Comments (10)
 PatriceVignola
commented on July 21, 2024
1
PatriceVignola
commented on July 21, 2024
1
If you already have a trained python TensorFlow model, you could freeze it into a .pb file and use the tensorflow-directml C API to load it at runtime. Would that be a good solution for you?
Once your model has been converted to a frozen .pb file, you can use the C API to load it with TF_LoadSessionFromSavedModel and then call TF_SessionRun.
I believe this is the most straightforward and fastest way to get your model working with DirectML. If you need help navigating the TensorFlow C API, please let us know!
Edit: Alternatively, if you are familiar with ONNX and can convert your model to an ONNX model, you could even use onnxruntime instead of TensorFlow, which can use DirectML underneath.
from tensorflow-directml.
PatriceVignola
commented on July 21, 2024
1
Hi @MarkHung00,
I created a basic sample over here. The sample goes through the process of loading a frozen squeezenet.pb model, creating a graph from it and finally creating a session. Feel free to extract the parts that are relevant for you and let me know if you run into any issues or have other questions!
from tensorflow-directml.
PatriceVignola
commented on July 21, 2024
1
@MarkHung00 tensorflow-directml supports a subset of the operators supported by the default GPU (CUDA) device. To see which data types each operator supports, you can look at the source. For example, for Gather:
For example, FP32 and FP16 is the data type the most commonly supported across DML operators, while int32 is reserved for CPU instead.
from tensorflow-directml.
PatriceVignola
commented on July 21, 2024
1
- For TensorFlow performance tuning, most of the tools that work for CUDA also work for DirectML. For example, we like to use the chrome tracing format outlined in the post since it shows a good timeline of all operators that are being executed, and is easy to read.
- Yes, each operator has a different list of data types that it supports. For example, if you look at the bottom of the Convolution page, you see that it supports float16 and float32.
- DirectML performance on Intel heavily depends on the devices, but we're working with them to make sure that DirectML becomes a competitive framework on their platform.
Also, take note that this repository (tensorflow-directml 1.15) is mostly in maintenance mode. We're still doing bug fixes and improving performance, but we're now more focused on the preview of our plugin for TF 2. We don't have a C API for the plugin yet, but it's coming soon!
from tensorflow-directml.
 MarkHung00
commented on July 21, 2024
MarkHung00
commented on July 21, 2024
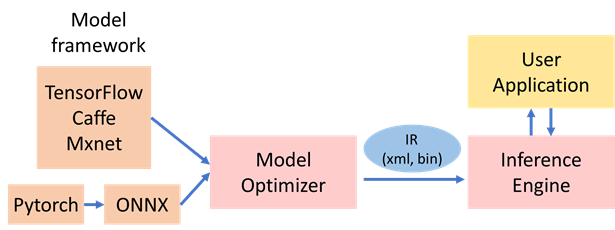
From the DirectML sample, it is necessary to implement each operand in C++. Whether there is a similar Intel OpenVino, you can convert the tensortflow model into IR through the model optimizer, and let the C++ program load the IR .
https://miro.medium.com/max/1230/1*c83JJoHVHOXNGapF1JT86Q.png
Because the camera post process DMFT of windows is in the C++ environment, it will be more convenient to use if we can load the tensorflow model in the C++ environment
{kind=link}
from tensorflow-directml.
MarkHung00
commented on July 21, 2024
Hi PatriceVignola,
Thank you very much for the information, it's very helpful to us. There seems to be no complete sample code of TF_LoadSessionFromSavedModel on the Internet.
Do you have relevant information or sample demo code, we can have a trial, thanks!
from tensorflow-directml.
MarkHung00
commented on July 21, 2024
Hi PatriceVignola,
Thank you very much for your assistance, we have successfully run with Visual Studio, and will use other models in the next stage,
In addition to the recommended operator mentioned in the link below, is there any restriction on the data type (ex: does DirectML Tensorflow support FP32/FP16/INT16/INT8)
https://docs.microsoft.com/en-us/windows/ai/directml/dml-intro
Thanks a lot
from tensorflow-directml.
MarkHung00
commented on July 21, 2024
Thanks a lot, We are currently developing some real time scenarios. The inference time of Nvidia GPU is still satisfactory. We have some questions
-
For tensorflow model, does DirectML have performance tuning guide or performance evaluation tools
-
From the information in the link below, does it mean that per operator(layer) data type can be difference
(the article mention that==>see the documentation for each specific operator to find which data types it supports.)
https://docs.microsoft.com/en-us/windows/win32/api/directml/ne-directml-dml_tensor_data_type -
From the link below from Intel, DirectML v.s Open, the openvino seems have better performance, we hope to know how to modify the tensorflow model to best fit directml
https://www.intel.cn/content/www/cn/zh/developer/articles/technical/effective-deployment-ai-workloads-with-xe.html
We hope that the inference framework can flexibly use various GPUs (Intel/AMD/Nvidia), directml is good choice, but in the future there may be models that require more computing power and longer inference time
from tensorflow-directml.
MarkHung00
commented on July 21, 2024
Highly appreciate your help, in addition, we have two questions
-
We may have scenarios where multiple models are inference at the same time. From the DirectML tensorflow c lib, we can select CPU or DirectML supported GPU from TF_ImportGraphDefOptionsSetDefaultDevice, but if there are two models and "only Nvidia GPU can achieve" realtime performance, we'd like to know, on the user side we can do multi thread to call TF_SessionRun, DirectML scheduling, is the execution order schedule by FIFO, or there are other scheduling mechanisms or the priority we can optimize the execution order
-
CONV operator only supports FP16, we'd like to know if DirectML supports Quantization aware training(QAT)
thanks again for your great help!
from tensorflow-directml.
PatriceVignola
commented on July 21, 2024
- Before trying to do multithreading, I would suggest looking at the GPU usage for a single model. Ideally, most models should run near 100% GPU usage and therefore multithreading won't help and may even make it slower due to context switch and higher memory usage. If your model has poor GPU usage, we'd like to help you investigate what the problem is in order to make it better!
- DirectML has quantization support, but tensorflow-directml doesn't have it at this time.
from tensorflow-directml.
Related Issues (20)
- Not able to use my own callbacks HOT 3
- Tensorflow-directml is not making any difference in processing times in GPU vs CPU HOT 1
- AMD APU support? HOT 2
- Cannot assign a device for operation embedding/embeddings/Initializer/random_uniform/ HOT 5
- directml on custom tensoflow build ? HOT 1
- It's not working on Intel Graphics 5500 HOT 1
- Use c api to load pb models HOT 1
- how to set the default device using cAPI?
- session run crashed when runing on nvidia gpu HOT 1
- Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support. HOT 2
- unbox expects Dml at::Tensor as inputs HOT 1
- Is it not supports the amd gpus without rocm?
- Does directml support multi-GPU training
- TensorFlow-DirectML Does Not Exist HOT 7
- AttributeError: module 'tensorflow' has no attribute 'float32' HOT 1
- CPU instructions notification after installing
- python newer versions support
- tensorflow GPU on WSL2 produces a segmentationfault
- RC astro tool operations not supported in DirectML HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from tensorflow-directml.