Comments (55)
 edenhill
commented on May 13, 2024
4
edenhill
commented on May 13, 2024
4
In your first example you are effectively implementing a sync producer, it will send one message and wait for an ack (reply) from the broker.
This is a complete performance killer since the thruput is limited by the network round-trip-time plus broker processing.
It is also made worse by the default batching behaviour of the client, it will buffer messages for up to queue.buffering.max.ms before sending to the broker. This value defaults to 1000ms which seems in-line with what you are seeing.
What you typically do is Produce() and then move on to producing new messages, and you check the delivery results on your deliveryChan(s) through Go-routines or similar. This way thruput is not limited by broker round-trip-time.
In your second example you've cut out the return path / delivery chan completely, so this will work at full speed up until the default delivery channel gets full, and that is also the reason why you are seeing a "memory leak". There is no actual memory leak, but the client is expecting you to read off the default producer.Events channel to serve delivery reports.
If you are completely uninterested in delivery state (which you might want to reconsider) you need to disable the default delivery reports too by setting go.delivery.reports to false.
See the documentation here for more info: http://docs.confluent.io/3.1.2/clients/confluent-kafka-go/index.html#hdr-Producer
from confluent-kafka-go.
 groyee
commented on May 13, 2024
1
groyee
commented on May 13, 2024
1
I don't think the leak is in my app as sending nil on the Producer channel works fine with no leaks.
I will reduce the queued.max.messages.kbytes and try to check now with the pprof where is the leak coming from.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
1
@liubin The problem with these simple sync interfaces is that it tricks new developers into not thinking about what happens when the network starts acting up, broker becoming slow, etc.
A sync interface will work okay as long as the latency is low and there are no problems, but as soon as a produce request can't be immediately served the application will hang, possibly backpressuring its input source. This might be okay in some situations, and it is easy enough to wrap the async produce interface to make it sync (temporary delivery channel + blocking read on that channel after Produce()), but for most situations it is more important to maintain some degree of throughput and not stall the calling application.
There's some more information here:
https://github.com/edenhill/librdkafka/wiki/FAQ#why-is-there-no-sync-produce-interface
And here's an example how to make a sync produce call:
drChan := make(chan Event, 1)
err := p.Produce(&Message{
TopicPartition: TopicPartition{Topic: &topic, Partition: -1},
Value: []byte(value),
drChan)
if err != nil {
Fatalf("Produce: %v", err)
}
// Wait for delivery
ev := <-drChan
m := ev.(*Message)
if m.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v", m.TopicPartition)
}
fmt.Printf("Produced message to %v", m.TopicPartition)from confluent-kafka-go.
 maeglindeveloper
commented on May 13, 2024
1
maeglindeveloper
commented on May 13, 2024
1
Hi everyone,
It seems this issue has been closed for a while, but... I have actually tried the code @edenhill provided and I still have the same memory leak issue (using pprof).
I gave a try to the code from the official documentation, same issue.
Anyone had the chance to perform a Produce message without memory leak ? :(
Thanks in advance
from confluent-kafka-go.
groyee
commented on May 13, 2024
Our server is currently running in production and it receives messages from Kafka, process them and then sends it back to Kafka.
The receive and process part is very fast and if the send part cannot have the same speed we have a growing backlog.
The code I showed above is executed in a go routine. I limit the number of go routines to 500 otherwise I can get to out of memory.
So yes, the code is done on go routine, but still I get to 500 very fast and then I am back to the same point where the send can't be as fast as receive.
Do I have any other option except disabling the acks?
Should this help?
producer, err:= kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": kf.broker,
"default.topic.config": kafka.ConfigMap{"acks": 1}})
If the default is "all" then i guess 1 should be faster and better than zero, right?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Did you try lowering queue.buffering.max.ms?
(the default value of acks is 1, not all, see https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md)
from confluent-kafka-go.
groyee
commented on May 13, 2024
I will give it a try now
from confluent-kafka-go.
groyee
commented on May 13, 2024
Unfortunately the situation is even worse than I thought:
Here is my code:
func (kf *KafkaHelper)CreateProducer(concurrency int){
producer, err:= kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": kf.broker,
"go.delivery.reports": false,
"queue.buffering.max.ms": 10})
if err != nil{
logger.Errorf("Failed to create producer: %s\n", err)
panic("Exiting")
}
kf.Producer = producer
}
func (kf *KafkaHelper)Produce(bulk string){
go kf.produceAsync(bulk)
}
func (kf *KafkaHelper)produceAsync(bulk string){
deliveryChan := make(chan kafka.Event)
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, deliveryChan)
e := <-deliveryChan
m := e.(*kafka.Message)
if m.TopicPartition.Error != nil {
logger.Errorf("Delivery failed: %v\n", m.TopicPartition.Error)
}
close(deliveryChan)
}
Here is the output:

I removed the go routine limitation and as you can see from the log, the number of go routines grows constantly and indefinitely until it crashes. I added a log just after close(deliveryChan) to make sure we always get there and we are, but still this go routine stays in the memory even thought it finishes this function.
One thing to mention is that it happens only in our production while it works fine in the test system. The only difference is that in test we have 1 Kafka and in production we have a cluster of 3.
Currently the only thing that holds our production is the following code. This code handles all messages with just about 10 routines:
//deliveryChan := make(chan kafka.Event)
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, nil)
//e := <-deliveryChan
//m := e.(*kafka.Message)
//if m.TopicPartition.Error != nil {
// logger.Errorf("Delivery failed: %v\n", m.TopicPartition.Error)
//}
//close(deliveryChan)
And after ~20 minutes I need to do restart because of out of memory (Because of what you explained earlier).
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Can you try making your deliveryChans buffered (a size of 1 is okay) to avoid the background poller to block waiting to enqueue the delivery report event?
from confluent-kafka-go.
groyee
commented on May 13, 2024
I tried now with:
deliveryChan := make(chan kafka.Event, 1)
Same thing. These go routines never dies. It's not like it takes a second and then they die. They just never die.
Here is a good log that demonstrates the issue:

logsparser_1 is running with this code:
//deliveryChan := make(chan kafka.Event)
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, nil)
//e := <-deliveryChan
//m := e.(*kafka.Message)
//if m.TopicPartition.Error != nil {
// logger.Errorf("Delivery failed: %v\n", m.TopicPartition.Error)
//}
//close(deliveryChan)
logsparser_2 is running with this code:
deliveryChan := make(chan kafka.Event, 1)
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, deliveryChan)
e := <-deliveryChan
m := e.(*kafka.Message)
if m.TopicPartition.Error != nil {
logger.Errorf("Delivery failed: %v\n", m.TopicPartition.Error)
}
close(deliveryChan)
The number of go routines in logsparser_1 is stable while logsparser_2 is growing rapidly.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Do you think that channel creation might be too slow for this approach?
Can you try replacing the Produce() call with something simple to post a message to the dr channel so we can measure the throughput with the Kafka client?
from confluent-kafka-go.
groyee
commented on May 13, 2024
I think I found the guilty code:
First I tried what you suggested:
//Declare once
var deliveryChan chan kafka.Event = make(chan kafka.Event, 100)
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, deliveryChan)
<-deliveryChan
}
I got same results.
However, then I tried this:
//Declare once
var deliveryChan chan kafka.Event = make(chan kafka.Event, 100)
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, deliveryChan)
start:=time.Now()
<-deliveryChan
elapsed := time.Since(start)
logger.Infof("Pooling from channel took %s", elapsed)}
To measure <-deliveryChan
I was shocked to see the results:

After a while it gets even worse and I get results over 10 seconds
I don't need anything from this channel. Is there anyway to skip this code?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
If you dont need delivery reports (which you might want to reconsider - how else will you know if things start failing to produce?) then you should pass null as deliveryChan to Produce()
from confluent-kafka-go.
edenhill
commented on May 13, 2024
100 messages of buffer in deliveryChan isn't much, I would play it say and up that to at least half a second worth of messages, whatever that is in your case.
It is hard to know how threads behave under heavy load, will it be the producer or consumer of a channel that is slow? That's why proper buffering will help as it takes the producer side of a channel out of the equation (hopefully).
from confluent-kafka-go.
groyee
commented on May 13, 2024
You are right.
Let me rephrase it. It would be very nice to know if delivery succeeded but only if there is a doable option for that. It is not mandatory for us but still something that is nice to have.
I will try now to change the 100 to a bigger number.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
There is the delivery.report.only.error configuration property, but it isn't really that helpful because you wont know if no such reports means messages were succesfully delivered, or just haven't failed yet (<message.timeout.ms).
from confluent-kafka-go.
groyee
commented on May 13, 2024
Just tried with:
var deliveryChan chan kafka.Event = make(chan kafka.Event, 10000)
Same results.
I just don't get it. We used to have this piece of code in Python which is way slower than GO and it handled this task with no issues.
What is the difference?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
What is your GOMAXPROCS?
from confluent-kafka-go.
groyee
commented on May 13, 2024
2
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Seems a little low, can you try increasing it to, I don't know, max(numcores, 8)?
from confluent-kafka-go.
groyee
commented on May 13, 2024
I will give it a try now although I have only 2 cores on this machine.
Where do you suspect the problem is?
I created the producer with:
"go.delivery.reports": false,
So what is taking so much time for <-deliveryChan?
from confluent-kafka-go.
groyee
commented on May 13, 2024
Same results :-(
So for now I deployed this code in production:
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic,
Partition: kafka.PartitionAny}, Value: []byte(bulk)}, nil)
}
It works, no memory issues but as you said if something goes wrong with sending message to Kafka I won't know about that...
from confluent-kafka-go.
edenhill
commented on May 13, 2024
It might be worth trying the/a global deliveryChan (either using producer.Events or your own) that you read from a single go-routine to see if you get performance degradations there as well, that could help finding the root cause of this.
from confluent-kafka-go.
groyee
commented on May 13, 2024
I tried this now:
func (kf *KafkaHelper)Produce(bulk string){
//Call directly with no go routine
kf.produceAsync(bulk)
}
var deliveryChan chan kafka.Event = make(chan kafka.Event, 10000)
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}, deliveryChan)
start:=time.Now()
<-deliveryChan
elapsed := time.Since(start)
logger.Infof("Pooling from channel took %s", elapsed)}
}
The Produce functions calls directly produceAsync (with no go routine). As you can see the pooling from channel indeed much faster now but after a minute or so it just hangs. I guess some dead lock probably?

from confluent-kafka-go.
edenhill
commented on May 13, 2024
I meant to put the deliveryChan reader in one single separate go-routine.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
And no go-routine for the Produce either
from confluent-kafka-go.
groyee
commented on May 13, 2024
Yeah, I can try that but still, sending everything on the main routine shouldn't make a deadlock, right?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
It is hard to say what is going on exactly when dry-debugging this through github :)
Another thing we want to try is using the batched channel producer, it should be more performant if you are sending a great number of small messages.
from confluent-kafka-go.
groyee
commented on May 13, 2024
I just tried with 1 go routine. Same thing. A dead lock after a few seconds.
Yeah, could be interesting to try the batched channel producer. I tried to understand the code from:
But honestly I didn't understand it.
Is there another example somewhere?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
The dead-lock could be two things:
- an actual dead-lock, be it through channels, mutexes, whatever - i.e., a bug
- channel congestion, consumer not reading fast enough. This could be chained, e.g., one go-routine could be producing too slow for another go-routine to consume, which in turns causes that one to slow down another reader of some other associated channel. These things are hairy. A low core count (2) probably wont make this any better.
The channel producer is quite straight forward to use, just create a Message object and send it on the ProduceChannel() as so:
p.ProduceChannel() <- &kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(value)}
This mode only supports the global/default p.Events delivery channel (which I think you should be using anyway). Make sure to create a single go-routine that reads delivery reports off the p.Events channel, as in the example you linked.
To enable batch producing (which is an internal implementation detail really) set go.batch.producer to true. This should improve performance.
from confluent-kafka-go.
groyee
commented on May 13, 2024
Your second theory sounds interesting and I would bet on that option.
So the channel producer should be something like that?
doneChan := make(chan bool)
func (kf *KafkaHelper)CreateProducer(concurrency int){
producer, err:= kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": kf.broker,
"go.batch.producer": true,
"queue.buffering.max.ms": 10})
if err != nil{
logger.Errorf("Failed to create producer: %s\n", err)
panic("Exiting")
}
kf.Producer = producer
go kf.resultLoop()
}
func (kf *KafkaHelper)resultLoop(){
outer:
for e := range kf.Producer.Events() {
switch ev := e.(type) {
case *kafka.Message:
m := ev
if m.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", m.TopicPartition.Error)
} else {
fmt.Printf("Delivered message to topic %s [%d] at offset %v\n",
*m.TopicPartition.Topic, m.TopicPartition.Partition, m.TopicPartition.Offset)
}
break outer
default:
fmt.Printf("Ignored event: %s\n", ev)
}
}
close(doneChan)
}
func (kf *KafkaHelper)Produce(bulk string){
go kf.produceAsync(bulk)
}
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.ProduceChannel() <- &kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}
_ = <-doneChan
}
from confluent-kafka-go.
groyee
commented on May 13, 2024
I probably need to remove the doneChan...
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Yep, remove doneChan.
configs are key:value, so should be "go.batch.producer":true"
from confluent-kafka-go.
groyee
commented on May 13, 2024
Unless I did something wrong IT LOOKS LIKE IT'S WORKING GREAT NOW!!!
:-) Finally!
Here is the final code:
func (kf *KafkaHelper)CreateProducer(concurrency int){
producer, err:= kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": kf.broker,
"go.batch.producer": true,
"queue.buffering.max.ms": 10})
if err != nil{
logger.Errorf("Failed to create producer: %s\n", err)
panic("Exiting")
}
kf.Producer = producer
go kf.resultLoop()
}
func (kf *KafkaHelper)resultLoop(){
run:=true
//We probably don't need this outer loop
for run == true {
for e := range kf.Producer.Events() {
switch ev := e.(type) {
case *kafka.Message:
m := ev
if m.TopicPartition.Error != nil {
logger.Errorf("Delivery failed: %v\n", m.TopicPartition.Error)
}
default:
logger.Errorf("Ignored event: %s\n", ev)
}
}
}
}
func (kf *KafkaHelper)Produce(bulk string){
go kf.produceAsync(bulk)
}
func (kf *KafkaHelper)produceAsync(bulk string){
topic:=viper.GetString("kafka.forwardtopic")
kf.Producer.ProduceChannel() <- &kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(bulk)}
}
I wonder what made such a difference.
Thank You!
from confluent-kafka-go.
groyee
commented on May 13, 2024
Oh well... I might was happy to early.
It handles the load perfectly with just few go routines but the memory keeps rising... 800MB after about 10 minutes.
Unless it will stop at some point... but it doesn't look like it will stop.
from confluent-kafka-go.
groyee
commented on May 13, 2024
My guess is that we just moved the problem to a different place. Now, instead of blocking, it accumulates all those results...
Is there any way to clear it somehow? This way I can call the clear method once in a while and at least I will get kafka results for some of the message...
from confluent-kafka-go.
edenhill
commented on May 13, 2024
That's great news!
Main reasons for speed-up are probably that this solution has far fewer channels, no creation&destruction of short-lived channels, fewer go-routines, and fewer C calls.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Can I ask you to give it a try with go.batch.producer set to false?
I'm curious how it behaves with your workload
from confluent-kafka-go.
groyee
commented on May 13, 2024
Sure, I can give it a try.
Have you seen my comments regarding the memory?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
What is your input message rate? (e.g., at what rate you call Produce())
What is your delivery message rate? (what rate you are seeing the Message events on the Events channel)
What is your average message size?
from confluent-kafka-go.
groyee
commented on May 13, 2024
I just checked the benchmarks
I have 10 physical hosts (with 2 cores each). Each host running 2 dockers containers. Each container runs this application.
All containers reads from the same topic (different partitions).
Each container reads about 50 msg/s. Each msg is between 100K and 1.5MB.
The processing of the messages is done really fast. ~5ms and then it tries to send the same message back to Kafka.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
So you have between 2 x 5-75 MB/s per container (consume + re-produce), times 10 containers.
How big is your cluster?
Whats the CPU, IO and network load on your brokers?
from confluent-kafka-go.
groyee
commented on May 13, 2024
My Kafka cluster is 3 physical machines. Each with 2 cores and 7GB memory.
Here is the load graphs from Azure on one of the machines. The other 2 has similar results. The graph shows the load for "today"



from confluent-kafka-go.
edenhill
commented on May 13, 2024
Are those 50MB spikes on the network chart your applications running?
You could try decreasing with queue.buffering.max.kbytes on the Producer, that's the internal producer queue's size limit. If you decrease that is your memory usage on the application decreasing as well?
And if so you should start seeing backpressure eventually when the ProduceChannel starts filling up (it has its own property go.produce.channel.size).
from confluent-kafka-go.
groyee
commented on May 13, 2024
I am not sure about the spikes. I don't really trust Azure metrics.
I reduced queue.buffering.max.kbytes from 4000000 to 40000.
The memory still grows but much much slower. Still, I believe if I leave it running like that for tonight it won't survive.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
I think you need to find out if it ever stops increasing, if it does then it is most likely various internal queues (and channels) filling up to their max thresholds.
If it wont stop increasing that means there is a leak which is by 99% chance in the Go code somewhere (be it your app or the Kafka Go bindings). There are memory leak detectors available for Go to help out.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
During find-where-my-memory-is-going-testing you probably want to decrease queued.max.messages.kbytes on the consumer, it defaults to 1GB
from confluent-kafka-go.
 liubin
commented on May 13, 2024
liubin
commented on May 13, 2024
Maybe out of topic, but not completely.
I have an app that receive user data from HTTP and send it as a message to kafka. I have the same issue before, after read this issue, I found that the problem is that I'm not using this library correctly.
Not like other libraries that has a SyncProducer that we can use it send message with a traditional functional way ant get the produce result with the return with but not the golang's way that read result from another chan or something else.
Using confluent-kafka-go to produce an one time message, I should have to set queue.buffering.max.ms to a small value for a fast response, or I will get a 1000ms+ lantency. As a basic user, I would have an API that simple and direct to use like samara or kafka-python.
from confluent-kafka-go.
edenhill
commented on May 13, 2024
@groyee Any luck?
from confluent-kafka-go.
 rajeshmag
commented on May 13, 2024
rajeshmag
commented on May 13, 2024
@maeglindeveloper @groyee Were you able to find the root cause, I have same problem
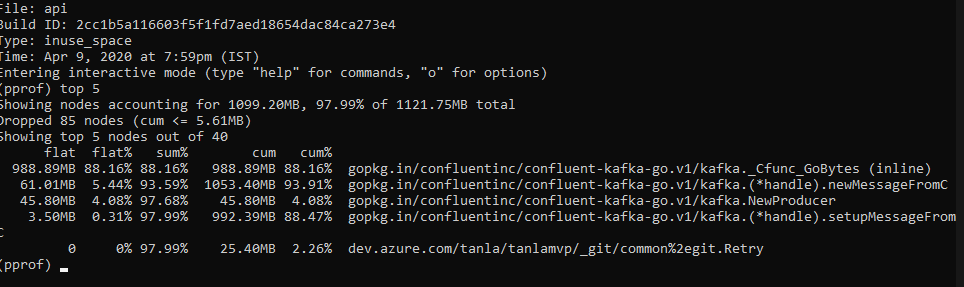
from confluent-kafka-go.
edenhill
commented on May 13, 2024
@rajeshmag Are you reading delivery report Message's from the Events() channel?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
Could this be an issue with slow scheduling, namely that the Events channel writer go-routine does not get scheduled often enough?
What is the CPU load for the application and system load?
Is GOMAXPROCS limited?
How many cores/vcpu does the instance/machine have?
Or is it perhaps the GC that is not running fast enough?
Can you try forcing a GC every now and then to see if it sorts out the issue?
from confluent-kafka-go.
edenhill
commented on May 13, 2024
eh-steve: you removed your comment, did you find the issue?
from confluent-kafka-go.
 eh-steve
commented on May 13, 2024
eh-steve
commented on May 13, 2024
It turned out I had something else downstream slowing down the event channel loop - when I removed it and kept the loop tight/unblocked, the performance shot back up - this was my mistake
from confluent-kafka-go.
rajeshmag
commented on May 13, 2024
@liubin The problem with these simple sync interfaces is that it tricks new developers into not thinking about what happens when the network starts acting up, broker becoming slow, etc.
A sync interface will work okay as long as the latency is low and there are no problems, but as soon as a produce request can't be immediately served the application will hang, possibly backpressuring its input source. This might be okay in some situations, and it is easy enough to wrap the async produce interface to make it sync (temporary delivery channel + blocking read on that channel after Produce()), but for most situations it is more important to maintain some degree of throughput and not stall the calling application.There's some more information here:
https://github.com/edenhill/librdkafka/wiki/FAQ#why-is-there-no-sync-produce-interfaceAnd here's an example how to make a sync produce call:
drChan := make(chan Event, 1) err := p.Produce(&Message{ TopicPartition: TopicPartition{Topic: &topic, Partition: -1}, Value: []byte(value), drChan) if err != nil { Fatalf("Produce: %v", err) } // Wait for delivery ev := <-drChan m := ev.(*Message) if m.TopicPartition.Error != nil { fmt.Printf("Delivery failed: %v", m.TopicPartition) } fmt.Printf("Produced message to %v", m.TopicPartition)
@edenhill Using channel actually solved the problem. Thank you for the explanation.
from confluent-kafka-go.
Related Issues (20)
- [schema registry] - unsupported protocol scheme HOT 1
- admin.AlterConsumerGroupOffsets not working for existing consumer group with multiple topics HOT 8
- runc package is not updated in the go.mod file HOT 4
- pprof shows cpu usage hotspot
- flame graph shows hotspot for reading from producer events
- Extremely slow protobuf deserialization and serialization for schema registry HOT 5
- malformed DWARF TagVariable entry HOT 5
- [Knowledge gathering question] How does librdkafka creates and sends batches over the network to the broker? HOT 2
- Do we really need the `default case` in the consumer for loop
- Can't statically build binary with vendored library on arm64 musl HOT 2
- Multiple schema registry URLs does not seem to be supported
- Serialisation poor performance due to a lack of schema caching HOT 1
- Work with go gin error HOT 5
- Build and run binary return code 137 HOT 3
- What's the difference between `producer.Events()` chan and `deliverChan` HOT 2
- Add error handling for SubscribeTopics function call in consumer_example.go
- High memory usage with the `kafka.consumer`
- Increased memory usage with GetMetadata call
- Build fails on arm64 architecture HOT 1
- Feature Request: Support to specify `RecordNameStrategy`
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from confluent-kafka-go.