Comments (30)
 biubug6
commented on May 23, 2024
2
biubug6
commented on May 23, 2024
2
retinaface forward : net forward time: 0.00583s on GTX1070 (1024683)
faceboxes forward : net forward time: 0.00404s on GTX1070 (1024683)
Obviously, Retinaface mobilenet0.25 is far better than Faceboxes although Faceboxes is faster 1.83ms than Retinaface mobilenet0.25.
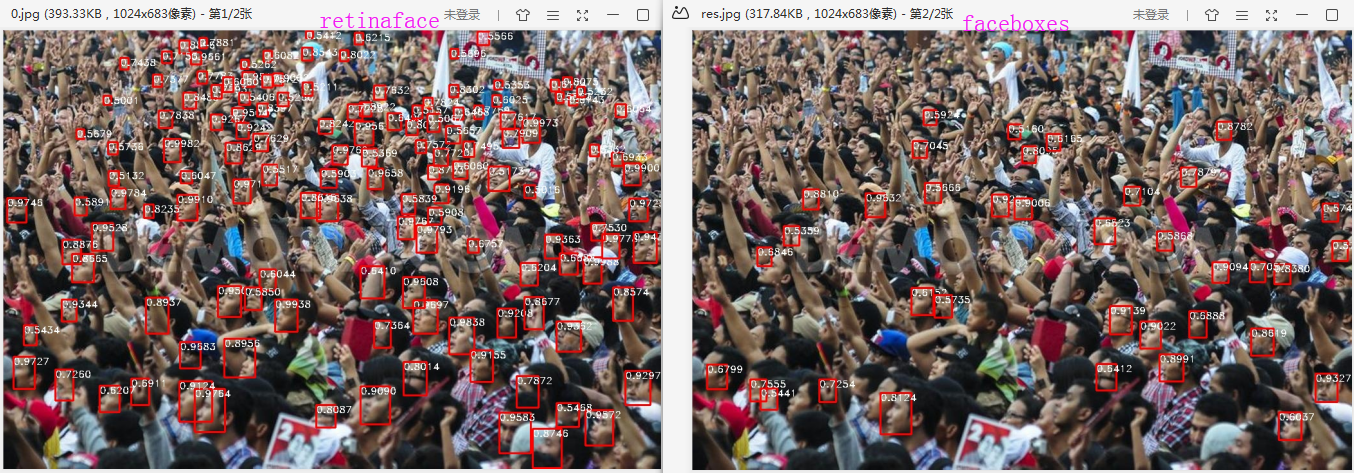
from pytorch_retinaface.
 xsacha
commented on May 23, 2024
1
xsacha
commented on May 23, 2024
1
I get same speed as you with that test.jpg image @biubug6 because it is quite a lot smaller than the images I was using.
RetinaFace
net forward time: 0.0056
net forward time: 0.0056
net forward time: 0.0056
I changed the script to use Faceboxes (most code was the same, just some imports and I removed landmarks:
FaceBoxes
net forward time: 0.0038
net forward time: 0.0038
net forward time: 0.0038
Not that much faster here because we are not using JIT.
Now we enable JIT as we would do for real inferencing:
net = torch.jit.trace(net, torch.randn(1, 3, 1024, 768).to(device))
RetinaFace
net forward time: 0.0036
net forward time: 0.0037
net forward time: 0.0036
FaceBoxes
net forward time: 0.0022
net forward time: 0.0022
net forward time: 0.0022
Both decrease about the same amount now.
I think it may be because the PASCAL test included the loading overhead in the average times. Anyway, looks a lot better now!
from pytorch_retinaface.
biubug6
commented on May 23, 2024
im_detect: 3211/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3212/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3213/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3214/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3215/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3216/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3217/3226 forward_pass_time: 0.0569s misc: 0.1084s
im_detect: 3218/3226 forward_pass_time: 0.0569s misc: 0.1085s
im_detect: 3219/3226 forward_pass_time: 0.0569s misc: 0.1085s
im_detect: 3220/3226 forward_pass_time: 0.0569s misc: 0.1085s
im_detect: 3221/3226 forward_pass_time: 0.0568s misc: 0.1085s
im_detect: 3222/3226 forward_pass_time: 0.0568s misc: 0.1086s
im_detect: 3223/3226 forward_pass_time: 0.0568s misc: 0.1086s
im_detect: 3224/3226 forward_pass_time: 0.0568s misc: 0.1086s
im_detect: 3225/3226 forward_pass_time: 0.0568s misc: 0.1087s
im_detect: 3226/3226 forward_pass_time: 0.0568s misc: 0.1087s
Initially the calculation was not very stable. In evaluate widerface val, Forward takes only 56.8ms on average using origin size. Postprocessing may waste some time, you can create priors boxes only once to accelerate Postprocessing.
from pytorch_retinaface.
biubug6
commented on May 23, 2024
I get log on GTX1080ti as above.
from pytorch_retinaface.
 lucasjinreal
commented on May 23, 2024
lucasjinreal
commented on May 23, 2024
tic = time.time()
loc, conf, landms = net(img) # forward pass
print('net forward time: {}'.format(time.time() - tic))
net forward time: 0.922250509262085
net forward time: 0.3259763717651367
net forward time: 0.3941810131072998
net forward time: 0.4199647903442383
net forward time: 0.3148021697998047
net forward time: 0.05451512336730957
net forward time: 0.21955442428588867
I tested on device GPU GTX1080ti
Python 3.5.2 (default, Jul 10 2019, 11:58:48)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'1.3.0a0+a439521'
>>> torch.cuda.is_available()
True
>>>
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024

from pytorch_retinaface.
biubug6
commented on May 23, 2024
net forward time: 0.005970001220703125
net forward time: 0.005970954895019531
net forward time: 0.005937337875366211
net forward time: 0.005845308303833008
net forward time: 0.006110668182373047
net forward time: 0.006749153137207031
net forward time: 0.006240367889404297
I use the provided image and get 6ms on GTX1070 according to your statistics(
tic = time.time()
loc, conf, landms = net(img) # forward pass
print('net forward time: {}'.format(time.time() - tic)))
net forward time: 0.17733335494995117
net forward time: 0.23269867897033691
net forward time: 0.15309405326843262
net forward time: 0.12016415596008301
This is the log on CPU.
Thus, you may have done something wrong.
from pytorch_retinaface.
biubug6
commented on May 23, 2024

from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024

I am also confused, I already converted model to device cuda and the GPU is actually occupied.
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024

I logged the input size, did you test under 3x smaller size than original size?
from pytorch_retinaface.
biubug6
commented on May 23, 2024
No, I alway use the original size. I suggest you try another environment of test. I get consistent result in two different environment.
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
I use another machine got same result:

All runs on cuda... I am running with pytorch1.3
from pytorch_retinaface.
biubug6
commented on May 23, 2024
You may use cpu inference. Please print args.
from pytorch_retinaface.
xsacha
commented on May 23, 2024
im_detect: 28/851 forward_pass_time: 0.0469s misc: 0.0119s
im_detect: 29/851 forward_pass_time: 0.0455s misc: 0.0118s
im_detect: 30/851 forward_pass_time: 0.0442s misc: 0.0118s
~40ms on Titan V.
FaceBoxes is about 10ms in same conditions (without JIT).
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
Oh, why I got slower speed on GPU than CPU...
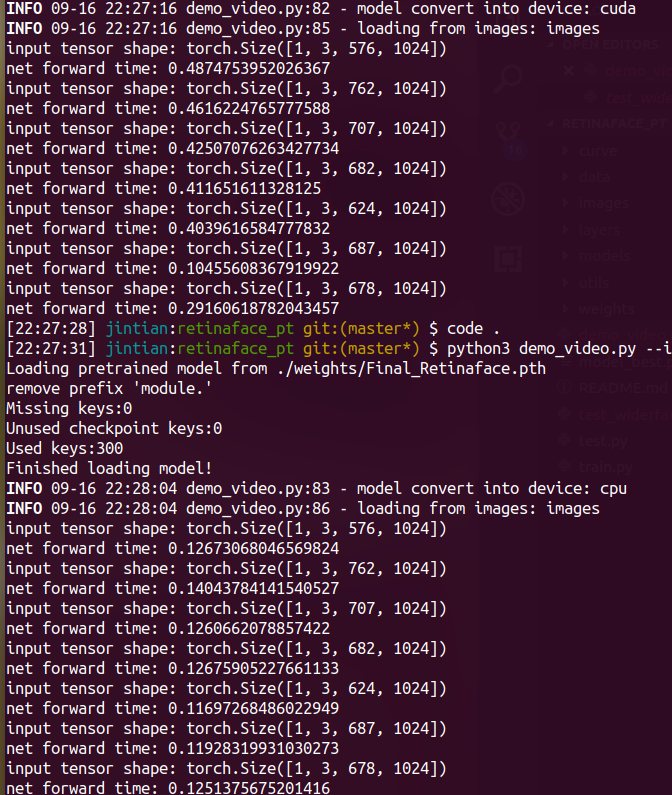
it's that caused by mobilenet depth wise not sufficient on GPU?
from pytorch_retinaface.
xsacha
commented on May 23, 2024
retinaface forward : net forward time: 0.00583s on GTX1070 (1024_683) faceboxes forward : net forward time: 0.00404s on GTX1070 (1024_683)
Obviously, Retinaface mobilenet0.25 is far better than Faceboxes although Faceboxes is faster 1.83ms than Retinaface mobilenet0.25.
How do you get it so much faster? 10x faster?
I'm using released PyTorch 1.2.0.
I can get same results as retinaface with 3 scales of FaceBoxes (minus the landmarks). For my usage, I usually know what scale I am looking for so I am interested in the comparison.
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
I can not reproduce the 4ms speed, instead, I got 400ms:
import os
import sys
import os
import argparse
import torch
import torch.backends.cudnn as cudnn
import numpy as np
from data import cfg
from layers.functions.prior_box import PriorBox
from utils.nms.py_cpu_nms import py_cpu_nms
import cv2
from models.retinaface import RetinaFace
from utils.box_utils import decode
from alfred.utils.log import logger as logging
from alfred.dl.torch.common import device
import glob
import time
force_cpu = False
if force_cpu:
device = torch.device('cpu')
parser = argparse.ArgumentParser(description='Retinaface')
parser.add_argument('-m', '--trained_model', default='./weights/Final_Retinaface.pth',
type=str, help='Trained state_dict file path to open')
parser.add_argument('--origin_size', default=True, type=str,
help='Whether use origin image size to evaluate')
parser.add_argument('--img_folder', default='./images/',
type=str, help='dataset path')
parser.add_argument('--confidence_threshold', default=0.02,
type=float, help='confidence_threshold')
parser.add_argument('--top_k', default=5000, type=int, help='top_k')
parser.add_argument('--nms_threshold', default=0.3,
type=float, help='nms_threshold')
parser.add_argument('--keep_top_k', default=750, type=int, help='keep_top_k')
parser.add_argument('-s', '--show_image', action="store_true",
default=True, help='show detection results')
parser.add_argument('--vis_thres', default=0.5, type=float,
help='visualization_threshold')
args = parser.parse_args()
def check_keys(model, pretrained_state_dict):
ckpt_keys = set(pretrained_state_dict.keys())
model_keys = set(model.state_dict().keys())
used_pretrained_keys = model_keys & ckpt_keys
unused_pretrained_keys = ckpt_keys - model_keys
missing_keys = model_keys - ckpt_keys
print('Missing keys:{}'.format(len(missing_keys)))
print('Unused checkpoint keys:{}'.format(len(unused_pretrained_keys)))
print('Used keys:{}'.format(len(used_pretrained_keys)))
assert len(used_pretrained_keys) > 0, 'load NONE from pretrained checkpoint'
return True
def remove_prefix(state_dict, prefix):
''' Old style model is stored with all names of parameters sharing common prefix 'module.' '''
print('remove prefix \'{}\''.format(prefix))
def f(x): return x.split(prefix, 1)[-1] if x.startswith(prefix) else x
return {f(key): value for key, value in state_dict.items()}
def load_model(model, pretrained_path):
print('Loading pretrained model from {}'.format(pretrained_path))
pretrained_dict = torch.load(pretrained_path,
map_location=lambda storage, loc: storage if force_cpu else storage.cuda(device))
if "state_dict" in pretrained_dict.keys():
pretrained_dict = remove_prefix(
pretrained_dict['state_dict'], 'module.')
else:
pretrained_dict = remove_prefix(pretrained_dict, 'module.')
check_keys(model, pretrained_dict)
model.load_state_dict(pretrained_dict, strict=False)
return model
if __name__ == '__main__':
torch.set_grad_enabled(False)
# net and model
net = RetinaFace(phase='test')
net = load_model(net, args.trained_model)
net.eval()
print('Finished loading model!')
cudnn.benchmark = True
net = net.to(device)
logging.info('model convert into device: {}'.format(device))
img_folder = args.img_folder
logging.info('loading from images: {}'.format(img_folder))
all_imgs = glob.glob(os.path.join(img_folder, '*.jpg'))
# testing begin
for i, img_f in enumerate(all_imgs):
img_raw = cv2.imread(img_f, cv2.IMREAD_COLOR)
img = np.float32(img_raw)
# testing scale
target_size = 1600
max_size = 2150
im_shape = img.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
resize = float(target_size) / float(im_size_min)
# prevent bigger axis from being more than max_size:
if np.round(resize * im_size_max) > max_size:
resize = float(max_size) / float(im_size_max)
if args.origin_size:
resize = 1
if resize != 1:
img = cv2.resize(img, None, None, fx=resize,
fy=resize, interpolation=cv2.INTER_LINEAR)
im_height, im_width, _ = img.shape
scale = torch.Tensor(
[img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
img -= (104, 117, 123)
img = img.transpose(2, 0, 1)
img = torch.from_numpy(img).unsqueeze(0)
img = img.to(device)
scale = scale.to(device)
print('input tensor shape: {}'.format(img.size()))
tic = time.time()
loc, conf, landms = net(img) # forward pass
print('net forward time: {}'.format(time.time() - tic))
priorbox = PriorBox(cfg, image_size=(im_height, im_width))
priors = priorbox.forward()
priors = priors.to(device)
prior_data = priors.data
boxes = decode(loc.data.squeeze(0), prior_data, cfg['variance'])
boxes = boxes * scale / resize
boxes = boxes.cpu().numpy()
scores = conf.squeeze(0).data.cpu().numpy()[:, 1]
# ignore low scores
inds = np.where(scores > args.confidence_threshold)[0]
boxes = boxes[inds]
scores = scores[inds]
# keep top-K before NMS
order = scores.argsort()[::-1][:args.top_k]
boxes = boxes[order]
scores = scores[order]
# do NMS
dets = np.hstack((boxes, scores[:, np.newaxis])).astype(
np.float32, copy=False)
keep = py_cpu_nms(dets, args.nms_threshold)
dets = dets[keep, :]
# keep top-K faster NMS
dets = dets[:args.keep_top_k, :]
# show image
if args.show_image:
for b in dets:
if b[4] < args.vis_thres:
continue
text = "{:.4f}".format(b[4])
b = list(map(int, b))
cv2.rectangle(img_raw, (b[0], b[1]),
(b[2], b[3]), (0, 0, 255), 2)
cx = b[0]
cy = b[1] + 12
cv2.putText(img_raw, text, (cx, cy),
cv2.FONT_HERSHEY_DUPLEX, 0.5, (255, 255, 255))
cv2.imshow("res", img_raw)
cv2.waitKey(0)Does any mistake in my inference scripts?
for anyone want test:
sudo pip3 install alfred-py
from pytorch_retinaface.
biubug6
commented on May 23, 2024
@jinfagang I'll test your scripts later. @xsacha I just modify "test.py or test_widerface.py" in order to test single image. Faceboxs with 3 scales is far slower than Retinaface. In the same performance case, Retinaface can set smaller input scales in order to get faster speed than Faceboxes.
from pytorch_retinaface.
xsacha
commented on May 23, 2024
@biubug6
You mean downscale the image to increase min face size right? This is why I am interested in retinaface (speed + landmarks).
I just can't replicate the speed right now.
Which version of pytorch do you use?
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
@xsacha Neither do I.
from pytorch_retinaface.
xsacha
commented on May 23, 2024
For me the Faceboxes implementation seems a lot faster:
As-is:
im_detect: 850/851 forward_pass_time: 0.0093s misc: 0.0182s
im_detect: 851/851 forward_pass_time: 0.0093s misc: 0.0182s
With JIT:
im_detect: 850/851 forward_pass_time: 0.0025s misc: 0.0181s
im_detect: 851/851 forward_pass_time: 0.0025s misc: 0.0181s
2.5ms for faceboxes (single pass at image resolution on PASCAL)
So I'm trying to investigate and improve the RetinaFace implementation.
First I traced the module and ran that in the test just like the Faceboxes method
net = torch.jit.trace(net, torch.randn(1, 3, 1024, 768).to(device))
im_detect: 850/851 forward_pass_time: 0.0139s misc: 0.0115s
im_detect: 851/851 forward_pass_time: 0.0138s misc: 0.0115s
14ms as JIT. Still 5 times slower than FaceBoxes!
Then I tried changing inplace=True to inplace=False in mobilenetv1.py as this makes a difference in Faceboxes. It made things worse for Retinaface.
I think maybe you have not investigated JIT (even though probably everyone should be using this for inference!). There seems to be something stopping this implementation from JIT fusion in CUDA.
I noticed faceboxes uses padding for the conv2d but retinaface doesn't.
from pytorch_retinaface.
biubug6
commented on May 23, 2024
@jinfagang I have tested the script, get result as follows:
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.005236625671386719
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.0052373409271240234
I also provided "detect.py" to test single image, get result as follows:
net forward time: 0.0051
net forward time: 0.0052
net forward time: 0.0052
net forward time: 0.0052
@xsacha In order to prevent the special environment, I reconfigured the environment today.
Pytorch: '1.2.0'
torchvision: '0.4.0'
cuda: V10.0.130
cudnn: 7.5
Ubuntu18.04
Hope to help you!
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
I think we might haven't try on same images. I still got massive gap between speed.
my gpu:
input tensor shape: torch.Size([1, 3, 576, 1024])
net forward time: 1.0079078674316406
input tensor shape: torch.Size([1, 3, 762, 1024])
net forward time: 0.32000184059143066
input tensor shape: torch.Size([1, 3, 707, 1024])
net forward time: 0.32289743423461914
input tensor shape: torch.Size([1, 3, 682, 1024])
net forward time: 0.3182847499847412
input tensor shape: torch.Size([1, 3, 624, 1024])
net forward time: 0.3084907531738281
input tensor shape: torch.Size([1, 3, 687, 1024])
net forward time: 0.04165768623352051
input tensor shape: torch.Size([1, 3, 678, 1024])
net forward time: 0.21609711647033691
my cpu:
input tensor shape: torch.Size([1, 3, 576, 1024])
net forward time: 0.7863352298736572
input tensor shape: torch.Size([1, 3, 762, 1024])
net forward time: 1.0068113803863525
input tensor shape: torch.Size([1, 3, 707, 1024])
net forward time: 0.6972379684448242
input tensor shape: torch.Size([1, 3, 682, 1024])
net forward time: 0.7851715087890625
input tensor shape: torch.Size([1, 3, 624, 1024])
net forward time: 0.8449158668518066
input tensor shape: torch.Size([1, 3, 687, 1024])
net forward time: 0.5640389919281006
input tensor shape: torch.Size([1, 3, 678, 1024])
net forward time: 0.8343081474304199
Would u test on these original images with my script? my hardware is GTX1080TI
from pytorch_retinaface.
biubug6
commented on May 23, 2024
@jinfagang I have test your script and use the image you provided earlier .The results were shown yesterday.
My hardware is GTX1070.
Please try "detect.py" or change another image in "detect.py".
from pytorch_retinaface.
 guoguangchao
commented on May 23, 2024
guoguangchao
commented on May 23, 2024
I also had a speed problem,when i run
python test_widerface.py --trained_model weights/Final_Retinaface.pth,
i got the result:
im_detect: 1/8 forward_pass_time: 1.5574s misc: 0.0718s
im_detect: 2/8 forward_pass_time: 1.4758s misc: 0.0609s
im_detect: 3/8 forward_pass_time: 1.4783s misc: 0.0620s
im_detect: 4/8 forward_pass_time: 1.3588s misc: 0.0699s
im_detect: 5/8 forward_pass_time: 1.4008s misc: 0.0877s
im_detect: 6/8 forward_pass_time: 1.5435s misc: 0.0933s
im_detect: 7/8 forward_pass_time: 1.4758s misc: 0.0891s
im_detect: 8/8 forward_pass_time: 1.4809s misc: 0.0857s
my hardware is GTX960m, and the GPU is used
but when i run
python detect.py,
i got the result:
net forward time: 0.0060
net forward time: 0.0059
net forward time: 0.0059
net forward time: 0.0060
net forward time: 0.0061
net forward time: 0.0059
net forward time: 0.0062
net forward time: 0.0060
net forward time: 0.0059
net forward time: 0.0060
net forward time: 0.0060
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
I tested author new detect.py, the speed is now same as him.
but still, a gap in detect.py and my_script. my scripts is changes from test.py. the original time doesn't change. I don't know why.
In spite of this, This is the fastest face detection as far as I tried (with lanmarks output). I have a TensorRT version can achieves more than 400 fps for real (include the whole process time).
from pytorch_retinaface.
 siyiding1216
commented on May 23, 2024
siyiding1216
commented on May 23, 2024
@jinfagang
Will it possible for you to share your tensorRT verison?
from pytorch_retinaface.
lucasjinreal
commented on May 23, 2024
@siyiding1216 It's private, but you can join our community to obtain the code, my wechat: jintianiloveu
from pytorch_retinaface.
 Govan111
commented on May 23, 2024
Govan111
commented on May 23, 2024
@jinfagang I have tested the script, get result as follows:
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.005236625671386719
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.0052373409271240234I also provided "detect.py" to test single image, get result as follows:
net forward time: 0.0051
net forward time: 0.0052
net forward time: 0.0052
net forward time: 0.0052
@xsacha In order to prevent the special environment, I reconfigured the environment today.
Pytorch: '1.2.0'
torchvision: '0.4.0'
cuda: V10.0.130
cudnn: 7.5
Ubuntu18.04
Hope to help you!
Your calculation method of model inference time is not accurate. Because GPU computing is asynchronous, the inference time is actually much longer than 5ms. You can test as below:
torch.cuda.synchronize()
t2 = time.time()
loc, conf, landms = self.net(img) # forward pass
torch.cuda.synchronize()
t3 = time.time()
print('net forward time: {}'.format(t3 - t2))
from pytorch_retinaface.
 iPrayerr
commented on May 23, 2024
iPrayerr
commented on May 23, 2024
@jinfagang I have tested the script, get result as follows:
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.005236625671386719
input tensor shape: torch.Size([1, 3, 683, 1024])
net forward time: 0.0052373409271240234
I also provided "detect.py" to test single image, get result as follows:
net forward time: 0.0051
net forward time: 0.0052
net forward time: 0.0052
net forward time: 0.0052
@xsacha In order to prevent the special environment, I reconfigured the environment today.
Pytorch: '1.2.0'
torchvision: '0.4.0'
cuda: V10.0.130
cudnn: 7.5
Ubuntu18.04
Hope to help you!Your calculation method of model inference time is not accurate. Because GPU computing is asynchronous, the inference time is actually much longer than 5ms. You can test as below:
torch.cuda.synchronize()
t2 = time.time()
loc, conf, landms = self.net(img) # forward pass
torch.cuda.synchronize()
t3 = time.time()
print('net forward time: {}'.format(t3 - t2))
@Govan111 Thanks for your suggestion. So you mean that the longer inference time is the actual time and cannot be optimized by tricks? I wonder if you have any experience on such optimization.
from pytorch_retinaface.
Related Issues (20)
- Is it ok if we upload your models to Zenodo and distribute them?
- Fine-tuning Resnet 50 model
- Unable to find a compatible Visual Studio installation
- How to fit non-squared input?
- The form of bboxes is wrong!!!
- Mesh decoder HOT 1
- About the ratioHard Example Mining HOT 3
- Why can't we evaluate during the training? HOT 1
- Pretrained Model HOT 1
- [Refactor] Acclerate training based on MMEngine :rocket:
- How to train with custom dataset by using the pretrained model?
- Dataset
- Evaluation 评估失败,在widerface的三个子集上map值都为0 HOT 1
- What maximum FPS have you achieved?
- Why does the forward pass time become shorter with iterations?
- Why loop 100 times while testing begin in detect.py?
- 用celeba数据集训练的模型,摄像头测试时小脸的框会变大框不准 HOT 1
- How can I train using pth pretrained file? (For transfer learning)
- 用预训练的权重直接训练,为什么loss会这么高
- C++ and TensorRT implementation of yolov5face yolov7face yolov8face
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from pytorch_retinaface.