Comments (10)
 wxp16
commented on May 21, 2024
3
wxp16
commented on May 21, 2024
3
The trained model is uncased, so the returned value of do_lower_case in create_tokenizer_from_hub_module() is True
But in class FullTokenizer, when spm_model_file is not None, the current code ignore the the value of do_lower_case. To fix this, first, in the constructor function of FullTokenizer, add one line self.do_lower_case = do_lower_case, then in def tokenize(self, text) , lowercase the text when you are using sentence piece model ` i.e.
if self.sp_model:
if self.do_lower_case:
text = text.lower()
Hope this works.
from albert.
 s4sarath
commented on May 21, 2024
2
s4sarath
commented on May 21, 2024
2
Download the model from tensorflow hub. The downloaded models will have an assets folder. Inside that .vocab and .model is present. .model represents spm model.
With no SPM Model
vocab_file = '/albert_base/assets/30k-clean.vocab'
spm_model_file = None
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True,
spm_model_file=spm_model_file)
text_a = "Hello how are you"
tokens_a = tokenizer.tokenize(text_a)
Output
['hello', 'how', 'are', 'you']
With SPM Model
vocab_file = '/albert_base/assets/30k-clean.vocab'
spm_model_file ='/albert_base/assets/30k-clean.model'
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True,
spm_model_file=spm_model_file)
text_a = "Hello how are you"
tokens_a = tokenizer.tokenize(text_a)
Output
['▁', 'H', 'ello', '▁how', '▁are', '▁you']
from albert.
 np-2019
commented on May 21, 2024
np-2019
commented on May 21, 2024
I had a similar issue,
workaround was to use the convert_examples_to_features from XLNet's run_squad.py and prepare_utils and make necessary changes. This helped me bypass it.
from albert.
 Rachnas
commented on May 21, 2024
Rachnas
commented on May 21, 2024
Thanks @s4sarath and @np-2019, I am able to process data with 30k-clean.model. I also incorporated convert_examples_to_features from XLNet with other changes. I am not bypassing SP model.
from albert.
s4sarath
commented on May 21, 2024
@np-2019 - It is better not to use XLNET preprocessing. Here things are bit different. The provided code runs without any error. If you are familiar with BERT preprocessing, it is very close except the usage of SentencePiece Model.
from albert.
Rachnas
commented on May 21, 2024
The trained model is uncased, so the returned value of
do_lower_caseincreate_tokenizer_from_hub_module()isTrueBut in
class FullTokenizer, whenspm_model_fileis not None, the current code ignore the the value ofdo_lower_case. To fix this, first, in the constructor function ofFullTokenizer, add one lineself.do_lower_case = do_lower_case, then indef tokenize(self, text), lowercase the text when you are using sentence piece model ` i.e.if self.sp_model: if self.do_lower_case: text = text.lower()Hope this works.
Thanks @wxp16 it helped.
from albert.
Rachnas
commented on May 21, 2024
Sharing my learning, using XLNet pre processing will not help. As sequence of tokens in XLnet and Albert differs. SQUAD2.0 will get pre processed but training will not converge. Better to make selective changes in Albert Code only.
from albert.
np-2019
commented on May 21, 2024
FYI, @Rachnas and @s4sarath , using Xlnet preprocessing I could achieve following results on squad-2.0
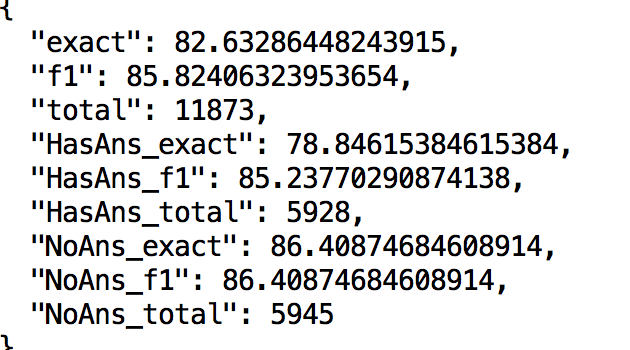
from albert.
s4sarath
commented on May 21, 2024
@np-2019 - Thats pretty good results. Which Albert model ( large, xlarge and version (v1 or v2) ) you have used?
from albert.
Rachnas
commented on May 21, 2024
@np-2019 , Its very nice that you are able to reproduce the results successfully.
according to XLnet paper: section 2.5: "We only reuse the memory that belongs to
the same context. Specifically, the input to our model is similar to BERT: [A, SEP, B, SEP, CLS],"
According to Albert paper: section 4.1: "We format our inputs as “[CLS] x1 [SEP] x2 [SEP]”,
As we can see, CLS token has different locations, will it not cause any problem if we format data according to XLNet ?
from albert.
Related Issues (20)
- torch.nn.modules.module.ModuleAttributeError: 'AlbertEmbeddings' object has no attribute 'bias' HOT 1
- The exact English pretraining data and Chinese pretraining data that are exact same to the BERT paper's pretraining data.
- albert base fine-tuned on squad2.0 gets stuck in loop when predicting on new file HOT 1
- Wrong pieces for control symbols after loading SentencepieceProcessor from official model HOT 2
- fine tune on my own English dataset
- Discrepancy in tokenization results using albert's tokenizer and sentencepiece library
- which word segmentation tool is used for pretraining Chinese ALBERT
- Probable error on line 306 in `create_pretraining_data.py` for albert
- Default Tutorial Not Working - Can't download MRPC data HOT 2
- Prediction Fails on default Colab HOT 2
- How to get the test embeddings from output of fine-tuned model (tutorial)
- when training in Race , The eval_accuracy is flat , it only has three numbers which are 0.0, 0.33334, 0.66667, 1.0
- Difference between v1 and v2 for xxlarge
- Wrong evaluate result on Squad2.0
- The results can't be reproduced HOT 2
- Improvement to how the `app` and `pages` files conflict is shown. Especially the last log line `"pages/" - "app/"` made it seem like you should remove the `pages` folder altogether. This was a bug in how the `''` case was displayed. After having a look at this I went further and added exactly which file caused the conflict given that `app` allows you to create `app/(home)/page.js` and such it saves some digging for what the actual conflicting file is. Similarly in `pages` both `pages/dashboard/index.js` and `pages/dashboard.js` are possible.
- Load in Browser Tensorflow
- Why do I find inconsistencies between the output of my ALBERT model converted to ONNX format and tested with ONNX Runtime, compared to the original PyTorch format model?
- Albet
- Albert
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from albert.