path HOT 1
- When using dataset that is different from the training for trees models - does not draw HOT 1
- Support for RandomForest HOT 5
- Visualize custom decision tree HOT 1
- how to use dtreeviz in streamlit HOT 2
- VisualisationNotYetSupportedError: get_min_samples_leaf() is not implemented yet for XGBoost. HOT 4
- TypeError: list indices must be integers or slices, not numpy.float64 HOT 5
- Crash when leaf nodes have no samples HOT 1
- Out of memory when calling viz.view() HOT 2
- Integrate AI explanation
- CatBoost need to be supported. HOT 1
- AttributeError: module 'dtreeviz' has no attribute 'model' on Windows platform, works fine on Google colab
- tfdf.keras.CartModel support? HOT 1
- TypeError: 'int' object is not subscriptable HOT 3
- Development requirement in `setup.py` HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from dtreeviz.