Dart 是一门面向对象的编程语言,它就像是所有语言的优点都集中在一起,包括 JS 中异步函数 async / await、java 和 c# 中的强类型以及范型等。
编译模式
Dart 是一门既支持 JIT(即时编译)也支持 AOT(提前编译)的语言。何解?
所谓的 JIT(即时编译),就像 JS 那样在本地开发时,对于开发的代码只需要保存后,直接就能在客户端内得到体现。优点就是在开发期间内能够做到快速开发(如热重载),缺点就是每次即时编译都需要将代码动态编译成机器码,直观上可能会造成一些小卡顿(毕竟编译时需要时间鸭😅当然对于电脑配置高还是会没啥问题)。
另外,AOT(提前编译)就是针对在发布前,提前将源代码编译成机器码,这样对于客户端来说,加载二进制代码会更加快。
常用数据类型
Dart 数据类型中,支持 num 类型、String 类型、bool 类型、list 集合类型(即数组)、Map 类型以及 Set 类型,额外的类型还有 var 类型、dynamic 类型以及 Object 类型。
num类型
num 类型中有两种子类,分别是 int 类型和 double 类型。看个🌰你就会明白。
void initNum() {
num a = 1; // 定义整数类型
num b = 1.1; // 定义小数类型
int c = 2; // 定义整数类型
double d = 2.1; // 定义小数类型
}
String类型
使用字符串类型跟 JS 差不多,对于字符串中插入变量可以使用 + 符号,也可以使用 $ 符号来输出,区别就在于,Dart 中对于变量的调用可以省略{},当然对于表达式还是需要的。
void initString() {
String a = 'haha';
num b = 'bibi';
print('hehehe, $a${b+1}'); // hehehe, haha2
}另外,字符串类型还支持一些常用的API的。
- substring;
- indexOf;
- startsWith;
- replaceAll;
- split;
bool类型
布尔类型就更好理解,还会额外支持且运算符||以及或运算符&&。
void initBool() {
bool success = true;
bool fail = false;
print(success && fail); // false
print(success || fail); // true
}
List类型
List 集合就相当于 JS 中的 Array。若不对集合中类型进行指定,那么默认里面存储的元素都是 dynamic 类型。一旦指定范型,就只能添加约束的类型数据。
void initList() {
List list1 = [1, 2, 'hahaha']; // 范型为dynamic
List<int> list2 = [1, 2, 3]; // 范型为int
}日常使用 List 支持使用 add 方法添加一个元素,以及使用 addAll 添加一个集合。
若果需要遍历 List,可以使用的方式有:
- for循环;
- for...in...遍历;
- forEach方法;
Map类型
Map 类型类似于 JS 中对象,在不指定类型情况下默认都是 Map 类型。
void initMap() {
Map map1 = {
0: 'jeje',
'haha': 1
}; // 直接通过key:value形式定义即可
Map<int, int> map2 = {
0: 1,
1: 2
}; // 指定Map的范型
}获取 Map 中类型值时,就按照对象获取即可。如上述中获取 key 为 haha 的值:map1['haha']。
若果需要遍历Map,则可以是以下方式:
- forEach方法;
- for...in...遍历;
Set类型
Set 类型跟 Map 类型很类似,特别是在字面量语法上,所以上述也提到定义对象时,在不指定类型情况下默认都是 Map 类型。
Set 和 List 最大的两个不同分别是:
- Set 是无序的,List 是有序的。
- Set 中元素是不重复的,List 中元素是可重复的。
那么要使用 Set 类型时就需要指定相关类型。
void initSet() {
Set<String> names = {"1", 'haha'};
var age<int> = {12, 2, 3}
}
dynamic类型、var类型以及Object类型
dynamic类型指的就是动态数据类型,使用它就表示定义的变量会关闭类型检查,例如有如下代码:
以上代码在 AOT 中是不会被检查出错误的,但在运行时却会报错。因此,在绝大多数情况下是不会使用到该类型的。
var类型会自动推断类型,而且一旦指定了类型就不可以再进行修改。
Obeject类型就是所有Dart对象的基类,使用它就可以直接调用toString方法以及hashCode方法。再看如下代码:
以上代码在 AOT 中就会直接报错,因为找不到 haha 这个方法。
明显滴,dynamic 类型和 Object 类型的区别就在于编译时是否对静态类型进行检查。当然,var则是自动推断类型。
类
总所周知,Dart 是一门面向对象的开发语言,其中类在面向对象中占据的绝对中心的地位,接下来我们就来看看在 Dart 中编写类是如何实现的。
类的定义
在 Dart 中l类编写的格式如何:
class 类名 {
类型 成员名;
返回值类型 方法名(参数列表) {
// 函数处理
};
}需要注意的是,在使用 Dart 开发时,在方法中使用成员变量时都是会默认省略 this 的,但是遇到命名冲突时则需要补上 this。举个例子:
class Person {
num age;
void getAge() {
num resultAge = age + 1;
print('age = $resultAge');
}
}
void main() {
var person = Person();
person.age = 18;
person.getAge();
}在上面的代码中,可以看到,我把 new 关键字直接删掉了。这点也需要注意的,从 Dart 2.0 开始,new 关键字是可以省略。
构造函数的编写
在 Dart 中编写的构造函数和 JS 中编写会很不一样,我们都知道在 JS 中,会习惯使用 constructor 关键字来作为一个类的构造函数。
那么在 Dart 中,需要注意以下几点:
- 编写类时,如果不编写构造函数,Dart 会默认分配一个无参数的构造方法。
- 当编写自定义构造方法后,原来分配的无参数构造方法将会失效。
我们先来看看,在 Dart 中是如何编写一个构造方法的:
class Person {
num age;
Person(num age) {
this.age = age;
}
}当然,Dart 提供了一种更便捷编写构造方法的语法糖:
class Person {
num age;
Person(this.age);
}上述的编写和第一种编写的是等价的。
命名构造方法
在实际开发当中,我们会常常遇到一种情况,就是一个类只适应某个格式的参数,而无法适配其他格式的参数,这样一来,就不得不每次都需要将参数转化成统一格式来传递。
很明显,上述方式其实就是 java 中常用到的函数重载,而 Dart 中是不支持函数的重载,当然 JS 中也是不支持函数的重载,举个例子:
// JS
function overload(a) {
console.log(a)
}
function overload(a, b) {
console.log(a, b)
}
// 好明显,后面的重名函数会覆盖掉前面的函数。为了解决这一缺陷,Dart 通过命名构造方法来实现模拟实现函数的重载。
class Person {
num age;
Person(this.age);
Person.fromMap(Map<String, Object> map) {
this.age = map['age'];
}
}
void main() {
var person1 = Person(18);
var person2 = Person({ 'age': 19 });
}
初始化列表
初始化列表是为了解决类中定义的 final 变量动态初始化的。
如何理解?我们先来看看如下栗子🌰:
class Person {
final String gender;
Person(String gender) {
this.gender = gender;
}
}咋一看,感觉没啥问题,但是当你编写完后,肯定会通过不了编译,必须报错!这就是定义的 gender 属性是不可重新赋值的。我们先来简单分析一下。
相信你们还记得 JS 中 new 过程吧?其实这里也是一样道理,当 Dart 执行构造方法时,Person 对象其实已经初始化完毕了,那么再执行this.gender = gender时肯定报错。接下来我们就需要保证this.gender在 Person 初始化之前必须进行相应赋值。
我们可以很方便滴使用语法糖来解决。
class Person {
final String gender;
Person(this.gender);
}这时候问题又来了,如果类中存在一个成员变量的值是表达式动态赋值时如何处理?
好明显,如果使用上面语法糖方式肯定是只能写死的,并不能处理问题。而初始化列表就是为了才诞生出来的,看个🌰你就会明白啦:
class Person {
final String name;
final String gender;
final String description;
Person(String name, String gender) :
this.name = name,
this.gender = gender,
this.description = '$name is a $gender';
void handlePrint() {
print(description);
}
}
void main() {
var person = Person('Tom', 'boy');
person.handlePrint();
}初始化列表的语法很简单,就是在构造方法后面加上:,然后就是将 final 值进行赋值,多个赋值之间是需要逗号相隔的。
重定向构造方法
回到上面的函数重载问题,我们先看以下🌰:
class Person {
String name;
num age;
Person(this.name, this.age);
}明显滴,上述 Person 类在初始化时只能传入两个参数,若有时候想传入一个参数时,如何处理?
当然你可以使用命名构造函数,但也有一种情况就是使用重定向构造函数。
class Person {
String name;
num age;
Person(this.name, this.age);
Person.handleMsg(String name) : this(name, 18);
}
void main() {
var person = Person.handleMsg('Tom');
print(person.age);
}
常量构造函数
常量构造函数的作用就在于,相同参数创建的两个对象是同一个。
要判断两个对象是否相等,使用的是identical方法。
class Person {
final String name;
final int age;
const Person(this.name, this.age);
}
void main() {
var person1 = const Person('Tom', 18);
var person2 = const Person('Tom', 18);
print(identical(person1, person2));
var person3 = Person('Andraw', 19);
var person4 = Person('Andraw', 19);
print(identical(person3, person4));
}要使用常量构造函数,必须要注意以下几点。
- 创建常量对象时,必须使用
const关键字,否则是两个不同的对象。
- 常量构造函数中,成员变量必须是
final类型的,而且构造方法也必须使用const关键字来修饰。
- (额外)当常量变量的结果赋值给一个
const修饰的变量时,那么const是可以省略不写的。
工厂构造方法
回到上面相同参数希望得到相同的两个对象问题,除了上面使用常量构造函数方法外,还可以使用factory工厂构造函数来实现。
对于普通的构造函数,在创建时会默认返回一个对象,无需我们手动调用return,而对于工厂构造方法,则需要我们手动调用return返回一个对象。
其中,工厂构造函数使用的核心其实就是 JS 中的闭包原理。
我们来看个栗子🌰:
class Person {
String name;
static final Map<String, Object> _cache = <String, Person>{}; // 用于缓存创建好的对象
factory Person.formName(String name) {
if (_cache.containsKey(name)) {
return _cache[name];
} else {
final p = Person(name);
_cache[name] = p;
return p;
}
}
Person(this.name);
}
void main() {
var person1 = Person.formName('Tom');
var person2 = Person.formName('Tom');
print(identical(person1, person2)); // true
}
成员变量的setter和getter
类中成员变量默认会带有 setter 和 getter,当然我们也可以自定义它们俩。
class Person {
String name;
void set setName(String value) {
this.name = value;
}
String get getName() {
return this.name
}
Person(this.name);
}另外,在 Dart 中编写函数时,可以使用箭头函数语法糖进行简写。如下:
class Person {
String name;
void set setName(String name) => this.name = name;
String get getName => this.name;
Person(this.name);
}
类的继承
在 Dart 中类的继承使用extends关键字,而且子类中使用super来访问父类。
类的继承会拥有以下主要特点:
- 父类中除了构造函数外,其他所有的成员变量和方法均可被继承。
- 子类可对父类的方法进行重写。
- 在子类中可以使用初始化列表来调用父类的构造方法,以此来初始化相应的属性。
- 父类中不编写构造函数时,那么子类在初始化时将隐含调用父类的无参数默认构造方法(即无需我们手动调用)。
- 若父类中已经编写构造函数,那么子类必须在初始化列表中通过
super关键字显式调用父类的构造方法。
class Person {
String name;
Person(this.name);
void printName() {
print(`The person is $name`);
}
}
class Man extends Person {
int age;
Man(String name, int age) :
this.age = age,
super(name);
@override
void printName() {
super.print(); // 这里可以选择性调用父类的print方法
print(`The man is $name, and his age is $age.`);
}
}可以看到,若对父类的方法进行重写时,用到的是@override关键字。
抽象类
抽象类使用的是abstract关键字。
在抽象类中,既可以有没有具体实现的方法(简称抽象方法),也有具体实现的方法。
另外,抽象类是禁止被实例化的,其中抽象方法必须要被子类进行实现,而抽象类中具体实现的方法可以不被子类重写。
abstract class Person {
String name;
Person(this.name);
void getName() => this.name;
void getDescription();
}
class Man extends Person {
@override
void getDescription() => print('The man\'s name is $name');
Man(String name) : super(name);
}
静态成员变量和静态方法
类中的静态变量以及静态方法使用的是static关键字。
并且,静态成员变量以及静态方法只能通过原始类来调用,而且无法通过this进行调用。
class Person {
String firstName = 'hehe';
// 无法通过this访问静态属性
static String lastName = 'haha';
void printFirstName() {
print('The firstName is $firstName.');
}
static void printLastName() {
print('The lastName is $lastName.');
}
}
void main() {
var person = Person();
person.firstName = 'hihi';
person.printFirstName();
Person.lastName = 'BaBa';
Person.printLastName();
}
隐式接口
在 Dart 中只支持单继承,而不支持多继承,只能通过implements方式实现多继承。
默认情况下,每个类在定义时就相当于也默认定义了一个接口。
当将一个类作为接口使用时,那么实现该接口的类必须实现该接口中所有的方法,而且在实现所有的方法中都不能调用super方法。
class Person {
void getName();
void printName() {
print('Person.');
}
}
abstract class People {
void run();
}
class Man implements Person, People {
@override
void getName() => print('hahaha...');
@override
void printName() => print('hehe...');
@override
void run() => print('running...');
}
Mixin混合
既然implements用于实现某个接口中所有的方法,那么有没有一种方案是可以直接复用某个类中方法呢?
而**Mixin就是为了实现某个类复用另外一个类中方法才诞生的**。使用的是mixin 关键字创建类。
mixin Runner {
run() {
print('running...');
}
}
mixin Flyer {
fly() {
print('flying...');
}
}
class Bird with Runner, Flyer {};
void main() {
var bird = Bird();
bird.run();
bird.fly();
}显而易见的是,Mixin需要使用with来链接。
枚举类型
枚举类型在 Dart 中常用于表示固定数量的常量值。
其中,枚举类型使用 enum 关键字来定义:
enum Colors { red, orange, blue };
void main() {
print(Colors.red);
}另外,在枚举类型中有两种常见的属性,分别是index和values。
enum Colors { red, orange, blue };
void main() {
print(Colors.red.index); // 0
print(Colors.values); // [Colors.red, Colors.orange, Colors.blue]
}泛型
如果你使用 TS,那么对泛型肯定不陌生。那泛型是什么?简单来讲,泛型就是静态或动态用于指定某一种类型。
使用上很简单,看个🌰:
// 静态指定List为字符串类型
List list1<String> = ['haha', 'hehe'];
// 动态指定某个类中成员变量类型
class Person<T> {
T age;
Person(this.age);
}
var person1 = Person<String>('18');
var person2 = Person<int>(18);那么,使用泛型的作用有哪些?
- 正确指定泛型可以提高代码质量。
- 使用泛型可以减少重复冗余的代码。
第一点好理解,但是第二点如何理解?
举个例子,在项目我们创建一个用于缓存对象的接口:
abstract class ObjectCache {
Object getByKey(String key);
void setByKey(String key, Object value);
}然后突然有一天,发现还需要定义一个用于缓存字符串的接口,接着你又会这样去写:
abstract class StringCache {
String getByKey(String key);
void setByKey(String key, String value);
}而泛型就是能够通过动态指定类型来复用代码,如下:
abstract class ValueCache<T> {
T getByKey(String key);
void setByKey(String key, T value);
}接下来,我们就来看看在哪些地方可以用上泛型。
List和Map中泛型使用
类型的检查可以使用 runtimeType 属性来读出。
在 List 中可以直接限制存储数据类型。
List list1<String> = ['haha', 'hehe'];
List list2 = [123, 'hihi'];
List list3 = <String>['hehe', 'hihi'];
print(list1.runtimeType); // List<String>
print(list2.runtimeType); // List<Object>
同样地,在 Map 中使用泛型其实是一个样子的。
Map<String, String> map1 = {'haha': 'hehe'};
Map map2 = <String, String>{'hehe': 'hihi'};
类中泛型的使用
接着看上面那个缓存栗子🌰,我们一开始可能只会存储对象类型,但是为了以后更好拓展,我们需要根据输入的类型来动态存储相应的类型。
为了能够动态根据输入类型来存储相应的数据类型,有两种实现方案:
-
直接使用Object类型。。
abstract class ValueCache {
Object getByKey(String key);
void setByKey(String key, Object value);
}
class Cache extends ValueCache {
Map value = <String, Object>{};
Object getByKey(String key) => value[key];
void setByKey(String key, Object value) => this.value[key] = value;
}
void main() {
Cache temp = Cache();
temp.setByKey('test', 123);
print(temp.getByKey('test').runtimeType); // int
}
-
使用泛型。
abstract class ValueCache<T> {
T getByKey(String key);
void setByKey(String key, T value);
}
class Cache extends ValueCache<num> {
Map value = <String, num>{};
num getByKey(String key) => value[key];
setByKey(String key, num value) => this.value[key] = value;
}
main() {
Cache cache = Cache();
cache.setByKey('haha', 123.3);
print(cache.getByKey('haha').runtimeType); // double
}
在使用泛型过程中,如果希望存储的类只能是 num 类型呢?如何处理?其实也有两种方式:
- 直接写死 num 类型,缺陷就是每次都要写类型,一旦更改全部都要手动更改。
- 继承 num 类型(这种写法更妥),即使改动也只需要改动一个地方即可。
// 直接写死num类型
abstract class ValueCache<num> {
num getByKey(String key);
void setByKey(String key, num value);
}
// 继承num类型
abstract class ValueCache<T extends num> {
T getByKey(String key);
void setByKey(String key, T value);
}
方法参数中泛型的使用
泛型除了应用在类中,还可以应用在方法参数中,格式大体一致。如下:
T getList<T>(List<T> list) {
return list[0];
}
Map<K, T> getMap<K, T>(K key, T value) {
return <K, T>{ key, value };
}
main() {
List list = ['haha', 'hehe'];
print(getList(list).runtimeType); // String
print(getMap(123, 'hehe')); // { 123: 'hehe' }
}
库的导入以及导出
在 Dart 2.0 中,库的导入以及导出常用的方式是import/export。
当然,也可以使用part关键字将一个Dart文件进行拆分,但是官方已经不再建议使用,都是建议import/export方式。举个🌰:
// math.dart
num sum(num num1, num num2) => num1 + num2;
// util.dart
library util;
export './math.dart';
// main.dart
import 'lib/util.dart';
main() {
print(sum(1, 1.1));
}另外,Dart 还支持懒加载库文件,在需要时候再进行加载。好处如下:
- 减少 APP 启动时间。
- 执行 A/B 测试,测试不同的实现。
其中,懒加载需结合async/await来实现。
import 'package:greetings/hello.dart' deferred as hello;
// 在需要用到hello这个方法地方
Future greet() async {
await hello.loadLibrary();
hello.printCreeting();
}可以看到,要懒加载一个库,必须遵守以下规则:
- 先使用
deferred as来导入。
- 在需要用到的地方,调用
loadLibrary函数来加载库。
- 必须结合
async/await 使用,而且调用库中方法时必须要在await之后。
异步模型
在 Dart 中,实现异步操作主要是使用Future以及async/await,其中Future完全可以理解成 JS 中的Promise。
另外,Dart 和 JS 一样,都是单线程的。
要理解Future,你就得脑补一下 JS 的Event Loop。
深入了解Future
Future 在执行的过程中,可划分为两种状态,分别为
- 未完成状态(uncompleted):表示 Future 正在执行内部操作时。
- 完成状态(completed):表示 Future 内部操作已完成,会返回一个值或抛出异常。
我们先来看个 Dart 中同步阻塞的🌰:
import 'dart:io';
String getData() {
sleep(Duration(seconds: 3));
return 'hahaha';
}
main() {
print(1);
print(getData());
print(2);
}上述代码执行后,会先输出1,然后隔三秒后再接着输出'hahaha'和2。
明显,同步阻塞会影响到用户的体验,那么我们可以使用 Future 来优化。
import 'dart:io';
Future<String> getData() {
return Future<String>(() {
sleep(Decoration(seconds: 3));
return 'hahaha';
})
}
main() {
print(1);
final getDataFuture = getData();
getDataFuture.then((value) {
print(value);
})
print(2);
}使用 Future 来包装异步模块后,上述的代码执行会先输出1和2,等到3秒后再输出'hahaha'。
对于 Future 中抛出异常时,使用的是 catchError(与 Promise一样)。
main() {
print(1);
final getDataFuture = getData();
getDataFuture.then((value) {
print(value);
}).catchError((err) {
print(err);
})
}当然,Future 能像 Promise 一样进行链式调用。
Future 还有如下 API:
async/await
脑补一下 ES7 中的async/await,可以很容易发现其实是一个意思,可能在写法位置上可能会稍微的不一样,其他都是一样的。我们直接来看个🌰:
Future<String> getData() async{
final result = await Future.delayed(Duration(seconds: 3), () {
return 'haha';
});
return 'This is $result.';
}
main() async{
final str = await getData();
print(str);
}
// 3秒后输出haha可以看到,写法上大体一致,就是 async 在 JS 中习惯写在函数名的前面,而在 Dart 中需要写到{}函数体前面。
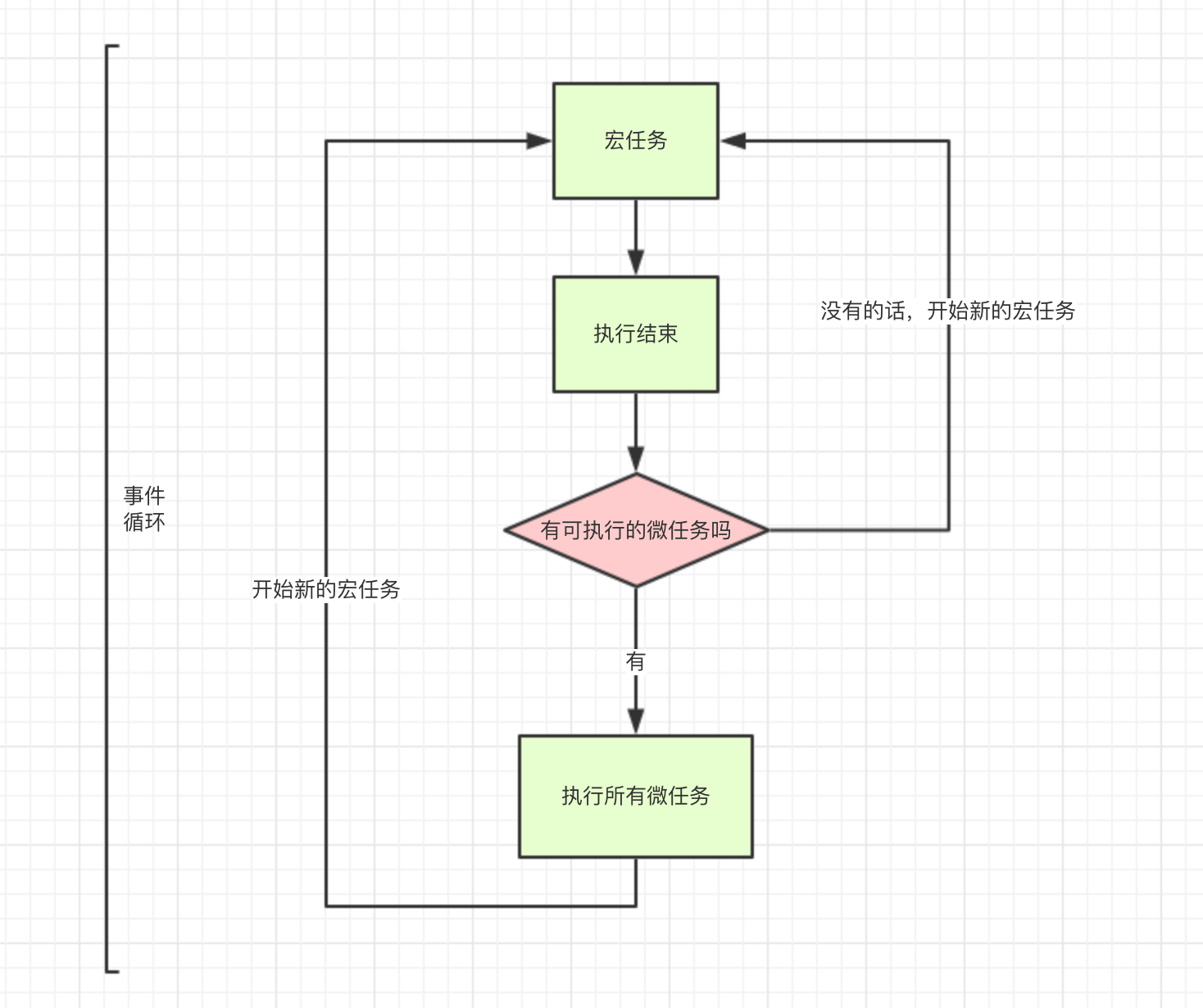
Event Loop
说起 Dart 的事件循环,想必你肯定会提到 JS 中Event Loop。不可否认,Dart 和 JS 中的Event Loop都是为了解决单线程中异步模型的方案。
事件队列和微任务队列
Dart 中可以将所有事件区分为事件队列和微任务队列。所有事件就包括有IO、点击、绘制以及计时器等。
其中,微任务队列中事件执行优先级要高于事件队列中事件。
那么,在 Dart 中是如何执行Event Loop的?
- Dart 的代码经过编译后,会先执行 main 中函数。
- main 函数执行完,一个事件循环
Event Loop就会正式启动,然后开始执行队列中的任务。
- 先观察微任务队列中是否为空,若不是则会按照先进先出顺序执行微任务队列中的任务。
- 执行完微任务队列中所有任务后,接着观察事件队列中任务,同样按照先进先出的顺序执行事件队列中任务。
Dart 中可通过 async 下的scheduleMicrotask方法创建一个微任务:
import 'dart:async';
main() {
scheduleMicrotask(() {
print('haha');
});
}问题来了,事件队列和微任务队列队列中存的任务都会有哪些?
- 微任务队列:main中主体代码、
scheduleMicrotask中回调函数、Future的then回调函数。
- 事件队列:Future回调函数。
看个🌰:
main() {
final future1 = Future(() {
print(1);
scheduleMicrotask(() => print(7));
return 2;
});
final future2 = Future(() {
print(3);
return 4;
});
future2.then((value) => print(value));
future1.then((value) => print(value));
scheduleMicrotask(() => print(5));
print(6);
}
// 输出的顺序依次为:6--5--1--2--7--3--4我们来分析一下:
- main中主体代码因为会放进微任务队列中,因此优先执行,输出6。
- 由于main主体代码执行了
scheduleMicrotask,也放进了微任务队列,输出5。
- 微任务队列已清空,再看看事件队列,由于future1先注册了,因此先执行,输出1。
- 上面提及过,
then会被注册到微任务队列中,与此同时,future1函数体内有又调用了scheduleMicrotask,因此scheduleMicrotask 中回调函数会注册到微任务队列中,排在future1的then的后面,所以future1中函数体执行完后,将优先权给回微任务队列,先输出2,然后输出7。
- 微任务队列已清空,future2注册进事件队列,因此会输出3,最后微任务队列中有future2的then,因此输出4。