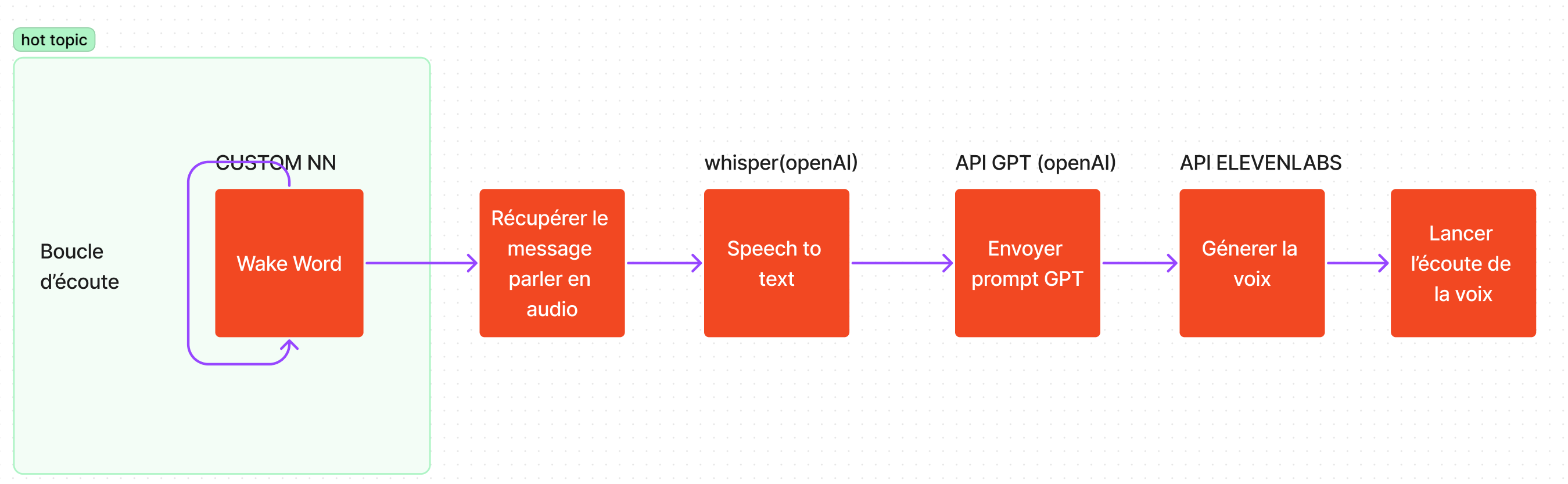
Bonjour,
Déjà merci pour ce beau projet, il est super cool et intéressant je trouve, cependant, j'ai pas réussi à le faire fonctionner, alors je viens demander un peu d'aide si c'est possible.
Les instructions manques beaucoup de screenshot, ou une vidéo ou tu installes tout sur un env de test de A à Z serait parfait et réglerez beaucoup des soucis d'installations des gens je pense.
Les "Une fois connecté, vous trouverez votre clé API dans le tableau de bord." en sont la preuve je trouve, typiquement pour les premières API à récupérer sur OPENAI, il y'en a 2 à fournir dans le .env il y'a la "OPENAI_API_KEY" et la "OPENAI_ORG" cependant, aucune mention d'ou trouver la "OPENAI_ORG", je l'ai laisser vide à défaut de trouver comment la remplir.
La ELEVENLAB_API_KEY elle est plutôt simple à trouver, mais la "ELEVENLAB_VOICE_ID" elle je l'ai un peu trouvé au pif, je suis aller dans la doc, sur l'api et sur cette url : https://api.elevenlabs.io/v1/voices et dedans j'ai ctrl+f la voix que j'utilise car c'est une premade, mais si c'est une voix généré qu'est-ce qu'on est censé faire ? Comment remplir la "ELEVENLAB_VOICE_ID" ?
Ensuite aucune explication sur "KEYWORD_PATH_PORCUPINE" ainsi que "MODEL_PATH_PROCUPINE", je suis parti du principe que c'était le path vers le .ppn mais je pense pas que le model soit bon, et il y'a une faute de frappe il y'a écrit "PROCUPINE" au lieu de "POPCUPINE" je sais pas si ça peut pas générer une erreur pour plus tard.
"Téléchargez les fichiers nécessaires et ajoutez-les à votre projet." Comment ? Et ensuite on les met dans un dossier de notre choix ? Si tout le monde doit les ajouter dans un dossier pourquoi ne pas faire un dossier "Ajouter_Voix_ici" de base ?
Concernant les voix à ajouter dans "voix_intro" aussi là manque de clarté, déjà je suis pas bien sûr de comprendre la phrase :
"Téléchargez ces voix et ajoutez-les manuellement à votre dossier 'voix_intro'." on parle des .mp3 qu'on fait pour s'amuser, on les DL et on les mets dans le dossier ? Car je n'ai jamais réussi à DL une "voix" au sens ou je DL un profil de voix, juste des extraits.
Et ensuite, c'est peut-être moi qui suit bête mais comment s'exécute le programme en fait ? Imaginons que j'ai rempli mon .env comme il faut, qu'est-ce que je fais ensuite ?
C'est peut-être moi qui suit bête comme mes pieds mais je trouve que le readme est pas clair du tout et c'est dommage j'aurai bien voulu utiliser cet outil pour mes streams
Merci d'avance pour la réponse