
Elassandra is a fork of Elasticsearch modified to run on top of Apache Cassandra in a scalable and resilient peer-to-peer architecture. Elasticsearch code is embedded in Cassanda nodes providing advanced search features on Cassandra tables and Cassandra serve as an Elasticsearch data and configuration store.

Elassandra supports Cassandra vnodes and scale horizontally by adding more nodes. A demo video is available on youtube.
- 2016-05-10 Release 2.1.1-9 Upgrade to cassandra 2.2.5
- 2016-04-17 Release 2.1.1-8 New feature, index cassandra static columns
- 2016-03-18 Release 2.1.1-6 Add support for SQL plugin (from NLPchina) and JDBC driver (from Anchormen).
- 2016-02-16 Release 2.1.1-2 Remove build dependency to elasticsearch parent project.
- 2016-02-01 Release 2.1.1-1 Add support for parent-child relationship.
- 2016-01-28 Release 2.1.1 based on Elasticsearch 2.1.1 and cassandra 2.2.4.
- 2015-12-20 Release 0.5 Re-index you data from cassandra 2.2.4 with zero downtime.
- 2015-11-15 Release 0.4 New elassandra tarball ready-to-run.
Show short intro:

For cassandra users, elassandra provides elasicsearch features :
- Cassandra update are automatically indexed in Elasticsearch.
- Full-Text and spatial search on your cassandra data.
- Real-time aggregation (does not require Spark or Hadoop to group by)
- Provide search on multiple keyspace and tables in one query.
- Provide automatic schema creation and support nested document using User Defined Types.
- Provide a read/write JSON REST access to cassandra data (for indexed data)
- There are many elasticsearch plugins to import data in cassandra or to visualize your data, with Kibana for exemple.
For Elasticsearch users, elassandra provides usefull features :
- Change the mapping and re-index you data from cassandra with zero downtime, see Mapping change with zero downtime.
- Cassandra could be your unique datastore for indexed and non-indexed data, it's easier to manage and secure. Source documents are now stored in Cassandra, reducing disk space if you need a noSql database and elasticsearch.
- In elassandra, Elasticsearch is masterless and split-brain resistant because cluster state is now managed within a cassandra lightweight transactions.
- Write operations are not more restricted to one primary shards, but distributed on all cassandra nodes in a virtual datacenter. Number of shards does not limit your write throughput, just add some elassandra nodes to increase both read and write throughput.
- Elasticsearch indices can be replicated between many cassandra datacenters, allowing to write to the closest datacenter and search globally.
- The cassandra driver is Datacenter and Token aware.
- Hadoop Hive, Pig and Spark support with pushdown predicate.
- Cassandra supports partial update and distributed counters.
Kibana version 4.3 can run on Elassandra, providing a visualization tool for cassandra and elasticsearch data. Here is a demo video.
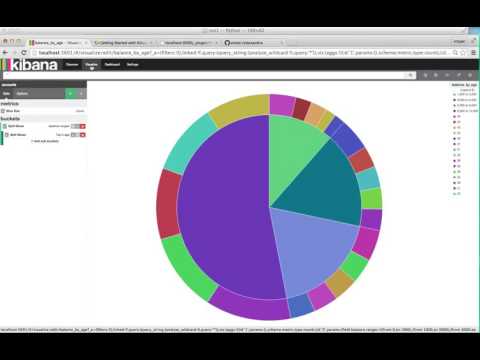
Because cassandra keyspace, type and table can only contain alphanumeric and underscore characters (see cassandra documentation), the same restriction applies to index and type names.
- Replace the index name .kibana by kibana in config/kibana.yaml.
- Replace 'index-pattern' by 'index_pattern' in the source code with the following sed command:
q=\'
# for Kibana 4.1.x
sed -i .bak -e "s/type: ${q}index-pattern${q}/type: ${q}index_pattern${q}/g" -e "s/type = ${q}index-pattern${q}/type = ${q}index_pattern${q}/g" index.js
# for Kibana 4.3.x (for Elassandra v2.1.1+)
sed -i .bak -e "s/type: ${q}index-pattern${q}/type: ${q}index_pattern${q}/g" -e "s/type = ${q}index-pattern${q}/type = ${q}index_pattern${q}/g" -e "s%${q}index-pattern${q}: ${q}/settings/objects/savedSearches/${q}%${q}index_pattern${q}: ${q}/settings/objects/savedSearches/${q}%g" optimize/bundles/kibana.bundle.js src/ui/public/index_patterns/*.js
- If you want to load sample data from Kibana Getting started, apply the following changes to logstash.jsonl with a sed command.
s/logstash-2015.05.18/logstash_20150518/g
s/logstash-2015.05.19/logstash_20150519/g
s/logstash-2015.05.20/logstash_20150520/g
s/article:modified_time/articleModified_time/g
s/article:published_time/articlePublished_time/g
s/article:section/articleSection/g
s/article:tag/articleTag/g
s/og:type/ogType/g
s/og:title/ogTitle/g
s/og:description/ogDescription/g
s/og:site_name/ogSite_name/g
s/og:url/ogUrl/g
s/og:image:width/ogImageWidth/g
s/og:image:height/ogImageHeight/g
s/og:image/ogImage/g
s/twitter:title/twitterTitle/g
s/twitter:description/twitterDescription/g
s/twitter:card/twitterCard/g
s/twitter:image/twitterImage/g
s/twitter:site/twitterSite/g
| Elasticsearch | Cassandra | Description |
|---|---|---|
| Cluster | Virtual Datacenter | All nodes of a datacenter forms an Elasticsearch cluster |
| Shard | Node | Each cassandra node is an elasticsearch shard for each indexed keyspace. |
| Index | Keyspace | An elasticsearch index is backed by a keyspace |
| Type | Table | Each elasticsearch document type is backed by a cassandra table |
| Document | Row | An elasticsearch document is backed by a cassandra row. |
| Field | Column | Each indexed field is backed by a cassandra column. |
| Object or nested field | User Defined Type | Automatically create User Defined Type to store elasticsearch object. |
From an Elasticsearch perspective :
- An Elasticsearch cluster is a Cassandra virtual datacenter.
- Every Elassandra node is a master primary data node.
- Each node only index local data and acts as a primary local shard.
- Elasticsearch data is not more stored in lucene indices, but in cassandra tables.
- An Elasticsearch index is mapped to a cassandra keyspace,
- Elasticsearch document type is mapped to a cassandra table.
- Elasticsearch document _id is a string representation of the cassandra primary key.
- Elasticsearch discovery now rely on the cassandra gossip protocol. When a node join or leave the cluster, or when a schema change occurs, each nodes update nodes status and its local routing table.
- Elasticsearch gateway now store metadata in a cassandra table and in the cassandra schema. Metadata updates are played sequentially through a cassandra lightweight transaction. Metadata UUID is the cassandra hostId of the last modifier node.
- Elasticsearch REST and java API remain unchanged (version 1.5).
- River plugins remain fully operational.
- Logging is now based on logback as cassandra.
From a Cassandra perspective :
- Columns with an ElasticSecondaryIndex are indexed in Elasticsearch.
- By default, Elasticsearch document fields are multivalued, so every field is backed by a list. Single valued document field can be mapped to a basic types by setting 'cql_collection: singleton' in our type mapping. See Elasticsearch document mapping for details.
- Nested documents are stored using cassandra User Defined Type or map.
- Elasticsearch provides a JSON-REST API to cassandra, see Elasticsearch API.
- Elassandra uses Maven for its build system. Simply run the
mvn clean package -Dmaven.test.skip=true -Dcassandra.home=<path/to/cassandra>command in the cloned directory. The distribution will be created under target/releases.
- Install Java version 8 (check version with
java -version). Version 8 is recommanded, see Installing Oracle JDK on RHEL-based Systems. - Apply OS settings for cassandra, see Recommended production settings for Linux
- Install jemalloc library (yum install jemalloc).
- Download Elassandra tarbal from elassandra repository and extract files in your installation directory
- Install the cassandra driver
pip install cassandra-driverand the cqlsh utilitypython pylib/setup.py install - Configure your cassandra cluster (cluster name, sntich, ip address, seed...), see cassandra configuration. Default Elasticsearch configuration is located in
conf/elasticsearch.yml, but you should NOT use it, everything is inherited from the cassandra.yml (cluster name, listen adress, paths, etc...). - Configure cassandra and elasticsearch logging in conf/logback.xml, see logback framework.
- Set
CASSANDRA_HOME=<elassandra_install_dir> - Run
<elassandra_install_dir>/bin/cassandra -eto start a cassandra node including elasticsearch (or the ecstart alias from bin/shorcuts-env.sh). - The cassandra logs in
logs/system.logincludes elasticsearch logs according to the yourconf/logback.confsettings.
Check your cassandra node status:
nodetool status
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 127.0.0.1 57,61 KB 2 ? 74ae1629-0149-4e65-b790-cd25c7406675 RAC1
Check your Elasticsearch cluster state.
curl -XGET 'http://localhost:9200/_cluster/state/?pretty=true'
{
"cluster_name" : "Test Cluster",
"version" : 1,
"master_node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"blocks" : { },
"nodes" : {
"74ae1629-0149-4e65-b790-cd25c7406675" : {
"name" : "localhost",
"status" : "ALIVE",
"transport_address" : "inet[localhost/127.0.0.1:9300]",
"attributes" : {
"data" : "true",
"rack" : "RAC1",
"data_center" : "DC1",
"master" : "true"
}
}
},
"metadata" : {
"version" : 0,
"uuid" : "74ae1629-0149-4e65-b790-cd25c7406675",
"templates" : { },
"indices" : { }
},
"routing_table" : {
"indices" : { }
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"74ae1629-0149-4e65-b790-cd25c7406675" : [ ]
}
},
"allocations" : [ ]
}
As you can see, Elasticsearch node UUID = cassandra hostId, and node attributes match your cassandra datacenter and rack.
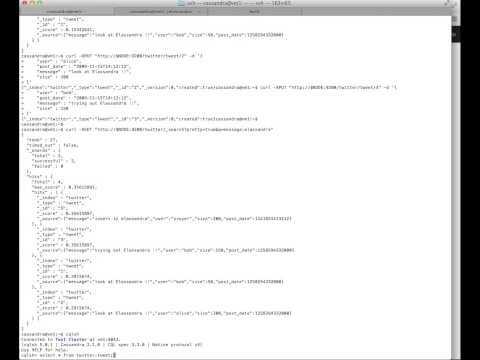
Let's try and index some twitter like information (demo from Elasticsearch). First, let's create a twitter user, and add some tweets (the twitter index will be created automatically):
curl -XPUT 'http://localhost:9200/twitter/user/kimchy' -d '{ "name" : "Shay Banon" }'
curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '
{
"user": "kimchy",
"postDate": "2009-11-15T13:12:00",
"message": "Trying out Elassandra, so far so good?"
}'
curl -XPUT 'http://localhost:9200/twitter/tweet/2' -d '
{
"user": "kimchy",
"postDate": "2009-11-15T14:12:12",
"message": "Another tweet, will it be indexed?"
}'
You now have two rows in the cassandra twitter.tweet table.
cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.8 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh> select * from twitter.tweet;
_id | message | postDate | user
-----+--------------------------------------------+------------------------------+------------
2 | ['Another tweet, will it be indexed?'] | ['2009-11-15 15:12:12+0100'] | ['kimchy']
1 | ['Trying out Elassandra, so far so good?'] | ['2009-11-15 14:12:00+0100'] | ['kimchy']
(2 rows)
cqlsh> describe table twitter.tweet;
CREATE TABLE twitter.tweet (
"_id" text PRIMARY KEY,
message list<text>,
"postDate" list<timestamp>,
user list<text>
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = 'Auto-created by Elassandra'
AND compaction = {'min_threshold': '4', 'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE CUSTOM INDEX elastic_tweet_message_idx ON twitter.tweet (message) USING 'org.elasticsearch.cassandra.index.ElasticSecondaryIndex';
CREATE CUSTOM INDEX elastic_tweet_postDate_idx ON twitter.tweet ("postDate") USING 'org.elasticsearch.cassandra.index.ElasticSecondaryIndex';
CREATE CUSTOM INDEX elastic_tweet_user_idx ON twitter.tweet (user) USING 'org.elasticsearch.cassandra.index.ElasticSecondaryIndex';
Now, let's see if the information was added by GETting it:
curl -XGET 'http://localhost:9200/twitter/user/kimchy?pretty=true'
curl -XGET 'http://localhost:9200/twitter/tweet/1?pretty=true'
curl -XGET 'http://localhost:9200/twitter/tweet/2?pretty=true'
Elasticsearch state now show reflect the new twitter index. Because we are currently running on one node, the token_ranges routing attribute match 100% of the ring Long.MIN_VALUE to Long.MAX_VALUE.
curl -XGET 'http://localhost:9200/_cluster/state/?pretty=true'
{
"cluster_name" : "Test Cluster",
"version" : 5,
"master_node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"blocks" : { },
"nodes" : {
"74ae1629-0149-4e65-b790-cd25c7406675" : {
"name" : "localhost",
"status" : "ALIVE",
"transport_address" : "inet[localhost/127.0.0.1:9300]",
"attributes" : {
"data" : "true",
"rack" : "RAC1",
"data_center" : "DC1",
"master" : "true"
}
}
},
"metadata" : {
"version" : 3,
"uuid" : "74ae1629-0149-4e65-b790-cd25c7406675",
"templates" : { },
"indices" : {
"twitter" : {
"state" : "open",
"settings" : {
"index" : {
"creation_date" : "1440659762584",
"uuid" : "fyqNMDfnRgeRE9KgTqxFWw",
"number_of_replicas" : "1",
"number_of_shards" : "1",
"version" : {
"created" : "1050299"
}
}
},
"mappings" : {
"user" : {
"properties" : {
"name" : {
"type" : "string"
}
}
},
"tweet" : {
"properties" : {
"message" : {
"type" : "string"
},
"postDate" : {
"format" : "dateOptionalTime",
"type" : "date"
},
"user" : {
"type" : "string"
}
}
}
},
"aliases" : [ ]
}
}
},
"routing_table" : {
"indices" : {
"twitter" : {
"shards" : {
"0" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"token_ranges" : [ "(-9223372036854775808,9223372036854775807]" ],
"shard" : 0,
"index" : "twitter"
} ]
}
}
}
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"74ae1629-0149-4e65-b790-cd25c7406675" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"token_ranges" : [ "(-9223372036854775808,9223372036854775807]" ],
"shard" : 0,
"index" : "twitter"
} ]
}
},
"allocations" : [ ]
}
Let's find all the tweets that kimchy posted:
curl -XGET 'http://localhost:9200/twitter/tweet/_search?q=user:kimchy&pretty=true'
We can also use the JSON query language Elasticsearch provides instead of a query string:
curl -XGET 'http://localhost:9200/twitter/tweet/_search?pretty=true' -d '
{
"query" : {
"match" : { "user": "kimchy" }
}
}'
Just for kicks, let's get all the documents stored (we should see the user as well):
curl -XGET 'http://localhost:9200/twitter/_search?pretty=true' -d '
{
"query" : {
"matchAll" : {}
}
}'
We can also do range search (the 'postDate' was automatically identified as date)
curl -XGET 'http://localhost:9200/twitter/_search?pretty=true' -d '
{
"query" : {
"range" : {
"postDate" : { "from" : "2009-11-15T13:00:00", "to" : "2009-11-15T14:00:00" }
}
}
}'
There are many more options to perform search, after all, it's a search product no? All the familiar Lucene queries are available through the JSON query language, or through the query parser.
Unlike Elasticsearch, sharding depends on the number of nodes in the datacenter, and number of replica is defined by your keyspace Replication Factor. Elasticsearch numberOfShards then becomes meaningless.
- When adding a new elasticassandra node, the cassandra boostrap process gets some token ranges from the existing ring and pull the corresponding data. Pulled data are automatically indexed and each node update its routing table to distribute search requests according to the ring topology.
- When updating the Replication Factor, you will need to run a nodetool repair on the new node to effectivelly copy and index the data.
- If a node become unavailable, the routing table is updated on all nodes in order to route search requests on available nodes. The actual default strategy routes search requests on primary token ranges' owner first, then to replica nodes if available. If some token ranges become unreachable, the cluster status is red, otherwise cluster status is yellow.
After starting a new Elassandra node, data and elasticsearch indices are distributed on 2 nodes (with no replication).
nodetool status twitter
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 156,9 KB 2 70,3% 74ae1629-0149-4e65-b790-cd25c7406675 RAC1
UN 127.0.0.2 129,01 KB 2 29,7% e5df0651-8608-4590-92e1-4e523e4582b9 RAC2
The routing table now distributes search request on 2 elasticassandra nodes to cover 100% of ring.
curl -XGET 'http://localhost:9200/_cluster/state/?pretty=true'
{
"cluster_name" : "Test Cluster",
"version" : 12,
"master_node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"blocks" : { },
"nodes" : {
"74ae1629-0149-4e65-b790-cd25c7406675" : {
"name" : "localhost",
"status" : "ALIVE",
"transport_address" : "inet[localhost/127.0.0.1:9300]",
"attributes" : {
"data" : "true",
"rack" : "RAC1",
"data_center" : "DC1",
"master" : "true"
}
},
"e5df0651-8608-4590-92e1-4e523e4582b9" : {
"name" : "127.0.0.2",
"status" : "ALIVE",
"transport_address" : "inet[127.0.0.2/127.0.0.2:9300]",
"attributes" : {
"data" : "true",
"rack" : "RAC2",
"data_center" : "DC1",
"master" : "true"
}
}
},
"metadata" : {
"version" : 1,
"uuid" : "e5df0651-8608-4590-92e1-4e523e4582b9",
"templates" : { },
"indices" : {
"twitter" : {
"state" : "open",
"settings" : {
"index" : {
"creation_date" : "1440659762584",
"uuid" : "fyqNMDfnRgeRE9KgTqxFWw",
"number_of_replicas" : "1",
"number_of_shards" : "1",
"version" : {
"created" : "1050299"
}
}
},
"mappings" : {
"user" : {
"properties" : {
"name" : {
"type" : "string"
}
}
},
"tweet" : {
"properties" : {
"message" : {
"type" : "string"
},
"postDate" : {
"format" : "dateOptionalTime",
"type" : "date"
},
"user" : {
"type" : "string"
},
"_token" : {
"type" : "long"
}
}
}
},
"aliases" : [ ]
}
}
},
"routing_table" : {
"indices" : {
"twitter" : {
"shards" : {
"0" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"token_ranges" : [ "(-8879901672822909480,4094576844402756550]" ],
"shard" : 0,
"index" : "twitter"
} ],
"1" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "e5df0651-8608-4590-92e1-4e523e4582b9",
"token_ranges" : [ "(-9223372036854775808,-8879901672822909480]", "(4094576844402756550,9223372036854775807]" ],
"shard" : 1,
"index" : "twitter"
} ]
}
}
}
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"e5df0651-8608-4590-92e1-4e523e4582b9" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "e5df0651-8608-4590-92e1-4e523e4582b9",
"token_ranges" : [ "(-9223372036854775808,-8879901672822909480]", "(4094576844402756550,9223372036854775807]" ],
"shard" : 1,
"index" : "twitter"
} ],
"74ae1629-0149-4e65-b790-cd25c7406675" : [ {
"state" : "STARTED",
"primary" : true,
"node" : "74ae1629-0149-4e65-b790-cd25c7406675",
"token_ranges" : [ "(-8879901672822909480,4094576844402756550]" ],
"shard" : 0,
"index" : "twitter"
} ]
}
},
"allocations" : [ ]
}
Internally, each node broadcasts its local shard status in the gossip application state X1 ( "twitter":3 stands for STARTED as defined in ShardRoutingState) and its current metadata UUID/version in application state X2.
nodetool gossipinfo
127.0.0.2/127.0.0.2
generation:1440659838
heartbeat:396197
DC:DC1
NET_VERSION:8
SEVERITY:-1.3877787807814457E-17
X1:{"twitter":3}
X2:e5df0651-8608-4590-92e1-4e523e4582b9/1
RELEASE_VERSION:2.1.8
RACK:RAC2
STATUS:NORMAL,-8879901672822909480
SCHEMA:ce6febf4-571d-30d2-afeb-b8db9d578fd1
INTERNAL_IP:127.0.0.2
RPC_ADDRESS:127.0.0.2
LOAD:131314.0
HOST_ID:e5df0651-8608-4590-92e1-4e523e4582b9
localhost/127.0.0.1
generation:1440659739
heartbeat:396550
DC:DC1
NET_VERSION:8
SEVERITY:2.220446049250313E-16
X1:{"twitter":3}
X2:e5df0651-8608-4590-92e1-4e523e4582b9/1
RELEASE_VERSION:2.1.8
RACK:RAC1
STATUS:NORMAL,-4318747828927358946
SCHEMA:ce6febf4-571d-30d2-afeb-b8db9d578fd1
RPC_ADDRESS:127.0.0.1
INTERNAL_IP:127.0.0.1
LOAD:154824.0
HOST_ID:74ae1629-0149-4e65-b790-cd25c7406675
(#Elasticsearch-document-mapping)
Here is the mapping from Elasticsearch field basic types to CQL3 types :
| Elasticearch Types | CQL Types | Comment |
|---|---|---|
| string | text | |
| integer, short, byte | timestamp | |
| long | bigint | |
| double | double | |
| float | float | |
| boolean | boolean | |
| binary | blob | |
| ip | inet | Internet address |
| geo_point | UDT geo_point | Built-In User Defined Type |
| geo_shape | UDT geo_shape | Not yet implemented |
| object, nested | Custom User Defined Type |
These parameters control the cassandra mapping.
| Parameter | Values | Description |
|---|---|---|
| cql_collection | list, set or singleton | Control how the field of type X is mapped to a column list, set or X. Default is list because Elasticsearch fields are multivalued. |
| cql_struct | udt or map | Control how an object or nested field is mapped to a User Defined Type or to a cassandra map<text,?>. Default is udt. |
| cql_partial_update | true or false | Elasticsearch index full document. For partial CQL updates, this control which fields should be read to index a full document from a row. Default is true meaning that updates involve reading all missing fields. |
| cql_primary_key_order | integer | Field position in the cassandra the primary key of the underlying cassandra table. Default is -1 meaning that the field is not part of the cassandra primary key. |
| cql_partition_key | true or false | When the cql_primary_key_order >= 0, specify if the field is part of the cassandra partition key. Default is false meaning that the field is not part of the cassandra partition key. |
For more information about cassandra collection types and compound primary key, see https://docs.datastax.com/en/cql/3.1/cql/cql_using/use_collections_c.html and https://docs.datastax.com/en/cql/3.1/cql/ddl/ddl_compound_keys_c.html.
A new put mapping parameter column_regexp allow to create Elasticsearch mapping from an existing cassandra table for columns whose name match the provided regular expression. The following command create the elasticsearch mapping for all columns starting by 'a' of the cassandra table my.keyspace.my_table.and set a specific analyzer for column name.
curl -XPUT "http://localhost:9200/my_keyspace/_mapping/my_table" -d '{
"my_table" : {
"columns_regexp" : "a.*",
"properties" : {
"name" : {
"type" : "string",
"index" : "not_analyzed"
}
}
}
}'
When creating the first Elasticsearch index for a given cassandra table, custom CQL3 secondary indices are created when all shards are started. Then cassandra asynchronously build index on all nodes for all existing data. Subsequent CQL inserts or updates are automatically indexed in Elasticsearch. Moreover, if you then add a second or more Elasticsearch indices to an existing indexed table, see Mapping change with zero downtime, existing data are not automatically indexed because cassandra has already indexed existing data. Rebuild the cassandra index to re-index all existing data in all Elasticsearch indices.
When mapping an existing cassandra table to an Elasticsearch index.type, primary key is mapped to the _id field.
- Single primary key is converted to a string.
- Compound primary key is converted to a JSON array stored as string in the
_idfield.
In a table that use clustering columns, a static columns is shared by all the rows with the same partition key. A slight modification of cassandra code provides support of secondary index on static columns, allowing to search on static columns values (CQL search on static columns remains unsupported). Each time a static columns is modified, a document containing the partition key and only static columns is indexed in Elasticserach. Static columns are not indexed with every wide rows because any update on a static column would require reindexation of all wide rows. However, you can request for fields backed by a static columns on any get/search request.
The following example demonstrates how to use static columns to store meta information of timeseries.
curl -XPUT "http://localhost:9200/test" -d '{
..."mappings" : {
"timeseries" : {
"properties" : {
"t" : {
"type" : "date",
"format" : "strict_date_optional_time||epoch_millis",
"cql_primary_key_order" : 1,
"cql_collection" : "singleton"
},
"meta" : {
"type" : "nested",
"cql_struct" : "map",
"cql_static_column" : true,
"cql_collection" : "singleton",
"include_in_parent" : true,
"properties" : {
"region" : {
"type" : "string"
}
}
},
"v" : {
"type" : "double",
"cql_collection" : "singleton"
},
"m" : {
"type" : "string",
"cql_partition_key" : true,
"cql_primary_key_order" : 0,
"cql_collection" : "singleton"
}
}
}
}
}'
cqlsh <<EOF
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:30', 10);
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:31', 20);
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:32', 15);
INSERT INTO test.timeseries (m, meta) VALUES ('server1-cpu', { 'region':'west' } );
SELECT * FROM test.timeseries;
EOF
m | t | meta | v
-------------+-----------------------------+--------------------+----
server1-cpu | 2016-04-10 11:30:00.000000z | {'region': 'west'} | 10
server1-cpu | 2016-04-10 11:31:00.000000z | {'region': 'west'} | 20
server1-cpu | 2016-04-10 11:32:00.000000z | {'region': 'west'} | 15
Search for wide rows only where v=10 and fetch the meta.region field.
curl -XGET "http://$NODE:9200/test/timeseries/_search?pretty=true&q=v:10&fields=m,t,v,meta.region"
...
"hits" : [ {
"_index" : "test",
"_type" : "timeseries",
"_id" : "[\"server1-cpu\",1460287800000]",
"_score" : 1.9162908,
"_routing" : "server1-cpu",
"fields" : {
"meta.region" : [ "west" ],
"t" : [ "2016-04-10T11:30:00.000Z" ],
"m" : [ "server1-cpu" ],
"v" : [ 10.0 ]
}
} ]
Search for rows where meta.region=west, returns only the partition key and static columns.
curl -XGET "http://$NODE:9200/test/timeseries/_search?pretty=true&q=meta.region:west&fields=m,t,v,meta.region"
....
"hits" : {
"total" : 1,
"max_score" : 1.5108256,
"hits" : [ {
"_index" : "test",
"_type" : "timeseries",
"_id" : "server1-cpu",
"_score" : 1.5108256,
"_routing" : "server1-cpu",
"fields" : {
"m" : [ "server1-cpu" ],
"meta.region" : [ "west" ]
}
} ]
You can map servral Elasticsearch indices with different mapping to the same cassandra keyspace. By default, an index is mapped to a keyspace with the same name, but you can specify a target keyspace.

For exemple, the following command creates a new index twitter2 mapped to the cassandra keyspace twitter and set a mapping for type tweet associated to the existing cassandra table twitter.tweet.
curl -XPUT "http://localhost:9200/twitter2/" -d '{ "settings" : { "keyspace_name" : "twitter" } }'
curl -XPUT "http://localhost:9200/twitter2/_mapping/tweet" -d '{
"tweet" : {
"properties" : {
"message" : { "type" : "string", "index" : "not_analyzed" },
"post_date" : { "type" : "date", "format": "yyyy-MM-dd" },
"user" : { "type" : "string","index" : "not_analyzed" },
"size" : { "type" : "long" }
}
}
}'
You can set a specific mapping for twitter2 and re-index existing data on each cassandra node with the following command (indices are named elastic_).
nodetool rebuild_index twitter tweet elastic_tweet
Once your twitter2 index is ready, set an alias twitter for twitter2 to switch from the old mapping to the new one, and delete the old twitter index.
curl -XPOST "http://localhost:9200/_aliases" -d '{ "actions" : [ { "add" : { "index" : "twitter2", "alias" : "twitter" } } ] }'
curl -XDELETE "http://localhost:9200/twitter"
By default, Elasticsearch object or nested types are mapped to dynamically created Cassandra User Defined Types.
curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{
"user" : {
"name" : {
"first_name" : "Vincent",
"last_name" : "Royer"
},
"uid" : "12345"
},
"message" : "This is a tweet!"
}'
curl -XGET 'http://localhost:9200/twitter/tweet/1/_source'
{"message":"This is a tweet!","user":{"uid":["12345"],"name":[{"first_name":["Vincent"],"last_name":["Royer"]}]}}
The resulting cassandra user defined types and table.
cqlsh>describe keyspace twitter;
CREATE TYPE twitter.tweet_user (
name frozen<list<frozen<tweet_user_name>>>,
uid frozen<list<text>>
);
CREATE TYPE twitter.tweet_user_name (
last_name frozen<list<text>>,
first_name frozen<list<text>>
);
CREATE TABLE twitter.tweet (
"_id" text PRIMARY KEY,
message list<text>,
person list<frozen<tweet_person>>
)
cqlsh> select * from twitter.tweet;
_id | message | user
-----+----------------------+-----------------------------------------------------------------------------
1 | ['This is a tweet!'] | [{name: [{last_name: ['Royer'], first_name: ['Vincent']}], uid: ['12345']}]
Since version 0.3, nested document can be mapped to User Defined Type or to CQL map. In the following example, the cassandra map is automatically mapped with cql_partial_update:true, so a partial CQL update cause a read of the whole map to re-index a document in the elasticsearch index.
Create an index (a keyspace in your elassandra-aware datacenter)
curl -XPUT "http://localhost:9200/twitter"
Create a cassandra table with a map column.
cqlsh>CREATE TABLE twitter.user (
name text,
attrs map<text,text>,
primary key (name)
);
cqlsh>INSERT INTO twitter.user (name,attrs) VALUES ('bob',{'email':'[email protected]','firstname':'bob'});
Create the type mapping from the cassandra table and search for the bob entry.
curl -XPUT "http://localhost:9200/twitter/_mapping/user" -d '{ "user" : { "columns_regexp" : ".*" }}'
{"acknowledged":true}
curl -XGET 'http://localhost:9200/twitter/_mapping/user?pretty=true'
{
"twitter" : {
"mappings" : {
"user" : {
"properties" : {
"attrs" : {
"type" : "nested",
"cql_struct" : "map",
"cql_collection" : "singleton",
"properties" : {
"email" : {
"type" : "string"
},
"firstname" : {
"type" : "string"
}
}
},
"name" : {
"type" : "string",
"cql_collection" : "singleton",
"cql_partition_key" : true,
"cql_primary_key_order" : 0
}
}
}
}
}
}
Get the bob entry.
curl -XGET "http://localhost:9200/twitter/user/bob?pretty=true"
{
"_index" : "twitter",
"_type" : "user",
"_id" : "bob",
"_version" : 0,
"found" : true,
"_source":{"name":"bob","attrs":{"email":"[email protected]","firstname":"bob"}}
}
Now insert a new entry in the attrs map column and search for a nested field attrs.city:paris.
cqlsh>UPDATE twitter.user SET attrs = attrs + { 'city':'paris' } WHERE name = 'bob';
curl -XGET "http://localhost:9200/twitter/_search?pretty=true" -d '{
"query":{
"nested":{
"path":"attrs",
"query":{ "match": {"attrs.city":"paris" } }
}
}
}'
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 2.3862944,
"hits" : [ {
"_index" : "twitter",
"_type" : "user",
"_id" : "bob",
"_score" : 2.3862944,
"_source":{"attrs":{"city":"paris","email":"[email protected]","firstname":"bob"},"name":"bob"}
} ]
}
}
Elassandra supports parent-child relationship when parent and child document are located on the same cassandra node. This condition is met when running a single node cluster, when the keyspace replication factor equals the number of nodes or when the parent and child documents share the same cassandra partition key, as shown in the folling exemple :
Create an index company (a cassandra keyspace), a cassandra table, insert 2 rows and map this table as document type employee.
curl -XPUT "http://$NODE:9200/company/"
cqlsh <<EOF
CREATE TABLE company.employee (
"_parent" text,
"_id" text,
name text,
dob timestamp,
hobby text,
primary key (("_parent"),"_id")
);
INSERT INTO company.employee ("_parent","_id",name,dob,hobby) VALUES ('london','1','Alice Smith','1970-10-24','hiking');
INSERT INTO company.employee ("_parent","_id",name,dob,hobby) VALUES ('london','2','Alice Smith','1990-10-24','hiking');
EOF
curl -XPUT "http://$NODE:9200/company/_mapping/employee" -d '
{ "employee" : {
"columns_regexp" : ".*",
"properties" : {
"name" : {
"type" : "string",
"index" : "not_analyzed",
"cql_collection" : "singleton"
}
},
"_parent": {
"type": "branch"
}
}
}'
Now insert documents in the parent type branch.
curl -XPOST "http://127.0.0.1:9200/company/branch/_bulk" -d '
{ "index": { "_id": "london" }}
{ "district": "London Westminster", "city": "London", "country": "UK" }
{ "index": { "_id": "liverpool" }}
{ "district": "Liverpool Central", "city": "Liverpool", "country": "UK" }
{ "index": { "_id": "paris" }}
{ "district": "Champs Élysées", "city": "Paris", "country": "France" }'
Add employee document setting the _parent and _id as parameters or as a JSON array.
curl -XPUT "http://$NODE:9200/company2/employee/3?parent=liverpool" -d '{
"name": "Alice Smith",
"dob": "1990-10-24",
"hobby": "windsurfing"
}'
curl -XPUT "http://$NODE:9200/company2/employee/\[\"liverpool\",\"4\"\]" -d '{
"name": "Bob robert",
"dob": "1990-10-24",
"hobby": "truc"
}'
Search for documents having chidren document of type employee with dob date geater than 1980.
curl -XGET "http://$NODE:9200/company2/branch/_search?pretty=true" -d '{
"query": {
"has_child": {
"type": "employee",
"query": {
"range": {
"dob": {
"gte": "1980-01-01"
}
}
}
}
}
}'
Search for employee documents having a parent document where country match UK.
curl -XGET "http://$NODE:9200/company2/employee/_search?pretty=true" -d '{
"query": {
"has_parent": {
"parent_type": "branch",
"query": {
"match": { "country": "UK"
}
}
}
}
}'
When indexing a document, you can set write consistency level like this.
curl -XPUT 'http://localhost:9200/twitter/user/kimchy?consistency=one' -d '{ "name" : "Shay Banon" }'
| Elasticsearch | Cassandra | Comment |
|---|---|---|
| DEFAULT | LOCAL_ONE | One in local datacenter |
| ONE | LOCAL_ONE | |
| QUORUM | LOCAL_QUORUM | |
| ALL | ALL | Because there is no LOCAL_ALL in cassandra, ALL involve write in all datacenters hosting the keyspace. |
-
Cassandra
-
Thrift is not supported, only CQL3.
-
CQL3 truncate has not effect on elasticsearch indices.
-
Elasticsearch
-
tribe, percolate, snapshots and recovery service not tested.
-
Geoshape type not supported.
-
Any Elasticsearch metadata update require the LOCAL_QUORUM (more than half the number of nodes in the elassandra datacenter)
-
Document version is alaways 1 for all documents (because cassandra index rebuild would increment version many times, document version become meaningless).
Contributors are welcome to test and enhance Elassandra to make it production ready.
This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015, Vincent Royer ([email protected]).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.