Comments (22)
 luoyetx
commented on June 7, 2024
luoyetx
commented on June 7, 2024
would you mind to paste your test code?
from mini-caffe.
 yonghenglh6
commented on June 7, 2024
yonghenglh6
commented on June 7, 2024
In mini-caffe, I just add a "for(int i=0;i<100;i++)" before "test.Forward();" in run_net.cpp, and get the time from your output.
In caffe, I use the caffe time, which is a mistake for memory use because it includes the backward process.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
I get the memory use from "nvidia-smi" with watching in the flesh.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
would u like to put up your performance with the resnet for a bug checking of mine? Thank you.
from mini-caffe.
luoyetx
commented on June 7, 2024
I will test the network prototxt on 1070 later. With more details on mini-caffe and official caffe.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
I use those code to test your every layer's time. But cannot find the reason.

And the result is:

from mini-caffe.
yonghenglh6
commented on June 7, 2024
Your net->Forward(2,3) give me an error. So I can only use net->Forward(0,x) to get the time from the begin and sub them.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
As the net get longer, the performance diff between mini-caffe and caffe become larger, when I test them by adding layer step by step for net construction.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
Update the performance up.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
I checked the cudnn and assured it ran well by adding some output info.
from mini-caffe.
luoyetx
commented on June 7, 2024
please refer to profile.md to check the layer wise performance. I am writing tools to do the network benchmark.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
I have tried Profile in the beginning, but the time shown in chrome is not consistent with my test result. However, it's most possible that I made the wrong usage way.
from mini-caffe.
luoyetx
commented on June 7, 2024
Pay attention to the Timer, it's not accuracy, use Profiler::Now() instead.
from mini-caffe.
luoyetx
commented on June 7, 2024
@yonghenglh6 You can try the benchmark branch, I modify the Profiler log, it now prints layer name not layer type. You can get same layer wise performance through profile.json
from mini-caffe.
luoyetx
commented on June 7, 2024
I find the performance is not stable under Windows platform, I will test on Linux later.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
With your new benchmark tool, I found the bn layer is the main part that cause the difference, your bn is cost twice time than conv. So I changed to test it on google without bn layer and the result shows similar performance between caffe and mini-caffe.
Here is the details. By the way, my caffe use atlas lib, which I think it's not important.
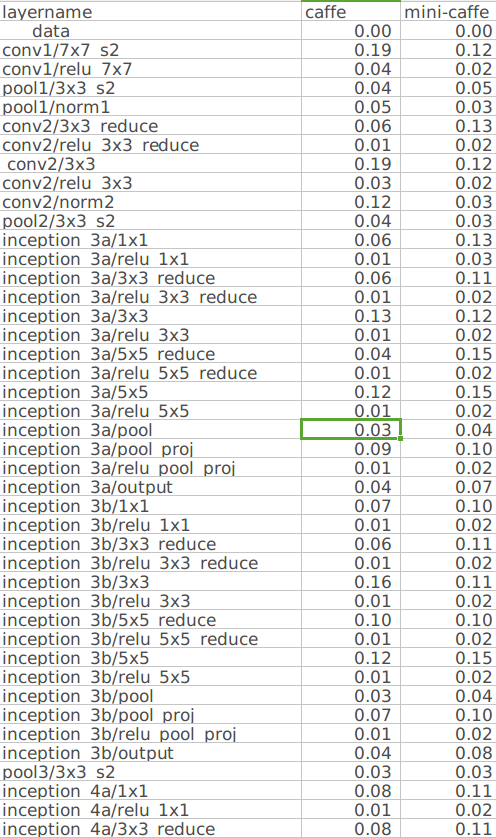
from mini-caffe.
luoyetx
commented on June 7, 2024
There is an optimization in this commit for BatchNorm Layer. I will update this from official caffe.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
Everytime you request memory from pool, the blob will be in uninitial state, then it will call gpu_memset function in "to_gpu()", which will cost about 10% time more than original caffe whose blob will be keeped and in head_on_gpu state.
from mini-caffe.
luoyetx
commented on June 7, 2024
The default behave is the same in official Caffe here.
from mini-caffe.
yonghenglh6
commented on June 7, 2024
Yes, but the official Caffe need not reallocate blob every forward and not call the function frequently. But your minicaffe keeping on setting the blob state to uninitial to reuse the memory and then rememset the memory when calling to_gpu(), which has caused a performance problem.
It can be optimized by designing the memset moment in layers carefully instead of doing it everytime "to_gpu()" called.
In short words, this may be a problem of only minicaffe, even the code is the same
from mini-caffe.
luoyetx
commented on June 7, 2024
you mean this function? It is a problem that this function called every time a new memory is requested. I think we can remove this function call, as the dirty data in the memory seems no problem for late use. What do you think?
from mini-caffe.
yonghenglh6
commented on June 7, 2024
Yes.
from mini-caffe.
Related Issues (20)
- linux
- mini-caffe 可以设置多GPU吗?
- 最新的代码还是会在退出时报内存错误啊 HOT 2
- pthread_create HOT 1
- if using opencv, then how to modify "mini-caffe.cmake"
- Adding SYCL backend for Mini Caffe
- 最新版本在程序运行example中程序退出时候报错,旧版本不存在此问题 HOT 2
- Memory Leak when using Threads HOT 2
- 你好,我在编译mini-caffe遇到链接错误的问题
- libopenblas.dll HOT 1
- cmake cannot find and configure cuda10 correctly
- Layer::Forward does not work when inference faster-rcnn HOT 6
- About LSTM layer.
- Windows编译出错!!
- Unsupported gpu architecture 'compute_92' HOT 4
- error: ‘exp’ was not declared in this scope HOT 4
- win10+cmake+cuda10.0+cudnn7.3.1, i have the problem that Running GPU detection script with nvcc failed: detect_cuda_archs.cu HOT 2
- scale.cpp
- SSD mobilenet 测试问题
- 编译win 32位,出现的问题 HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from mini-caffe.