Comments (12)
 Diviyan-Kalainathan
commented on May 14, 2024
Diviyan-Kalainathan
commented on May 14, 2024
There seems to be big performance issues on GNN ; i'll look into it
Duplicate of #33
from causaldiscoverytoolbox.
 wpzdm
commented on May 14, 2024
wpzdm
commented on May 14, 2024
Hi,
It seems #33 is a different thing.
Here, I used default parameters in the package, that is:
def __init__(self, nh=20, lr=0.01, nruns=6, njobs=None, gpus=None,
verbose=None, ttest_threshold=0.01, batch_size=-1,
nb_max_runs=16, train_epochs=1000, test_epochs=1000,
dataloader_workers=0):
"""Init the model."""
In particular, epochs is 1000, not 10.
Actually, I also try the parameters provided in test_causality_pairwise.py, it was pretty fast but with low accuracy.
Thus I have the question in the title: balancing accuracy and running time.
Thanks,
Abel
from causaldiscoverytoolbox.
 ArnoVel
commented on May 14, 2024
ArnoVel
commented on May 14, 2024
Hi,
I fiddled with the GNN a fair bit, and it seemed to me that to have a point prediction (namely only one instance of GNN+MMD scores+fake samples) without any notion of statistical uncertainty (either be variance, confidence interval or p-value), it is enough to:
- set
train_epochs=1000,test_epochs=500(or 1000, depends) - have
nh=20ornh=30 - leave every other hyperparameter equal to default
- set
batch_size=n_pairor-1(you have to check that the batch is actually the full sample, I had some issues where, because I didn't use the right data format (dataframes) it was operating with n=2 for some reason). Heren_pairis the sample size for a given pair. In my case, I just have some function that makes sure the sample size is always below someN( I found N=1000 or 1500 to be sufficient)
Finally, and at least in the past CDT versions, I had to remove the statistical bit myself (related to the nruns variable; which is essentially computing P-values in a loop and training networks over and over).
Below is some graph I made (the template is from the RCC paper) using CDT and CGNN last summer, these performances are roughly what other authors have reported when testing CGNN on TCEP.
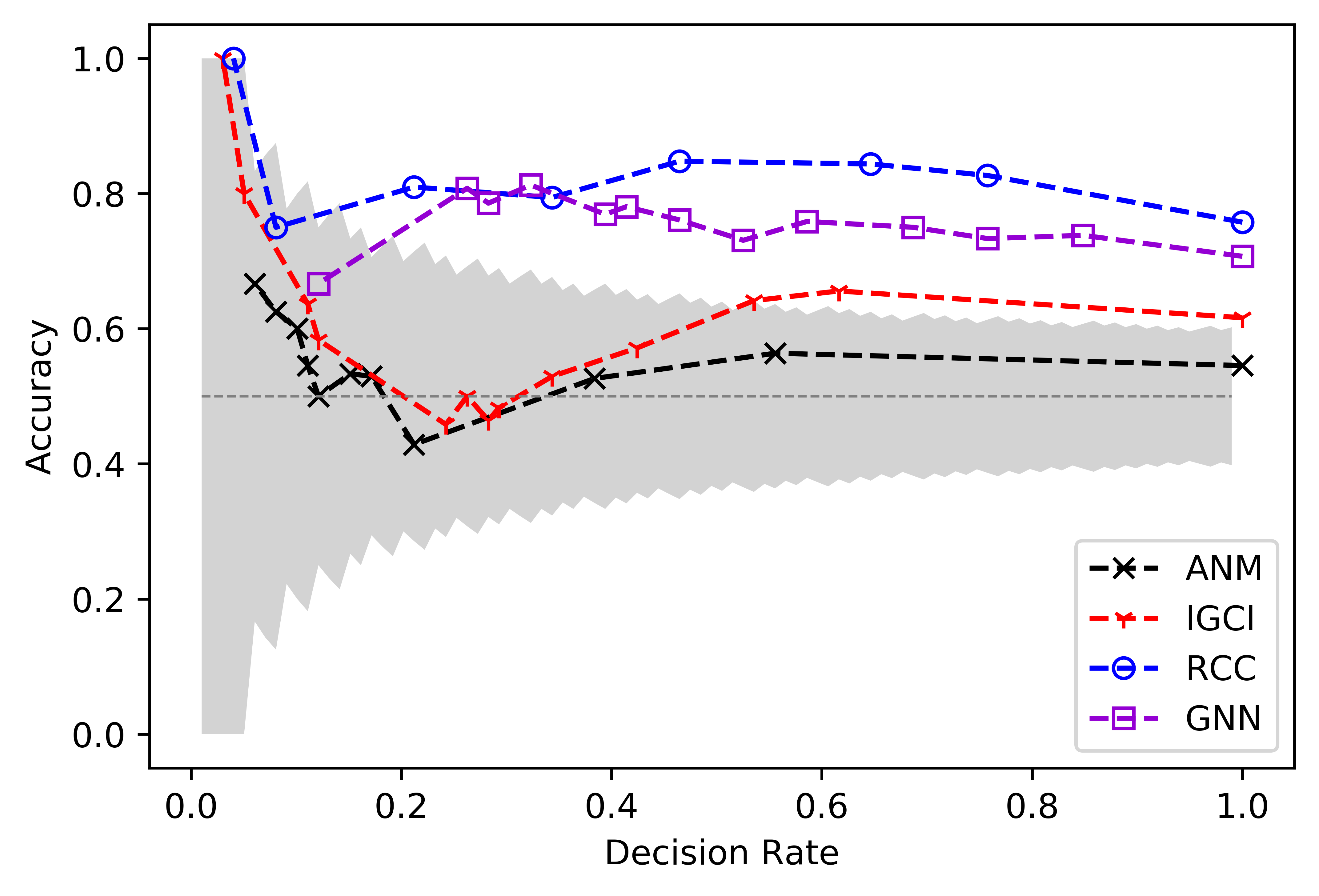
I hope I've helped you, however if you truly wish to compute P-values or Confidence Intervals you cannot escape the computational load and will need multiple GPUs!
Update: Did not give my setup; I use CUDA with a GeForce GTX 1060 6GB, and an i7 processor
from causaldiscoverytoolbox.
wpzdm
commented on May 14, 2024
Hi,
Thank you so much your help!
When trying to limit the repetitions, I got confused by the documentation:
This algorithm greatly benefits from bootstrapped runs (nruns >=12 recommended)
nruns (int): number of runs to execute per (before testing for significance with t-test).
nb_max_runs (int): Max number of bootstraps
It still runs many time for a single pair if I set nruns=1 but leave nb_max_runs as default.
Should I also set nb_max_runs?
from causaldiscoverytoolbox.
Diviyan-Kalainathan
commented on May 14, 2024
I will remove nb_max_runs and only keep nb_runs as parameters, I find it more confusing than helpful. The change is to be expected in next version !
from causaldiscoverytoolbox.
wpzdm
commented on May 14, 2024
@Diviyan-Kalainathan It runs several times even if I set both nruns=1 and nb_max_runs=1. A bug?
<class 'cdt.causality.pairwise.GNN.GNN'>
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 510/510 [00:13<00:00, 37.17it/s, idx=0, score=0.183]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 510/510 [00:14<00:00, 34.64it/s, idx=0, score=0.11]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 510/510 [00:12<00:00, 41.61it/s, idx=0, score=0.124]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 510/510 [00:16<00:00, 31.47it/s, idx=0, score=0.155]
pair1 P-value after 2 runs : 0.548389124615737
from causaldiscoverytoolbox.
Diviyan-Kalainathan
commented on May 14, 2024
Did you update your package ?
It should run at least 2 times: one for X -> Y and one for Y->X ;
I guess the pvalue computation needed at least 2 samples, so 4 in total.
Updating your package removes the t-test evaluation, thus should reduce your computation by 2 runs, if I didn't mess up somewhere,,
from causaldiscoverytoolbox.
ArnoVel
commented on May 14, 2024
Hi,
I have tried several runs of CGNN, with the new version, and I'm now running into the same problem as above.
The training is much faster than before (possibly 5 times faster on the same setup?) but now the accuracy never goes above 60%.
And I'm using 2000 epochs to train, and 3 runs in each direction. The predictions do change, although in a very subtle manner, but the number of miss-classified examples is very stable.
How to explain a sudden drop in accuracy? Would this be related to model initialization?
I'm using the exact same hyperparameters as before, simply a different CDT version...
recommendations are welcomed, as I have no idea what to tweak...
from causaldiscoverytoolbox.
Diviyan-Kalainathan
commented on May 14, 2024
Hello,
strange... maybe I missed something in the reimplementation. Could you give me the two version numbers ? (For me to compare).
For row, try to add 12runs, to have a better confidence level on the predictions. We actually noticed quite the performance bump from 1 run to 12 runs.
from causaldiscoverytoolbox.
Diviyan-Kalainathan
commented on May 14, 2024
@ArnoVel Were you able to run the GNN with 12 runs ? I wanted to ask you the various version numbers you used , for me to double check what changed.
from causaldiscoverytoolbox.
ArnoVel
commented on May 14, 2024
Hi,
I've been trying with 10 runs, adding more than 10 runs makes it too expensive. Strangely enough, the scores do not change much with more repetitions when using two layer nets.
So far for 1 run per pair, having two or one layers at given nh (I tried 10,20,30) does not change much the outcome on TCEP, and results in a score around 55% when all decisions are forced.
Whenever using 10 runs per pair, with one or two layers, one gets better scores, but still steadily decreases to 60% when inferring direction on all pairs.
from causaldiscoverytoolbox.
Diviyan-Kalainathan
commented on May 14, 2024
Hello,
Sorry for the huge delay, but I think that 6bb47fd resolved the issue. (To be released with the next version)
I'll be closing the issue; don't hesitate to re-open it.
from causaldiscoverytoolbox.
Related Issues (20)
- SID and SHD do not get the same results as the author of SID HOT 3
- SID error HOT 1
- Is it possible to insert prior knowledge before the causal graph creation? HOT 3
- [BUG] CGNN (Causal Graph Generation) + Usage of multiprocessing with pytorch HOT 1
- R Package (k)pcalg/RCIT is not available. RCIT has to be installed from https://github.com/Diviyan-Kalainathan/RCIT HOT 6
- [BUG] cdt.data.load_dataset('sachs') + one of the returned objects, 'target', is inconsistent with the paper(Sachs,etc 2005) HOT 1
- [fileNotFoundError: [Errno 2]] cdt.causality.graph.LiNGAM + No such file or directory: 'C:\\anaconda\\lib\\site-packages\\cdt\\utils\\R_templates\\test_import.R' HOT 1
- GIES targets and target.index parameter needs to be exposed HOT 2
- [BUG] orient_graph removes some of the edges
- [Question] What does the causal score in the pairwise model really indicate?
- ImportError: R Package (k)pcalg/RCIT is not available. HOT 3
- [BUG] CGNN run() Wrong way to calculate the score HOT 1
- FloatingPointError: The system is too ill-conditioned for this solver. The system is too ill-conditioned for this solver HOT 1
- Help! HOT 1
- Can PC algorithm be used for causal discovery under mixed types of data?
- ImportError: R Package pcalg is not available
- [BUG] autoset_settings() fails with MIG GPU
- CCDr algorithm execution error
- CCDr Algorithm + estimate.dag in R Script, Error in weights HOT 3
- CGNN running time is too long
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from causaldiscoverytoolbox.