Comments (9)
 funilrys
commented on May 25, 2024
1
funilrys
commented on May 25, 2024
1
Thank you @ScriptTiger for ideas sharing.
Your ideas and suggestion are great and I should definitely think about integrating such operation into PyFunceble.
Just to be at the same level tell me if I need to add or modify my understanding of your main idea.
Your idea consists to create a database with domain and WHOIS data or hash of the whois data so we can gain some time by only comparing the current hash and the saved one.
Well, that can be possible and I really did not think about that!
P.S: I take the following representation as the main representation of the main processes which composes PyFunceble.
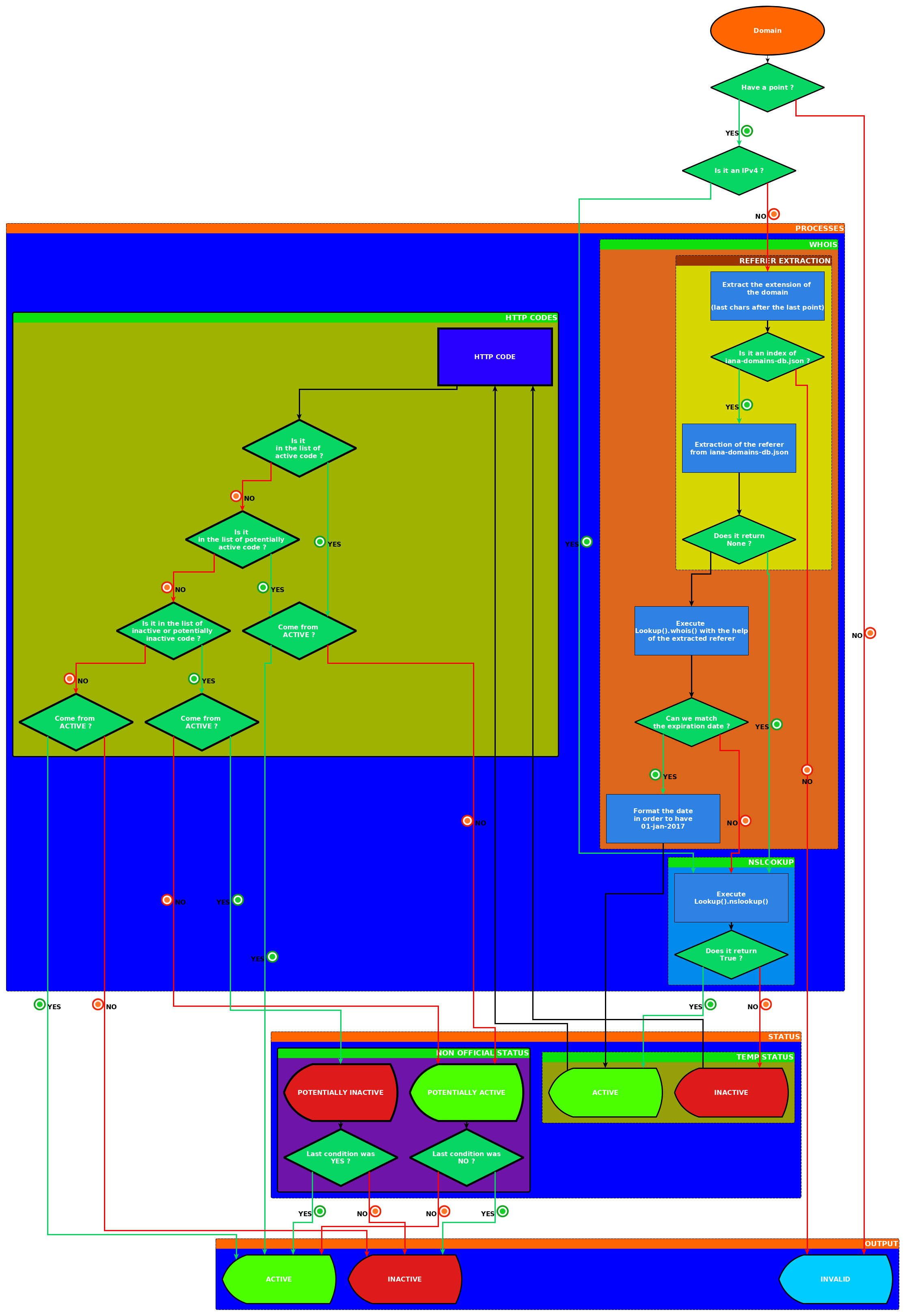
About the manual checking, long time ago @mitchellkrogza proposed me to create a GUI to help validate manually check domain by collecting information (screenshots, header, ...) but at the time I was starting to privately write PyFunceble so I internally staged the development of that feature for later (cf:funilrys/funceble#62).
Now that I'm done with integrating all Funceble's features into PyFunceble, I spend most of my free time working on open source project, fixing all issues of this repository (Thanks to Logs sharing) and add new features like the inactive-db.json which save all inactive domains and retest them later to reintroduce all newly active domain.
So I think it'll be good to first develop that GUI feature then focuses on the idea mentioned here @ScriptTiger.
Thanks again for that brilliant idea @ScriptTiger and feel free to add your other ideas here so I can take a look at them!
from pyfunceble.
 ScriptTiger
commented on May 25, 2024
ScriptTiger
commented on May 25, 2024
Yeah, I'll definitely look forward to the GUI, I didn't know you were working on that. Maybe you could look into Electron, its front end is Google Chrome and its back end is Node,js, so it should make scraping snapshots, headers, and other HTTP/HTTPS information a breeze if you're familiar with it. But if you're not, I don't want you to try to put too much on your plate at once for now :P
from pyfunceble.
funilrys
commented on May 25, 2024
So let's continue this awesome thread!
I changed my roadplan because I was not satisfied with the state of the code base (which is quiet better yet in the development version).
Indeed as I was starting developing the GUI - back in February - I found myself in bad situation because PyFunceble was not suited for usage as an exported module. Now PyFunceble - at least the development version - is quiet stable and usable as both CLI application or Python module which make things good for developing other tool or script with the help of PyFunceble functions, methods, classes or test result. It took me some time but I'm quiet satisfied and impressed by myself regarding that point...
I tested this week my implementation of this issue on my server and I ended with an issue:
After x requests to the WHOIS server - in the case that we are testing a list - the WHOIS record change because of the message which tell us that we reached our rate per hours or day or we are simply banned from their server...
Therefor, I'm thinking about implementing a JSON file which will serve as the database. But instead of comparing hash, I'm comparing the expiration date.
Indeed, for now we are requesting the WHOIS record every time a domain is tested even if it was tested in previous sessions because I never felt - or had the idea - that checking the expiration date may be useful.
Here's an draft of a "database" that is working on my side as the code is not pushed yet.
{
".travis/list_to_test": {
"azvjudwr.info": {
"epoch": "1569016800",
"expiration_date": "21-sep-2019",
"state": "future"
},
"cdnfile.xyz": {
"epoch": "1544828400",
"expiration_date": "15-dec-2018",
"state": "future"
},
"google.com": {
"epoch": "1600034400",
"expiration_date": "14-sep-2020",
"state": "future"
},
"jroqvbvw.info": {
"epoch": "1569016800",
"expiration_date": "21-sep-2019",
"state": "future"
},
"jyhfuqoh.info": {
"epoch": "1569016800",
"expiration_date": "21-sep-2019",
"state": "future"
},
"kdowqlpt.info": {
"epoch": "1569448800",
"expiration_date": "26-sep-2019",
"state": "future"
},
"metrika.ron.si": {
"epoch": "1684447200",
"expiration_date": "19-may-2023",
"state": "future"
},
"static.hk.rs": {
"epoch": "1542322800",
"expiration_date": "16-nov-2018",
"state": "future"
},
"xbasfbno.info": {
"epoch": "1569016800",
"expiration_date": "21-sep-2019",
"state": "future"
}
}
}
What I did with those data is comparing the epoch with the current epoch.
If the current epoch is greater that the one from the WHOIS record, I update the state to past and the system try to get the new expiration date or continue the logic.
Otherwise, I return the expiration date and we return the UP status directly as the domain is not expired - yet.
What's your input on this @ScriptTiger ? Do you see a better "pattern" or way to handle the problem ?
Have a nice day/night.
Cheers,
Nissar
from pyfunceble.
ScriptTiger
commented on May 25, 2024
I'll start with an apology. I posted this issue on February 4, 2018, but on 25 May 2018 the GDPR came out and WHOIS data is now in a transitional period to comply with the GDPR. Current WHOIS data contains phones numbers, addresses, e-mails, etc., which are very much affected by the GDPR and it's hard to tell how the WHOIS data might change over the coming year or so.
So before continuing, please keep that in mind. I'd suggest either waiting a year or so before continuing development with this or just keep in mind that the data itself as well as possibly restrictions on how the data is accessed are apt to change a lot and perhaps just develop a framework in the meantime that can easily adapt to a different data set later.
Another thing to note, which I am sure you are already aware of, may be that subdomains of registered domains do not have WHOIS data, as those subdomains are privately managed internally by the individual or organization to whom the parent domain is registered. I know you are probably aware of this, but I just mention it because I am not sure if these are accounted for in your diagram. WHOIS data should be used if it's available, but if it's not available it can continue to be validated by other means. The only requirement should be that the parent domains are registered, but subdomains should not be required to validate using WHOIS.
After x requests to the WHOIS server - in the case that we are testing a list - the WHOIS record change because of the message which tell us that we reached our rate per hours or day or we are simply banned from their server...
The rate limits and other limitations depend on the specific WHOIS server you're accessing. There has been a big problem with bots collecting WHOIS data in order to use the contact information for spam and scam schemes. Other access limitations, like CAPTCHA for Web-based queries, OAuth tokens for API access, etc., may also be implemented. These security measures may continue to change a lot in the next year or so while things work towards compliance with the GDPR
I think using the expiration is actually a brilliant idea to cut down on the number of queries each time the script runs. It could work similar to how DHCP leases work, where it issues an IP with an expiration and the client comes back when the IP expires to renegotiate a new IP. In our case, the script might only check entries that are currently past their expiration. Entries can obviously also be updated before they expire, but I think it's a fair balance in our case. If a dead domain or domain that was previously a bad domain but is now a good domain has updated their WHOIS with their new contact before their expiration, it will only stay "active" on the list for a couple extra years, which is fine because it's better to be safe and keep blocking it a couple extra years.
I think the main program flow should have two major phases:
1.) The first-time run must generate the complete database. Every run after this will just be small, incremental updates to only expired domains. This phase must time-delay its queries, such as one query every 10 minutes or 10 queries every day, etc.
If this project gets more community support, perhaps a paid subscription to access an API to make unlimited queries in bulk could also be set up. However, such paid subscriptions using private third-parties that are not official WHOIS servers are not up to date in real time and we should compare everything, cost, update frequency, range of domains included in the database, etc. Also, if a third-party API is used, the private access token required by this script should obviously not be made public in the repository and should be ignored by git.
I'll also note here that most rate limits are IP-based. If we query small batches and change our IP between each batch, these rate limits can be circumvented, allowing us to generate the first database more quickly and for free.
2.) Every time the script runs after phase 1.) has completed, only a small number of expired domains will be queried and those individual entries will be updated. Because the output from phase 1.) will be made available in the repository, phase 2.) is what most people will be using when they run the script, to update the latest database they have pulled from the repository. Because the number of expired domains should be relatively small, as long as the database is kept up to date regularly, the rate limits should not be an issue here because the number of queries should not reach the limit.
I honestly don't have experience comparing domain expirations, maybe this project can also generate statistics, but most domains expire after more than a year, so the probability of a large number of domains all expiring the same exact time is slim, or so I would think right now. If my theory is incorrect, we can adjust later.
from pyfunceble.
funilrys
commented on May 25, 2024
No need to apology @ScriptTiger!
I do think that desperate GPDR the expiration date will stay. Indeed, in Germany, we had a similar law for German registered company/hosts before the GPDR even exist and the expiration date was still present when the personal information was hidden or non-existent in the WHOIS record.
I know you are probably aware of this, but I just mention it because I am not sure if these are accounted for in your diagram.
The system handles that automatically but I should indeed review the bypassing part for subdomains.
WHOIS data should be used if it's available, but if it's not available it can continue to be validated by other means.
I should update the diagram along with the next (pre-)release. But yes if we can't get an expiration date we continue to other methods.
The rate limits and other limitations depend on the specific WHOIS server you're accessing. There has been a big problem with bots collecting WHOIS data in order to use the contact information for spam and scam schemes. Other access limitations, like CAPTCHA for Web-based queries, OAuth tokens for API access, etc., may also be implemented. These security measures may continue to change a lot in the next year or so while things work towards compliance with the GDPR
It will indeed change in the coming year but I should document myself about such authentication method as I may need that in the future for a bigger project I'm working on privately.
In our case, the script might only check entries that are currently past their expiration. Entries can obviously also be updated before they expire, but I think it's a fair balance in our case.
I do think that retesting before they expire for example 1 day before the expiration date may be interesting and better to implement. Thanks for the idea.
If a dead domain or domain that was previously a bad domain but is now a good domain has updated their WHOIS with their new contact before their expiration, it will only stay "active" on the list for a couple extra years, which is fine because it's better to be safe and keep blocking it a couple extra years.
For that special case where a domain becomes active after an inactive phase, I did a bit further. Indeed it's in the development version but with #12, users will have a list of domains which were INACTIVE but became suddenly ACTIVE. Indeed, they are still listed as ACTIVE but we also add them into an analytic category called SUSPICIOUS.
1.) The first-time run must generate the complete database. Every run after this will just be small, incremental updates to only expired domains. This phase must time-delay its queries, such as one query every 10 minutes or 10 queries every day, etc.
I was indeed thinking about creating a global database based on a new endpoint in my logs sharing system or a whole new website but I think that it might have to wait some time in my workflow as it implies an investment which I'm not sure to have actually.
Therefore, I'm thinking about implementing a local database which is locally within a whois_db.json file. Its content will be dependent on the tested file is for a beginning a better way to avoid having to request the record everytime.
Later if I have the resource, time and the ingenuity to create a whole new system (maybe with a queue system ? 🤔 ), I will create a global database/API which first coupled with PyFunceble might help improve the results by reducing the constant local request to the WHOIS record.
2.) Every time the script runs after phase 1.) has completed, only a small number of expired domains will be queried and those individual entries will be updated. Because the output from phase 1.) will be made available in the repository, phase 2.) is what most people will be using when they run the script, to update the latest database they have pulled from the repository. Because the number of expired domains should be relatively small, as long as the database is kept up to date regularly, the rate limits should not be an issue here because the number of queries should not reach the limit.
I tested that last weekend and It was indeed significantly better as I was able to do some WHOIS requests after the retests while testing locally my feature with @Ultimate-Hosts-Blacklist data. Without that feature, I'm blocked or banned from the WHOIS server.
I honestly don't have experience comparing domain expirations, maybe this project can also generate statistics, but most domains expire after more than a year, so the probability of a large number of domains all expiring the same exact time is slim, or so I would think right now. If my theory is incorrect, we can adjust later.
Most renew appears to be done the week of the expiration date... Even in a bigger company so it might be funny to look at that!
As said previously may be a better strategy like comparing expiration date x days before the expiration date might be better ? Or even better retest randomly from 15 to 1 day before the expiration date!
I think that there is still a lot to do but I already accomplish the best and biggest part! Indeed, we are now a usable tool 😸 .... and really open source 😹
Indeed, when we started this thread PyFunceble was impossible to develop by people who do not understand Python nor do not understand the logic I used and why.
After taking some great time this summer refactoring the code base and introducing comments for every line of the code base, I'm happy to say that almost nobody can now follow the logic! Of course, that is for now in the development version 😸 but can't wait to finish my roadmap for the next release 😸
I hope to finish the implementation of the local database system for the coming weekend or at the beginning of next week.
P.S: The implementation of the VPN connection and testing is stashed because of some problem I had with the different requests but I hope to implement it one day!
from pyfunceble.
funilrys
commented on May 25, 2024
Closing as an implementation of a solution has been already implemented.
from pyfunceble.
funilrys
commented on May 25, 2024
Hi @ScriptTiger, sorry for taking your time. But I remember you were talking about VPN in the past.
From our perspective how does the usage of VPN differs from the usage of a DNS server?
I'm asking because I'm still thinking if it does make sense to implement a way to test across VPN when the system (PyFunceble-dev) allows a custom DNS server 🤔
Thanks for your time.
Cheers,
Nissar
from pyfunceble.
ScriptTiger
commented on May 25, 2024
DNS is basically just a database application that works on layer 7 and is completely independent of the IP addresses it stores and unaware of whether or not they are actually reachable or not. Anyone can pay to register a DNS entry, but that doesn't mean the IP address associated to that entry is live or not. Someone could have registered a malware site 5 years ago on a 10-year contract and the site got taken down 3 years ago. Dead domains are especially common with spam and malware domains because they can only be used so many times before people catch on and start blocking them, then they just move on to a new domain and leave the old one dead and harmless and no longer needing to be blocked but still taking up space on uncurated and unmaintained lists.
That being said, just because an IP address SEEMS unreachable, does not mean it actually is. For example, if you are testing whether or not an IP address is reachable by simply pinging it, this actually will only tell you whether or not the given IP address is accepting ICMP requests or not, but it could still have an HTTP(S) server completely alive and well regardless of whether it is accepting ICMP or not. For attacks targeting users in Russia, as another example, maybe IP addresses outside of Russia are blocked from reaching a particular server and that server may seem unreachable to someone trying to connect from a U.S. IP address but it is completely reachable to someone connecting from a Russian IP address. It is also common for attacks to target specific devices and as such detect specific user agent strings, meaning maybe a particular Web server is only reachable by devices declaring a Xiaomi user agent string but completely unreachable if you are trying to reach if from a Samsung mobile phone or Desktop PC. It's also common for completely legitimate Websites to block access to IP addresses known to be Tor relays, or relays for other overlay networks, or even known exit IP addresses of popular VPN services.
I had originally suggested using SoftEther VPN Gate because that project is completely open source and the VPN Gate servers are hosted all over the world by anyone willing to host them, similar to Tor nodes, but their IP addresses are not as well known and not as commonly blocked. However, this solution only addresses attackers targeting and/or blocking specific IP ranges, as using a VPN will obviously change your origin IP. As I said, there are other things attackers can target, as well, such as user agents declared within the layer-7 portion of the packet. In order to work around attacks such as this, you would also have to programmatically change your user agent, possibly just randomly for a random sample or trying multiple user agent strings on each server, however you dictate requirements.
There are endless ways attacks can target specific groups while staying hidden from others at the same time, and it is for this reason Steven Black relies solely on human collaboration and does not accept automation. If your project could address as many of these attack vectors as conceivably possible, I am sure Steven Black may take more consideration, but this would entirely depend upon the conceivable margin for error that Steven Black is willing to accept. When it comes to protecting people from malware and stopping the spread of some seriously damaging viruses costing people billions each year, not to mention the cost of having one's very identity or other private data stolen which can't be easily calculated in monetary value, the margin for error should obviously be held as minimal as possible.
from pyfunceble.
ScriptTiger
commented on May 25, 2024
And just as another quick note, obviously DNS can associate a domain name to multiple different IP addresses, depending on how that DNS server is designed to load balance across those IP addresses. In some instances the DNS server may calculate which IP address should yield the fastest connection, mostly based on geographical factors but not always, and respond with the IP address for a requested domain that way. Other DNS servers may simply do arbitrary round robin and not calculate anything and just respond that way. Because of this the complexity of my previous post is obviously multiplied with each possible IP address you will have to scan for, as some IP addresses associated with a particular domain may have been compromised by an attacker while others not.
from pyfunceble.
Related Issues (20)
- FEATURE: Preload/Continue like the CI workflow ... but without Git HOT 2
- BUG: Cant install latest version with pip HOT 2
- BUG: urls in domain lists.... HOT 2
- FEATURE: Special Rules for forumactif.com HOT 1
- Contribution Tracking
- DOC: Moving away from restructured text HOT 8
- BUG: URL in file header should be changed
- BUG: dead domain query HOT 9
- BUG: sqlalche braekes after finishing...
- FEATURE: Reputation filter using the proxy connection HOT 3
- FEATURE: Sharing WHOIS
- FEATURE: meilisearch or redis support vs RamDrive
- BUG: TypeError(f"<data> should be {dict}, {type(data)} given.") HOT 5
- BUG: log file not created... HOT 2
- Special Rules, are they working as expected? HOT 2
- Unstable special rules HOT 1
- BUG: Object of type datetime is not JSON serializable HOT 2
- FEATURE: Timestamp in CLI output
- BUG: domains can't start with a dot... HOT 2
- pyfunceble.funilrys.com
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from pyfunceble.